

10第十一天JDBC事务控制管理
create database day11;use day11;create table account (id int primary key auto_increment,name varchar(20),money double);insert into account values(null,'a',1000),(null,'b',1000);
一、事务
1、事务的概念:事务是指逻辑上的一组操作,这组操作要么同时完成要么同时不完成。
2、 事务的管理:默认情况下,数据库会自动管理事务,管理的方式是一条语句就独占一个事务.
如果需要自己控制事务也可以通过如下命令开启/提交/回滚事务
start transaction; 开启事务
commit; 提交事务
rollback; 回滚事务 还原执行一句sql命令之前状态。
eg:A——B转帐,对应于如下两条sql语句
mysql> select * from account;+----+------+-------+| id | name | money |+----+------+-------+| 1 | a | 1000 || 2 | b | 1000 |+----+------+-------+
update account set money=money-100 where name=‘a’;
update account set money=money+100 where name=‘b’;
如果第二句话未执行,数据库崩溃了,变成:
mysql> select * from account;+----+------+-------+| id | name | money |+----+------+-------+| 1 | a | 900 || 2 | b | 1000 |+----+------+-------+
使用start transaction; 进入事务中,若在事务中执行第一句,事务中内容发生改变,而再次其他窗口进入数据库,发现数据库内容未变。只有commit;提交事务后才会改变数据库。
3、当Jdbc程序向数据库获得一个Connection对象时,默认情况下这个Connection对象会自动向数据库提交在它上面发送的SQL语句。若想关闭这种默认提交方式,让多条SQL在一个事务中执行,可使用下列语句:
JDBC中管理事务:
conn.setAutoCommit(false); 设置为不自动提交事务,作为同一个事务
conn.commit();
conn.rollback();
//设置事务回滚点
SavePoint sp = conn.setSavePoint();
conn.rollback(sp);
conn.commit();//回滚后必须要提交
package com.lmd.transaction;import java.sql.Connection/PreparedStatement/ResultSet;import java.sql.SQLException/Savepoint;import com.lmd.util.JDBCUtils;public class JDBCTranDemo {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;Savepoint sp = null;try {conn = JDBCUtils.getConn();conn.setAutoCommit(false);//第一次转账ps = conn.prepareStatement("update account set money=money-100 where name=?");ps.setString(1, "a");ps.executeUpdate();//int i = 1/0;ps = conn.prepareStatement("update account set money=money+100 where name=?");ps.setString(1, "b");ps.executeUpdate();//第二次转账,若此次出异常,为了保存第一次转账,//可以在此处设置一个回滚点sp = conn.setSavepoint();ps = conn.prepareStatement("update account set money=money-100 where name=?");ps.setString(1, "a");ps.executeUpdate();//此处遇到异常,执行回滚操作String s = null;s.toUpperCase();ps = conn.prepareStatement("update account set money=money+100 where name=?");ps.setString(1, "b");ps.executeUpdate();conn.commit();} catch (Exception e) {try {//前面运行出异常,进入回滚if (sp == null) {conn.rollback();} else {//不是null,回滚到回滚点conn.rollback(sp);conn.commit();}} catch (SQLException e1) {e1.printStackTrace();}e.printStackTrace();} finally {JDBCUtils.close(rs, ps, conn);}}}
3、!!!事务的四大特性:一个事务具有的最基本的特性,一个设计良好的数据库可以帮我们保证事务具有这四大特性(ACID):
(1)、 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
(2)、 一致性(Consistency):如果事务执行之前数据库是一个完整性的状态,那么事务结束后,无论事务是否执行成功,数据库仍然是一个完整性状态.。
数据库的完整性状态:当一个数据库中的所有的数据都符合数据库中所定义的所有的约束,此时可以称数据库是一个完整性状态.
