Pandas 学习
Pandas 学习
Pandas 数据读取

CSV 文件
fpath='...'
ratings=pd.read_csv(fpath)
ratings.head()
ratings.shape # 行列数
ratings.colums # 查看列名列表
ratings.dtype # 查看数据类型
txt 文件,自己指定分隔符和列名
fpath='...'
pvuv=pd.read_csv(
fpath,
sep="\t",
header=None,
names=['pdate','pv','uv']
)
读取 excel 文件
fpath='...'
pvuv=pd.read_excel(fpath)
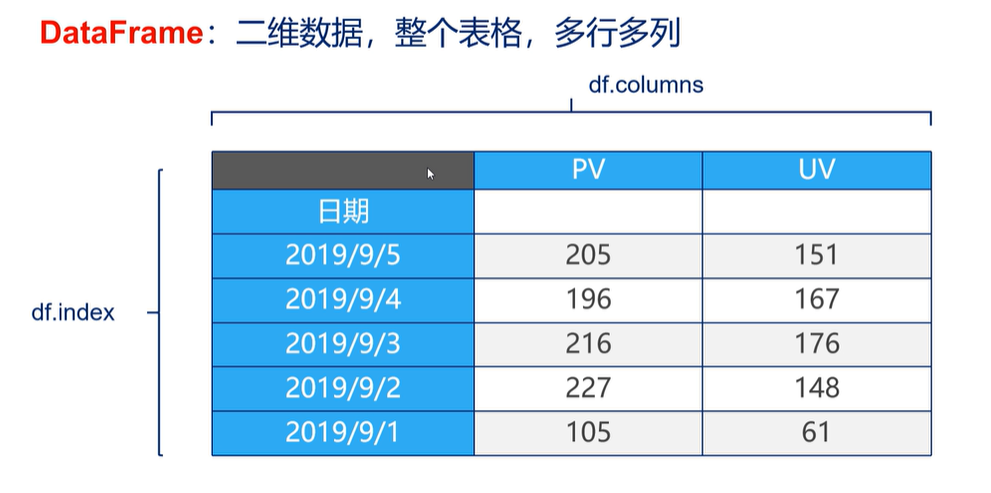
Pandas 数据结构 DataFrame & Series
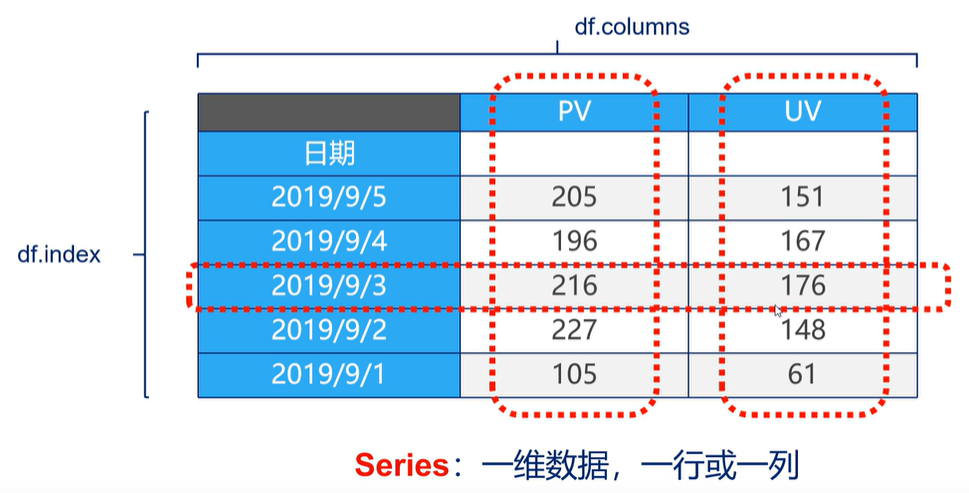
Series
Series 是一种类似一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签组成。
s1=pd.Series([1,'a',5.2,7])
print(s1) # 左侧为索引,右侧是数据
s1.index
s1.value
s1=pd.Series([1,'a',5.2,7],index=['d','b','a','c'])
sdata={'Ohio':2323,'Tes':2123}
s1=pd.Series(sdata)
print(s1[['Ohio','Tes']]) # 查询多列数据
DataFrame
DataFrame 是一个表格型的数据结构。
每列可以是不同的值类型(数值,字符串,布尔值等)
既有行索引 index,也有列索引 columns
可以被看作由 Series 组成的字典
data={
'state':['Ohio','Yes'],
'year':[2000,2001],
'pop':[1.4,1.2]
}
df=pd.DataFrame(data)
# DataFrame 种查询 Series
# 如果查询一行、一列,则是 Series
# 如果查询多行、多列,则是 DataFrame
df['year'] # 查询一列
# 查询一行
df.loc[1]
df.loc[1:3] # 包含末尾元素和 Python 基本语法不同
Pandas 数据查询
df.loc 根据行列的标签值查询
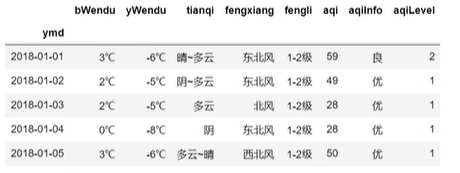
df=pd.read_csv('...')
