
Python使用zstd压缩算法
Facebook的Zstandard(简称zstd)压缩算法逐渐流行,它有以下特点:
1,压缩、解压速度快。
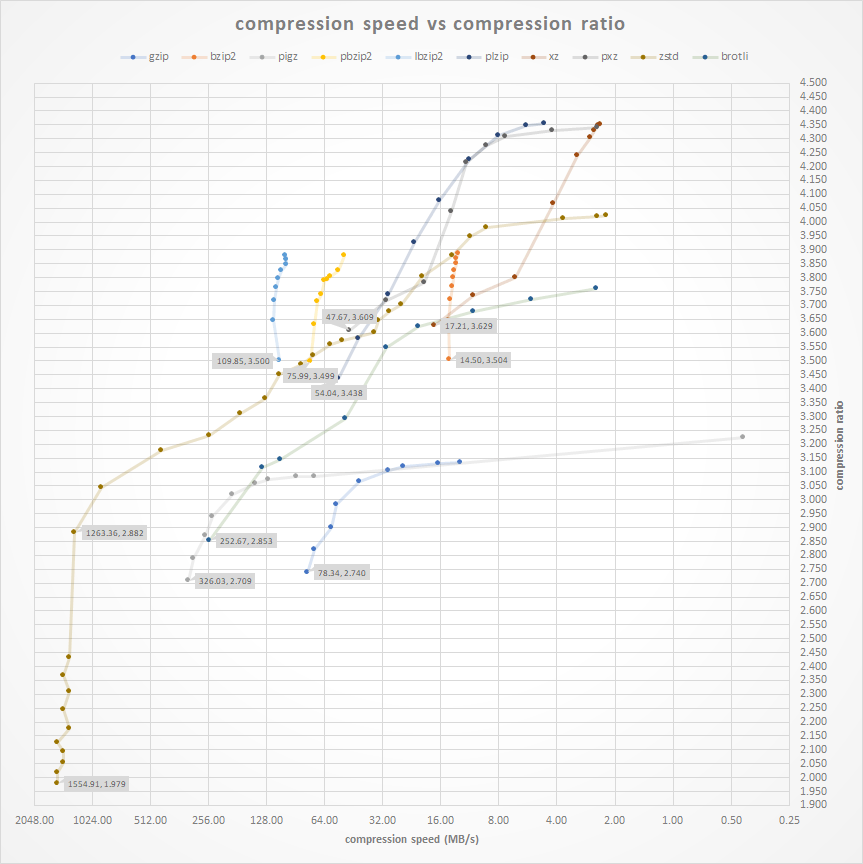
下图是单线程压缩的性能,横轴是压缩比,纵轴是压缩速度。
- 高压缩等级时,压缩比接近lzma。(但解压更快)
- 低压缩等级时,速度接近lz4。(zstd和lz4的作者是同一个人)
在各种情况下,性能比zlib好,可以考虑替代zlib。
图片出自这个网页,里面还有一些比较图表。

zstd自带多线程压缩,充分利用多核CPU,让压缩速度提升数倍。
原理是把数据 等分 成多份,并行压缩出一个单帧zstd数据,可以设置 每份的大小、重叠部分的大小。
多线程压缩可以用1秒把1GiB数据压缩到500MiB,网络传输会快很多。
但不支持多线程解压。不过解压速度已经很快了,低压缩等级时可以比一些SSD快。解压速度可以看zstd网站首页的表格。
2,如果使用预先训练的zstd字典,对于几KB的小数据,可以大大提高压缩比。
要压缩的数据越小,就越难压缩,这是所有压缩算法都有的问题,原因是压缩算法从之前的数据中学习如何压缩之后的数据,但对于小数据,没有“之前”可以参考。
为了解决这一问题,zstd提供了训练模式,针对特定的数据类型训练字典。训练是通过提供一些样本(每个样本一个文件)来实现的,训练的结果(字典)存储在一个文件中,在压缩和解压之前必须加载该文件。
使用字典可以大大提高几KB的小数据的压缩比,对于1KB以下的小数据有最好效果。
下图是压缩1万条大约1KB的数据,在使用字典时,压缩比、压缩速度、解压速度大大提高。

注意:
- 如果丢失了字典,就不能解压相应的数据。
- 对于几MB的大数据,字典的效果微不足道。
除了用样本训练字典,还可以手工编写(或使用专用字典工具构建)一个更高效的字典,然后用一些样本完成(finalize)这个字典。
比如把JSON文件中的共有部分精心挑选出来,写到一个文件里,然后用一些JSON样本完成(finalize)这个字典,这样得到的字典可能比用样本训练的字典更高效。
3,帧(frame)和块(block)让使用更灵活,适合各种场景。
zstd数据由1个或多个独立的帧(frame)组成,解压后的多帧数据 等于 每帧解压后再相接。
每帧完全独立,包括一个帧头,以及一套解压参数。
zlib和lzma也有这样的多帧特性。
每帧包括1个或多个块(block),块的尺寸上限是3字节块头+128KB,块的实际最大尺寸取决于帧头里定义的参数。
和完全独立的帧不同,在解压时,块依赖之前的块、不依赖之后的块,完整的块可以被全部解压。所以flush块可以用于通讯场景,接收方可以立刻解压。
zlib也有类似块的特性。
4,zstd可用作“补丁引擎”
在作为补丁引擎时,就像生成diff、并对其压缩。
- 生成补丁:(VER1 + VER2) -> PATCH
- 打补丁:(VER1 + PATCH) -> VER2