(3)、 隔离性(Isolation):事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。
(4)、 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
4、隔离性详解
(1)、将数据库设计成单线程的数据库,可以防止所有的线程安全问题,自然就保证了隔离性。但是如果数据库设计成这样,那么效率就会极其低下。
如果是两个线程并发修改,一定会互相捣乱,这时必须利用锁机制防止多个线程的并发修改。
如果两个线程并发查询,没有线程安全问题。
如果两个线程一个修改,一个查询......有些场景有问题,有些没有。如下:
如果不考虑隔离性,可能会引发如下问题:
1)、脏读:一个事务读取到另一个事务未提交的数据。
2)、不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同 --- 行级别的问题。
3)、虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致 --- 表级别的问题。
1)、脏读:一个事务读取到另一个事务未提交的数据
a 1000b 1000----------a:start transaction;update account set money=money-100 where name=a;update account set money=money+100 where name=b;----------b:start transaction;select * from account;a : 900b : 1100----------a:rollback;----------b:start transaction;select* from account;a: 1000b: 1000
2)、不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同 --- 行级别的问题
和脏读的区别是,脏读是读取前一事务未提交的脏数据,不可重复读是重新读取了前一事务已提交的数据。
a: 1000 1000 1000b: 银行职员---------b:start transaction;select 活期存款 from account where name='a'; ---- 活期存款:1000select 定期存款 from account where name='a'; ---- 定期存款:1000select 固定资产 from account where name='a'; ---- 固定资产:1000-------a:start transaction;update accounset set 活期=活期-1000 where name='a';commit;-------select 活期+定期+固定 from account where name='a'; --- 总资产:2000commit;----------
3)、虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致 --- 表级别的问题
a: 1000b: 1000d: 银行业务人员-----------d:start transaction;select sum(money) from account; --- 2000 元select count(name) from account; --- 2 个------c:start transaction;insert into account values(c,4000);commit;------select sum(money)/count(name) from account; --- 平均:2000元/个commit;------------
5、set [global/session] transaction isolation level 设置事务隔离级别
select @@tx_isolation 查询当前事务隔离级别
四大隔离级别:
read uncommitted -- 不防止任何隔离性问题,具有脏读/不可重复度/虚读(幻读)问题
read committed -- 可以防止脏读问题,但是不能防止不可重复度/虚读(幻读)问题
repeatable read -- 可以防止脏读/不可重复读问题,但是不能防止虚读(幻读)问题
serializable -- 数据库被设计为单线程数据库,可以防止上述所有问题,但效率低下
从安全性上考虑:Serializable>Repeatable read>read committed>read uncommitted
从效率上考虑:read uncommitted>read committed>Repeatable read>Serializable
真正使用数据的时候,根据自己使用数据库的需求,综合分析对安全性和对效率的要求,选择一个隔离级别使数据库运行在这个隔离级别上。
mysql 默认下就是Repeatable read隔离级别
oracle 默认下就是read committed个隔离级别
查询当前数据库的隔离级别:select @@tx_isolation;
设置隔离级别:set [global/session] transaction isolation level xxxx;
其中如果不写默认是session指的是修改当前客户端和数据库交互时的隔离级别;
而如果使用global,则修改的是数据库的默认隔离级别。
1.mysql -u root -p
2.set global transaction isolation level read uncommitted;
3.set transaction isolation level serializable;
4.select @@tx_isolation;
先打开一个cmd命令窗口,输入1、2和4回车,关闭;新打开两个窗口:
一个窗口输入1、4,如下1: 另一个窗口输入1、3,如下2:


模拟脏读: 在2中开启事务,改变数据,不提交;窗口1可以读取数据库改变后的数据;而窗口2进行回滚,窗口2又看到原始数据。
演示不同隔离级别下的并发问题set transaction isolation level 设置事务隔离级别select @@tx_isolation 查询当前事务隔离级别1.当把事务的隔离级别设置为read uncommitted时,会引发脏读、不可重复读和虚读- A窗口
set transaction isolation level read uncommitted;start transaction;select * from account;-----发现a帐户是1000元,转到b窗口- B窗口
start transaction;update account set money=money+100 where name='aaa';-----不要提交,转到a窗口查询select * from account-----发现a多了100元,这时候a读到了b未提交的数据(脏读)2.当把事务的隔离级别设置为read committed时,会引发不可重复读和虚读,但避免了脏读- A窗口
