Kafka基础知识及实战
为什么要用消息中间件
解耦、异步、削峰限流
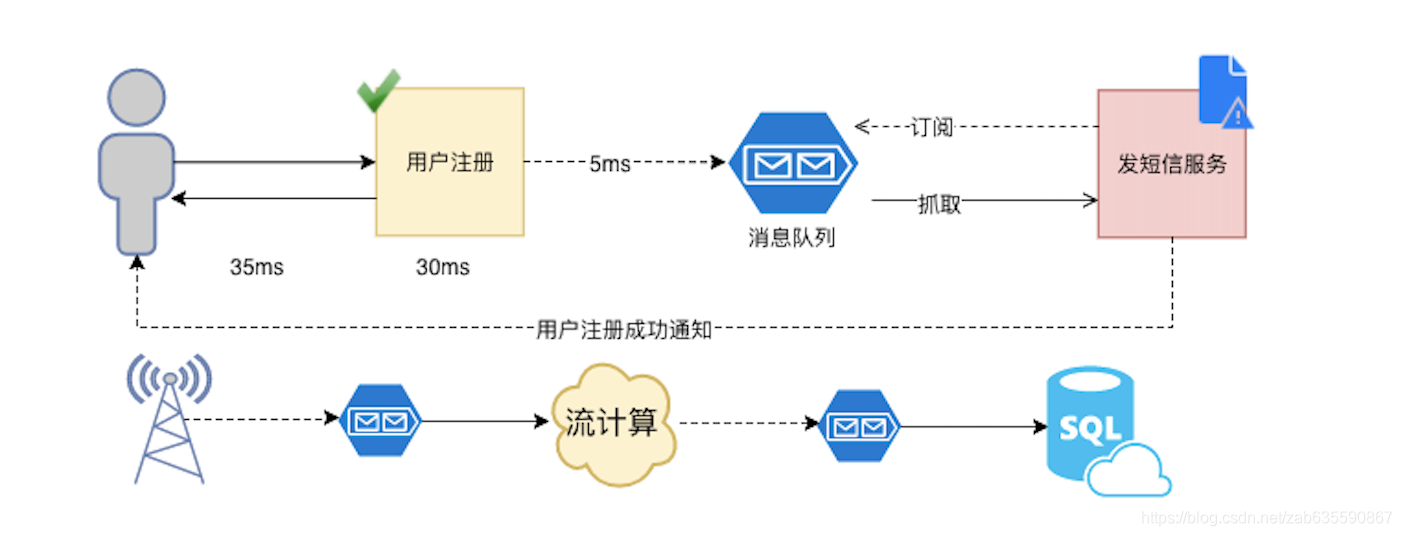
解耦:如上图所示,如果用户注册的"发短信"功能代码和用户数据写表的代码写在一个类或者方法里,就容易把发短信的功能作死,注册和发短信耦合度就太高了,不灵活!就像勺子和叉子功能不同,厂家也是分开生产的,大概不会有勺子和叉子连在一起的设计吧。
异步:如果耦合度太高,功能就只能是发完短信,才能通知用户注册成功,但是如果发短信调用的是第三方服务,恰好服务又有问题,那么用户注册就得等着服务恢复才能返回给用户说,您注册好嘞。有了消息中间件,可以直接把发短信的命令发给中间件(过程很快),后续详细发送短信的逻辑由另外的监听着消息中间件的命令的服务完成,这个过程就好像???你要送东西给你异地的朋友,没有消息中间件,你得自己亲自把东西带着,做飞机、再转轮船、再转火车、再转汽车、再转摩托车、再步行十里路到他家给他!整个过程都得你亲自完成,你就不能做其他事!但是如果有了消息中间件,你可以到楼下菜鸟驿站发送给某快递厂商,然后把快递编号给你朋友,就说你等着!我有东西给你,你有空了就去取,整个过程你发完快递(过程很快)就可以做其他事了。高效不是吗?
