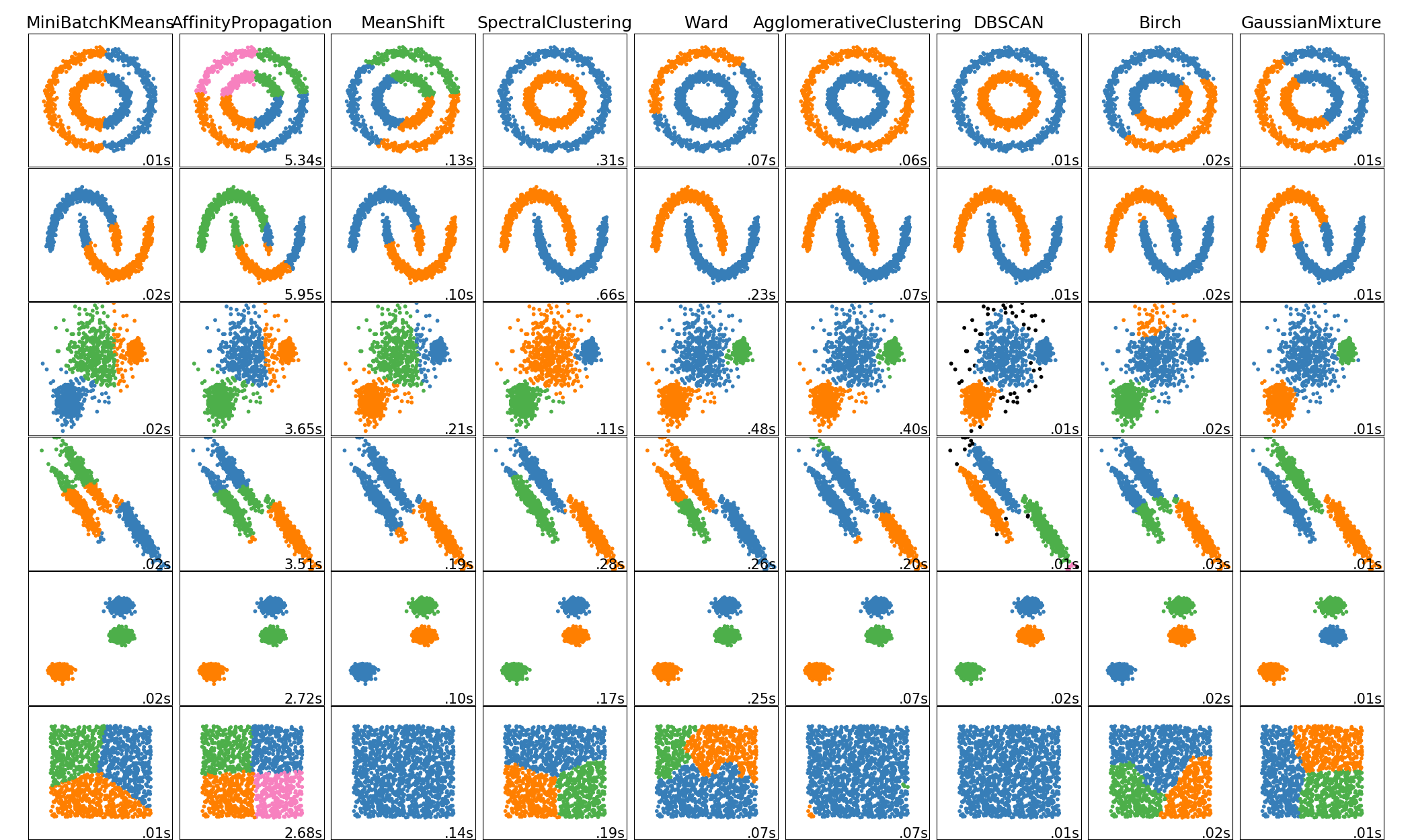
sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
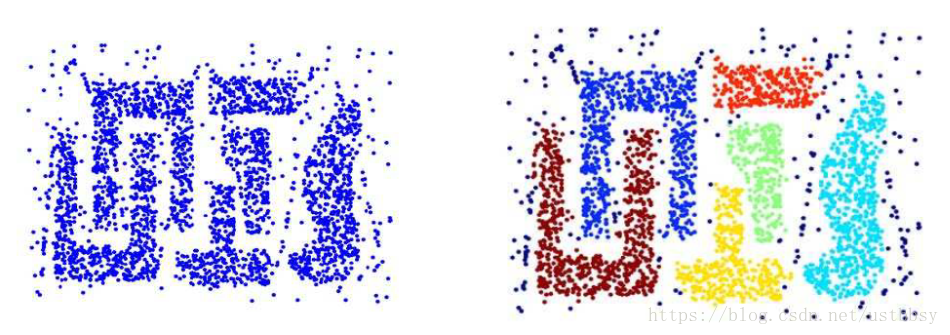
4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类)
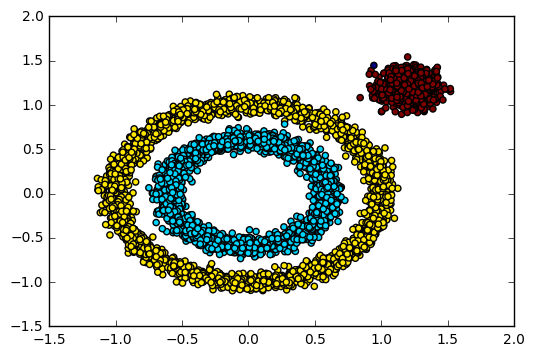
6 混合高斯模型Gaussian Mixture Model(GMM)

#===============================================
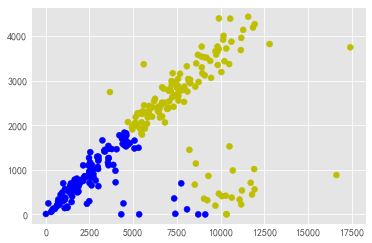
从左到右依次为: k-means聚类, DBSCAN聚类 , GMM聚类


对应代码:
# kmeans聚类 from sklearn.cluster import KMeans estimator = KMeans(n_clusters=2)#构造聚类器 y_pred =estimator.fit_predict(X_train_2)#聚类 clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred] plt.scatter(X_train[:,0],X_train[:,1],c=clr) # DBSCAN(Density-Based Spatial Clustering of Application with Noise)基于密度的空间聚类算法 from sklearn.cluster import DBSCAN dbs1 = DBSCAN(eps=0.5, # 邻域半径 min_samples=5 ) # 最小样本点数,MinPts y_pred = dbs1.fit_predict(X_train_2) #训练集的标签 clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred] plt.scatter(X_train_2[:,0],X_train_2[:,1],c=clr) #混合高斯模型Gaussian Mixture Model(GMM)聚类 from sklearn import mixture clf = mixture.GaussianMixture(n_components=2,covariance_type='full') clf.fit(X_train_2) #.fit_predict y_pred = clf.predict(X_train_2) #预测 clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred] plt.scatter(X_train_2[:,0],X_train_2[:,1],c=clr)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号