set transaction isolation level read committed;start transaction;select * from account;-----发现a帐户是1000元,转到b窗口B窗口start transaction;update account set money=money+100 where name='aaa';commit;-----转到a窗口
数据库中的锁机制:
共享锁:在非Serializable隔离级别做查询不加任何锁,而在Serializable隔离级别下做的查询加共享锁。
共享锁的特点:共享锁和共享锁可以共存,但是共享锁和排他锁不能共存
排他锁:在所有隔离级别下进行增删改的操作都会加排他锁,
排他锁的特点:和任意其他锁都不能共存

以上为更新丢失问题:
两个线程基于同一个查询结果进行修改,后修改的人会将先修改人的修改覆盖掉。(以下两种解决方案)
悲观锁:悲观锁悲观的认为每一次操作都会造成更新丢失问题,在每次查询时就加上排他锁。
select * from xxx for update;
乐观锁:乐观锁会乐观的认为每次查询都不会造成更新丢失,利用一个版本字段进行控制。
查询非常多,修改非常少,使用乐观锁
修改非常多,查询非常少,使用悲观锁

========================================================================================
二、数据库连接池


1、数据库连接池编写原理分析 连接池 数据源
(1)、编写连接池需实现javax.sql.DataSource接口。DataSource接口中定义了两个重载的getConnection方法:
Connection getConnection()
Connection getConnection(String username, String password)
(2)、实现DataSource接口,并实现连接池功能的步骤:
在DataSource构造函数中批量创建与数据库的连接,并把创建的连接保存到一个集合对象中
实现getConnection方法,让getConnection方法每次调用时,从集合对象中取一个Connection返回给用户。
当用户使用完Connection,调用Connection.close()方法时,Collection对象应保证将自己返回到连接池的集合对象中,而不要把conn还给数据库。
2、编写数据库连接池核心 (1)、扩展Connection的close方法
在关闭数据库连接时,将connection存回连接池中,而并非真正的关闭
(2)、扩展类的三种方式
基于继承--- 方法覆盖
使用装饰模式包装类,增强原有行为
使用动态代理 --- 基于字节码Class在内存中执行过程
手写连接池:
改造conn的close方法
继承
装饰
!动态代理
public class MyPool implements DataSource {private static List<Connection> pool = new LinkedList<Connection>();static{try {Class.forName("com.mysql.jdbc.Driver");for (int i = 0; i < 5; i++) {Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day11", "root", "666666");pool.add(conn);}} catch (Exception e) {e.printStackTrace();}}@Overridepublic Connection getConnection() throws SQLException {if (pool.size()==0) {for (int i = 0; i < 5; i++) {Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day11", "root", "666666");pool.add(conn);}}//return pool.remove(0);Connection conn = pool.remove(0);//--利用动态代理改造close方法Connection proxy = (Connection) Proxy.newProxyInstance(conn.getClass().getClassLoader(), conn.getClass().getInterfaces(), new InvocationHandler() {@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {if ("close".equals(method.getName())) {//想改造的方法,自己写returnConn(conn);return null;} else {//不想改造的方法,调用被代理者身上相同的方法return method.invoke(conn, args);}}});System.err.println("获取了一个连接,池里还剩余"+pool.size()+"个连接!");return proxy;}public void returnConn(Connection conn) {try {if (conn!=null && !conn.isClosed()) {pool.add(conn);System.out.println("返回了一个连接,池里还剩余"+pool.size()+"个连接!");}} catch (SQLException e) {e.printStackTrace();}}- //其他重写方法省写
- }
简陋版连接池:
import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;import com.lmd.pool.MyPool;public class JDBCDemo {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;MyPool pool = new MyPool();ResultSet rs = null;try {conn = pool.getConnection();ps = conn.prepareStatement("select * from account");rs = ps.executeQuery();while (rs.next()) {String name = rs.getString("name");System.out.println(name);}} catch (Exception e) {e.printStackTrace();} finally {if (rs!=null) {try {rs.close();} catch (SQLException e) {e.printStackTrace();} finally {rs = null;}}if (ps!=null) {try {ps.close();} catch (SQLException e) {e.printStackTrace();} finally {ps = null;}}if (conn!=null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();} finally {conn = null;}}}}}//获取了一个连接,池里还剩余4个连接!//a//b//c//返回了一个连接,池里还剩余5个连接!