削峰限流:传统行业领会不到消息中间件还有如此作用!大多数都是用来做做异步解耦。设想一种场景,双十一秒杀,如果是开个接口直接去迎接这个高并发,不管你怎么做负载总感觉请求太多,难以支撑。但是如果,有一个接口专门接受请求,不处理业务逻辑(接口压力小很多),然后就发送消息到中间件,然后后台一堆微服务监听着这个消息呢,当消息堆积成山无法处理时,消息中间件有拒绝策略,服务还是照常取一个处理一个,这时候就可以起到削峰限流的作用。
消息中间件常用工作模式
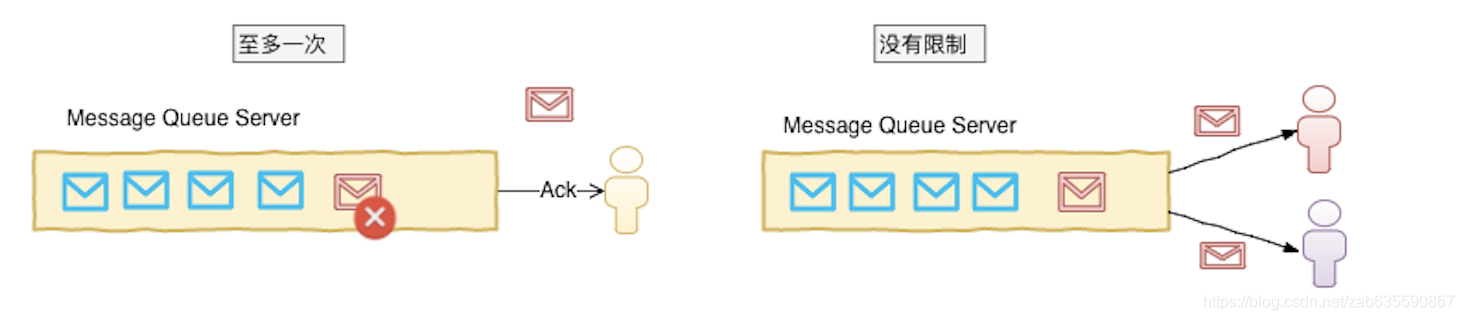
至多消费一次
消息生产者生产的消息如果被消费者消费后,消费者会向生产者服务器确认已消费,由生产者主动删除服务器的消费过的消息
没有限制消费次数