df.head()
# 更改默认索引
df.set_index('ymd',inplace=True)
# 替换掉温度的后缀
df.loc[:,"bWendu"]=df["bWendu"].str.replace("°C","").astype('int32')
df.loc[:,"yWendu"]=df["yWendu"].str.replace("°C","").astype('int32')
df.dtypes
# 使用单个 label 值查询数据
df.loc['2018-01-03','bWendu']
df.loc['2018-01-03',['bWendu',y'Wendu']]
# 使用数值区间列表批量查询
df.loc[['2018-01-03':'2018-01-05'],'bWendu']
# 条件表达式
df.loc[df['yWendu']<-10,:]
# lambda 表达式
df.loc[lambda df:(df["bWendu"]<=30),:]
# 函数
def f(df):
return df.index.str.startswith('2018-09') & df['aqiLevel']=1
df.loc[query_my_data,:]
Pandas 新增数据列
fpath='...'
df.loc[:,"bWendu"]=df["bWendu"].str.replace("°C","").astype('int32')
# 计算温差
df.loc[:,"wencha"]=df["bWendu"]-df["yWendu"]
df.head()
# df.apply
def get_wendu_type(x):
if x["bWendu"] > 33:
return '高温'
if x['yWendu'] < -10:
return '低温'
return '常量'
df.loc[:,"wendu_type"]=df.apply(get_wendu_type,axis=1) # 列
# 查看温度类型的计数
df["wendu_type"].value_counts()
# df.assign 指定多个列
df.assign(
yWendu_huashi=lambda x:x["yWendu"]*9/5+32,
bWendu_huashi=lambda x:x["bWendu"]*9/5+32
)
# 按条件选择分组
df['wencha_type']=''
df.loc[df['bWendu']-df['yWendu']>10,'wencha_type']='温差大']
数据统计函数
# 汇总类统计
df.describe() # 一次提取所有数字列统计结果
df['bWendu'].mean() # 查看单个 Series 的数据
# 唯一去重
df["fenxiang"].unique()
# 按值计数
df["fengxiang"].value_count()
# 相关系数和协方差
# 协方差:衡量同向反向程度,如果协方差为正,则说明 X,Y 同向变化,协方差越大说明同向程度越高
# 相关系数:衡量相似度程度,当相关系数为 1 时,说明两个变量变化时的正向相似度最大,当相关系数
# 为 -1 时,说明两个变量变化的反向相似度最大
df.cov() # 协方差矩阵
df.corr() # 相关系数矩阵
# 单独查看
df["aqi"].corr(df["bWendu"])
缺失值处理
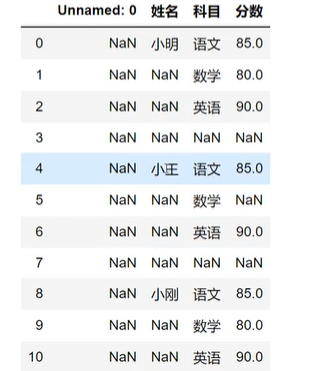
studf=pd.read_excel('',skiprows=2) # 略过空行
# 检测空值
studf.isNull()
studf["分数"].isnull()
studf["分数"].notnull()
# 删除全是空值的列
studf.dropna(axis='columns',how='all',inplace=True)
studf.dropna(axis='index',how='all',inplace=True)
# 将分数列为空的填充为 0
studf.fillna({"分数":0})
studf.loc[:,'分数']=studf['分数'].fillna(0)
# 使用前面的有效值填充
studf.loc[:,'姓名']=studf['姓名'].fillna(method='ffill')
# 将数据保存
studf.to_excel("./datas/student_excel/student_excel_clean.xlsx',index=False)
SettingWithCopyWarning 报警解决
fpath='..'