三、开源数据库连接池(DataSource)
(1)、现在很多WEB服务器(Weblogic, WebSphere, Tomcat)都提供了DataSoruce的实现,即连接池的实现。通常我们把DataSource的实现,按其英文含义称之为数据源,数据源中都包含了数据库连接池的实现。
(2)、也有一些开源组织提供了数据源的独立实现:
DBCP 数据库连接池
C3P0 数据库连接池
Apache Tomcat内置的连接池(apache dbcp)
(3)、实际应用时不需要编写连接数据库代码,直接从数据源获得数据库的连接。程序员编程时也应尽量使用这些数据源的实现,以提升程序的数据库访问性能。
1、DBCP数据源
(1)、DBCP 是 Apache 软件基金组织下的开源连接池实现,使用DBCP数据源,应用程序应在系统中增加如下两个 jar 文件:
Commons-dbcp.jar:连接池的实现 commons-dbcp-1.4.jar
Commons-pool.jar:连接池实现的依赖库 commons-pool-1.5.6.jar
(2)、Tomcat 的连接池正是采用该连接池来实现的。该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
开源数据源:
DBCP:
方式1:
BasicDataSource source = new BasicDataSource();source.setDriverClassName("com.mysql.jdbc.Driver");source.setUrl("jdbc:mysql:///day11");source.setUsername("root");source.setPassword("root");conn = source.getConnection();
Properties prop = new Properties();prop.load(new FileReader("dbcp.properties"));BasicDataSourceFactory factory = new BasicDataSourceFactory();DataSource source = factory.createDataSource(prop);
配置文件中: 在java工程下
driverClassName=com.mysql.jdbc.Driverurl=jdbc:mysql:///day11username=rootpassword=666666
配置设置
#连接设置driverClassName=com.mysql.jdbc.Driverurl=jdbc:mysql://localhost:3306/jdbcusername=rootpassword=666666#<!-- 初始化连接 -->initialSize=10#最大连接数量maxActive=50#<!-- 最大空闲连接 -->maxIdle=20#<!-- 最小空闲连接 -->minIdle=5#<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 -->maxWait=60000#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;]#注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。connectionProperties=useUnicode=true;characterEncoding=gbk#指定由连接池所创建的连接的自动提交(auto-commit)状态。defaultAutoCommit=true#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLEdefaultTransactionIsolation=READ_UNCOMMITTED
2、C3P0数据源 c3p0-0.9.1.2.jar 这个要会用
C3P0数据源:
方式1:
ComboPooledDataSource source = new ComboPooledDataSource(["aaa"]);source.setDriverClass("com.mysql.jdbc.Driver");source.setJdbcUrl("jdbc:mysql:///day11");source.setUser("root");source.setPassword("666666");
ComboPooledDataSource source = new ComboPooledDataSource();
<c3p0-config> //多个配置时<default-config name="aaa"><property name="driverClass">com.mysql.jdbc.Driver</property><property name="jdbcUrl">jdbc:mysql:///day11</property><property name="user">root</property><property name="password">666666</property></default-config></c3p0-config>
3、tomcat内置的数据源(DBCP): Apache
JNDI(Java Naming and Directory Interface),Java命名和目录接口,它对应于J2SE中的javax.naming包,这套API的主要作用在于:它可以把Java对象放在一个容器中(支持JNDI容器 Tomcat),并为容器中的java对象取一个名称,以后程序想获得Java对象,只需通过名称检索即可。
其核心API为Context,它代表JNDI容器,其lookup方法为检索容器中对应名称的对象。
~1.如何为tomcat配置数据源
(1)、给所有web应用起作用
~tomcat/conf/context.xml文件中配置<Context>配置在这个位置的信息将会被所有的web应用所共享
~tomcat/conf/[enginename]/[Host]/context.xml文件中可以配置<Context>标签,这里配置的信息将会被这台虚拟主机中的所有web应用所共享(引擎名/主机名
F:\tomcat8\conf\Catalina\localhost)
(2)、给当前web应用起作用
~tomcat/conf/server.xml文件中的<Host>标签中配置<Context>标签,这是web应用的第一种配置方式,在这个标签中配置的信息将只对当前web应用起作用
~tomcat/conf/[enginename]/[Host]/自己创建一个.xml文件,在这个文件中使用<Context>标签配置一个web应用,这是web应用第二种配置方式,在这个<Context>标签中配置的信息将只会对当前web应用起作用
~web应用还有第三种配置方式:将web应用直接放置到虚拟主机管理的目录.此时可以在web应用的META-INF文件夹下创建一个context.xml文件,在其中可以写<Context>标签进行配置,这种配置信息将只会对当前web应用起作用
<?xml version="1.0" encoding="utf-8"?><Context><Resource name="mySource" auth="Container" type="javax.sql.DataSource"username="root" password="666666"driverClassName="com.mysql.jdbc.Driver"url="jdbc:mysql:///day11"maxActive="8" maxIdle="4"/></Context>