生成补丁的过程使用zstd用于压缩的匹配查找器,性能(速度、补丁大小)可以和专业补丁引擎相比。打补丁(解压)的速度比专业补丁引擎快。
见此文:https://github.com/facebook/zstd/wiki/Zstandard-as-a-patching-engine
Python使用zstd压缩算法
用了几个月时间,写了一个pyzstd模块,它的API和Python标准库中的bz2/lzma/zlib模块相似。
PyPI页面:https://pypi.org/project/pyzstd/
文档(英文):https://pyzstd.readthedocs.io/en/latest/
GitHub页面:https://github.com/animalize/pyzstd
PyPI上还有两个zstd模块:
zstd:它太简单了,只提供很少的基本功能。
zstandard:提供了丰富的API,但是API风格和Python标准库的bz2/lzma/zlib不同。
zstd杂谈
1, 上面提到:在高压缩等级时,压缩比接近lzma;在低压缩等级时,速度接近lz4。
可能有人好奇这是怎么做到的,这是因为zstd内部提供了几套压缩代码,适用于不同的压缩等级。(但格式是相同的)
缺点就是二进制代码很大,比较几种算法的DLL文件,zlib大约110KB,lzma大约150KB,bz2大约80KB,zstd达450KB。
不过zstd的二进制代码可以裁剪,以下三种功能可以按需留取:压缩、解压、训练字典。压缩中的多线程压缩也是可裁剪的。
比如一个APP只需要解压zstd数据,可以只编译解压代码,编译后的解压可执行代码仅40~70KB。
2, zstd的核心代码考虑了乱序执行,v1.5使用SIMD(SSE2或Neon),感觉比较“现代”。
3, zstd的C代码大量使用常量传播(constant propagation),更智能的编译器会有更好的内联优化。
似乎MSVC在这方面较弱,见此文,文中说MSVC会进行改进。目前(2021年1月)MSVC编译的比GCC编译的慢6%~10%。
zstd代码可能也会针对MSVC做些调整。
4, 近来一些库重写了DEFLATE算法,比如libdeflate、ISA-L,可以将gzip的压缩速度、解压速度提升到zstd的级别。
也许zstd不会替代lzma,lzma能有更高的压缩比。
相比lzma,zstd有更快的解压速度,见Linux内核、Arch Linux的报道。
5, 最后贴一张2019年11月做的性能比较。
zstd还处于活跃的开发中(现在是2021年),每个版本可能会有少量性能提升。
zlib/bz2/lzma,这些库有的已经很久没有实质更新,有的更新缓慢(只有一个人在开发)。
zstd小组好像有4个员工,还有一些贡献者参与,很活跃。
活跃的负面效果是可能引入少量边缘性的bug,可以看更新日志了解一下,基本不会影响数据安全。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号