df=pd.read_csv(fpath)
condition=df['ymd'].str.startswith("2018-03")
# 设置温差,出现报警(链式报警)
df[condition['wen_cha']]=df['bWendu']-df['yWendu']
# 解决方法1
df.loc[condition,'wen_cha']=df['bWendu']-df['yWendu']
# 解决方法2
df_month3=df[condition].copy()
df_month3.['wen_cha']=df['bWendu']-df['yWendu']
# 总结,pandas 不允许先筛选子 dataframe ,再进行修改写入
Pandas 数据排序
fpath='...'
df=pd.read_csv(fpath)
....
# Series 排序
df["aqi"].sort_values()
df["aqi"].sort_values(ascending=False) #降序排列
# dataFrame 排序
df.sort_values(by='aqi')
df.sort_values(by=['aqi','bWendu'])
df.sort_values(by=['aqiLevel','bWendu'],ascending=[True,False])
字符串处理
使用方法:先获取 Series 的 str 属性,在属性上调用函数
Dataframe 上没有
df['bWendu'].str
df['bWendu'].str.isnumeric()
condition=df['ymd'].str.startwith('2018-03')
df['ymd'].str.replace('-','')
df['ymd'].str.replace('-','').str.slice(0,6)
# 正则表达式
df['中文日期'].str.replace('[年月日]','')
Panda axis 参数
df=pd.DataFrame(
np.arange(12).reshape(3,4),
columns=['A','B','C','D']
}
# 单列删除
df.drop('A',axis=1)
# 单行删除
df.drop(1,axis=0)
# 对应的行动起来,按列求平均
df.mean(axis=0)
index 用途
# 设置索引
df.set_index('user_id',inplace=True,drop=False)
Pandas Merge
df_ratings=pd.read_csv(
'...',
sep='::',
engine='python',
name='UserID:MovieID::Rating::Timestamp'.split('::')
)
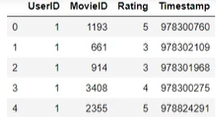
df_users=pd.read_csv(
'...',
sep='::',
engine='python',
name='...'.split('::')
)
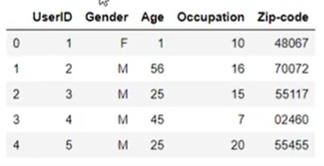
df_movies=pd.read_csv(
'...',
sep='::',
engine='python',
name='...'.split('::')
)
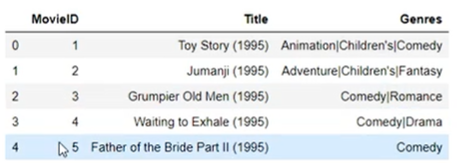
df_ratings_users=pd.merge(
df_ratings,df_users,left_on='UserID',right_on='UserID',how='inner'
)
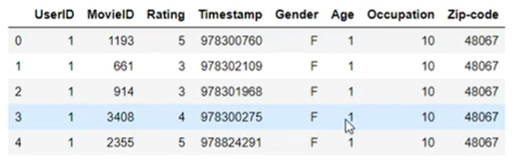
# 数量对齐关系
# one-to-one
# one-to-many
# 一对多关系,左边唯一 Key,右边不唯一key,复制左边信息
# many-to-many
# 左右信息都不唯一,结果条数 M*N

 浙公网安备 33010602011771号
浙公网安备 33010602011771号