~2.如果在程序中获取这个数据源
想要访问JNDI就必须在Servlet中才能执行下列代码:
import javax.naming.Context/InitialContext;Context initCtx = new InitialContext();Context jndi = (Context) initCtx.lookup("java:comp/env");DataSource source = jndi.lookup("mySource");
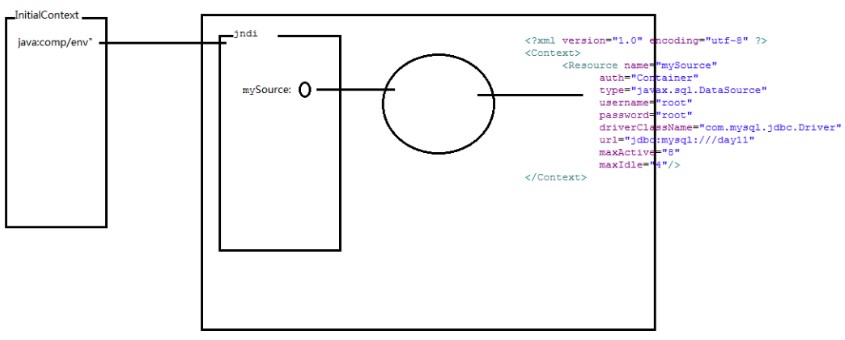
1、context.xml配置
<?xml version="1.0" encoding="utf-8"?><Context><Resource name="mySource" auth="Container"type="javax.sql.DataSource"username="root" password="666666"driverClassName="com.mysql.jdbc.Driver"url="jdbc:mysql:///day11"maxActive="8" maxIdle="4"/></Context>
2、web.xml配置
<?xml version="1.0" encoding="UTF-8"?><web-app version="3.0"xmlns="http://java.sun.com/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://java.sun.com/xml/ns/javaeehttp://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"><servlet><servlet-name>DataSourceInitServlet</servlet-name><servlet-class>com.lmd.init.DataSourceInitServlet</servlet-class><load-on-startup>1</load-on-startup><!-- 一启动就加载 -->1,2,3,4,5代表的是优先级,值越小,优先级所高</servlet>- <servlet-mapping>
<servlet-name>DataSourceInitServlet</servlet-name><url-pattern>/servlet/DataSourceInitServlet</url-pattern></servlet-mapping>- </web-app>
3、DataSourceInitServlet.java
mysql-connector-java-5.1.40-bin.jar最好放在F:\tomcat8\lib文件夹下
package com.lmd.init;import java.io.IOException;import java.sql.Connection/PreparedStatement/ResultSet;import javax.naming.Context/InitialContext;import javax.servlet.ServletException;import javax.servlet.http.HttpServlet/HttpServletRequest/HttpServletResponse;import javax.sql.DataSource;public class DataSourceInitServlet extends HttpServlet {//DataSource source = null;public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {}public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {doGet(request, response);}//servlet一创建就运行init@Overridepublic void init() throws ServletException {try {Context initCtx = new InitialContext();Context jndi = (Context) initCtx.lookup("java:comp/env");DataSource source = (DataSource) jndi.lookup("mySource");//使用类变量获取//或者存起来this.getServletContext().setAttribute("", source);Connection conn = source.getConnection();PreparedStatement ps = conn.prepareStatement("select * from account");ResultSet rs = ps.executeQuery();while (rs.next()) {String name = rs.getString("name");System.out.println(name);}rs.close();ps.close();conn.close();} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);}}}
4、元数据
- DataBaseMetaData
(1)、元数据:数据库、表、列的定义信息。
(2)、 Connection.getMetaData()
(3)、DataBaseMetaData对象
getURL():返回一个String类对象,代表数据库的URL。
getUserName():返回连接当前数据库管理系统的用户名。
getDriverName():返回驱动驱动程序的名称。
getPrimaryKeys(String catalog, String schema, String table):返回指定表主键的结果集
getTables()
- ParameterMetaData
(1)、PreparedStatement . getParameterMetaData()
获得代表PreparedStatement元数据的ParameterMetaData对象。
select * from user where name=? And password=?
(2)、ParameterMetaData对象
getParameterCount() 获得指定参数的个数
getParameterTypeName(int param) 获得指定参数的sql类型
(3)、getParameterType异常处理
Parameter metadata not available for the given statement
(4)、url后面拼接参数 ?generateSimpleParameterMetadata=true
- ResultSetMetaData
(1)、ResultSet. getMetaData()
获得代表ResultSet对象元数据的ResultSetMetaData对象。
(2)、ResultSetMetaData对象
getColumnCount() 返回resultset对象的列数
getColumnName(int column) 获得指定列的名称
getColumnTypeName(int column) 获得指定列的类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号