AIstudio平台进行深度学习试炼
最近百度的paddlepaddl推广力度不是一般的大,在学习paddle同时,也在看其他深度学习框架,懒得搭环境,就借用百度平台进行练手了。由于权限以及各种库版本问题,百度云环境只能用CPU版本的,有点小遗憾。话不多说,直接上代码,keras框架下对电影评论二分类。
#在notebook下编写,首先安装所需的各种库。如果需要进行持久化安装, 需要使用持久化路径
!mkdir /home/aistudio/external-libraries !pip install keras -t /home/aistudio/external-libraries !pip install tensorflow -t /home/aistudio/external-libraries
#同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys sys.path.append('/home/aistudio/external-libraries')
# %%writefile './external-libraries/movie.py' from keras.datasets import imdb from keras import models from keras import layers import numpy as np import matplotlib.pyplot as plt (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) # print('data' ,train_data[0]) # print('label', train_labels[0]) word_index = imdb.get_word_index() reverse_word_index = dict( [(value, key) for (key, value) in word_index.items()]) decoded_review = ''.join( [reverse_word_index.get(i - 3, '?') for i in train_data[0]]) print(decoded_review) def vectorize_sequences(squences, dimension=10000): results = np.zeros((len(squences), dimension)) for i, squence in enumerate(squences): results[i, squence] = 1 # print('results = ', results) return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32') model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000, ))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) # model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) x_val = x_train[:10000] partial_x_train = x_train[10000:] # print('partial :', partial_x_train) y_val = y_train[:10000] partial_y_train = y_train[10000:] model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) histroy = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val,y_val)) histroy_dict = histroy.history # 20组 keys = histroy_dict.keys() values = histroy_dict.values() # print('keys:', keys, 'values:', values) loss_value = histroy_dict['loss'] val_loss_value = histroy_dict['val_loss'] epochs = range(1, len(loss_value) + 1) plt.plot(epochs, loss_value, 'bo', label='Training loss') plt.plot(epochs, val_loss_value, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show() plt.clf() acc = histroy_dict['acc'] val_acc = histroy_dict['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()
下边运行log:
Train on 15000 samples, validate on 10000 samples Epoch 1/20 15000/15000 [==============================] - 2s 155us/step - loss: 0.5305 - acc: 0.7811 - val_loss: 0.3971 - val_acc: 0.87 Epoch 2/20 15000/15000 [==============================] - 2s 143us/step - loss: 0.3182 - acc: 0.9001 - val_loss: 0.3270 - val_acc: 0.88 Epoch 3/20 15000/15000 [==============================] - 2s 144us/step - loss: 0.2300 - acc: 0.9287 - val_loss: 0.2972 - val_acc: 0.880 Epoch 4/20 15000/15000 [==============================] - 2s 144us/step - loss: 0.1815 - acc: 0.9421 - val_loss: 0.2923 - val_acc: 0.88 Epoch 5/20 15000/15000 [==============================] - 2s 143us/step - loss: 0.1481 - acc: 0.9531 - val_loss: 0.2807 - val_acc: 0.887 Epoch 6/20 15000/15000 [==============================] - 2s 148us/step - loss: 0.1227 - acc: 0.9624 - val_loss: 0.3096 - val_acc: 0.878 Epoch 7/20 15000/15000 [==============================] - 2s 143us/step - loss: 0.1021 - acc: 0.9709 - val_loss: 0.3169 - val_acc: 0.87 Epoch 8/20 15000/15000 [==============================] - 2s 144us/step - loss: 0.0872 - acc: 0.9751 - val_loss: 0.3257 - val_acc: 0.88 Epoch 9/20 15000/15000 [==============================] - 2s 144us/step - loss: 0.0724 - acc: 0.9814 - val_loss: 0.3503 - val_acc: 0.882 Epoch 10/20 15000/15000 [==============================] - 2s 143us/step - loss: 0.0610 - acc: 0.9846 - val_loss: 0.3702 - val_acc: 0.88 Epoch 11/20 15000/15000 [==============================] - 2s 143us/step - loss: 0.0489 - acc: 0.9901 - val_loss: 0.4122 - val_acc: 0.878 Epoch 12/20 15000/15000 [==============================] - 2s 144us/step - loss: 0.0417 - acc: 0.9915 - val_loss: 0.4241 - val_acc: 0.876 Epoch 13/20 15000/15000 [==============================] - 2s 147us/step - loss: 0.0327 - acc: 0.9947 - val_loss: 0.4542 - val_acc: 0.87 Epoch 14/20 15000/15000 [==============================] - 2s 145us/step - loss: 0.0272 - acc: 0.9951 - val_loss: 0.4983 - val_acc: 0.86 Epoch 15/20 15000/15000 [==============================] - 2s 147us/step - loss: 0.0213 - acc: 0.9965 - val_loss: 0.5144 - val_acc: 0.86 Epoch 16/20 15000/15000 [==============================] - 2s 147us/step - loss: 0.0171 - acc: 0.9975 - val_loss: 0.5459 - val_acc: 0.870 Epoch 17/20 15000/15000 [==============================] - 2s 152us/step - loss: 0.0123 - acc: 0.9985 - val_loss: 0.5868 - val_acc: 0.868 Epoch 18/20 15000/15000 [==============================] - 2s 146us/step - loss: 0.0146 - acc: 0.9967 - val_loss: 0.6150 - val_acc: 0.867 Epoch 19/20 15000/15000 [==============================] - 2s 145us/step - loss: 0.0056 - acc: 0.9996 - val_loss: 0.6424 - val_acc: 0.865 Epoch 20/20 15000/15000 [==============================] - 2s 150us/step - loss: 0.0089 - acc: 0.9979 - val_loss: 0.6818 - val_acc: 0.865
训练与验证的损失和精度图:
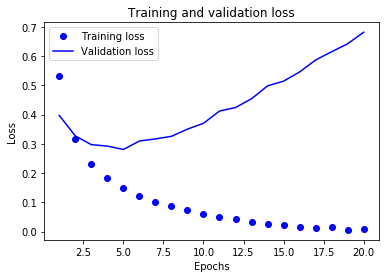
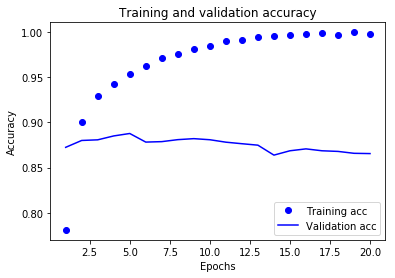
这里需要注意,由于用的是百度的服务器,下载的数据集等内容重启就会清除,为了永久保存,需要修改/keras/utils/data_utils.py文件中的路径信息,如下
176行的 cache_dir = os.path.join(os.path.expanduser('~'), '.keras') 修改为: cache_dir = os.path.join(os.path.expanduser('~'), 'external-libraries/keras/')
这样可以确保数据集下载一次,后续不用再下载,当然,如果是自己的主机,可以不用做该步操作。
代码在《Python深度学习》第三章
一步,一步,一步...
回头看,已不见起点!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号