消息生产者发完消息后,该消息可以由多个消费者同时消费,并且同一个消费者可以多次消费消息服务器的同一个记录
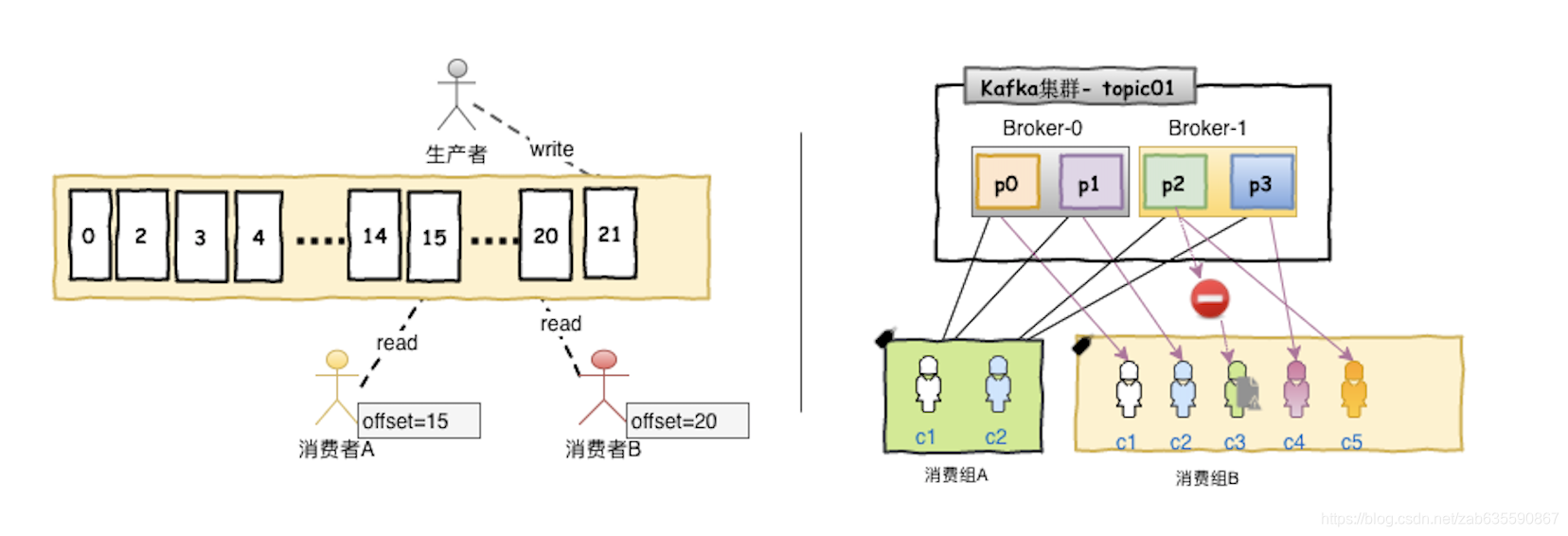
kafka架构
kafka消息以topic分类,消息称为record
每个topic底层都会对应一组partition分区的日志,用于持久化topic的record。
每台kafka服务器称为broker
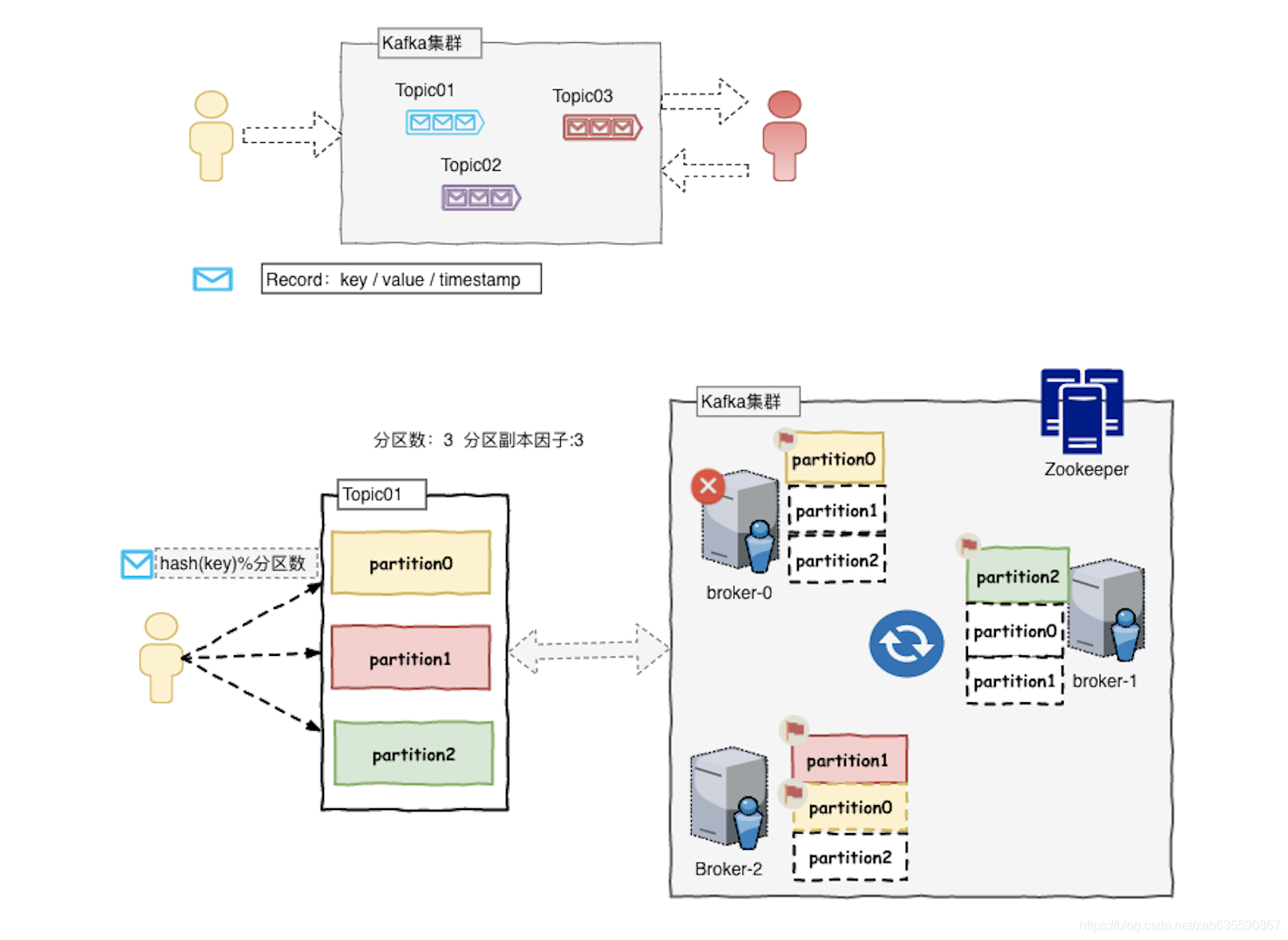
副本因子为3,集群中就会存在三份分区数据。
同一个broker可能是某分区的master,但是也有可能是另外分区的follower,也就是说身兼数职。
分区内部有序,消息严格先进先出;分区之间消息不保证顺序
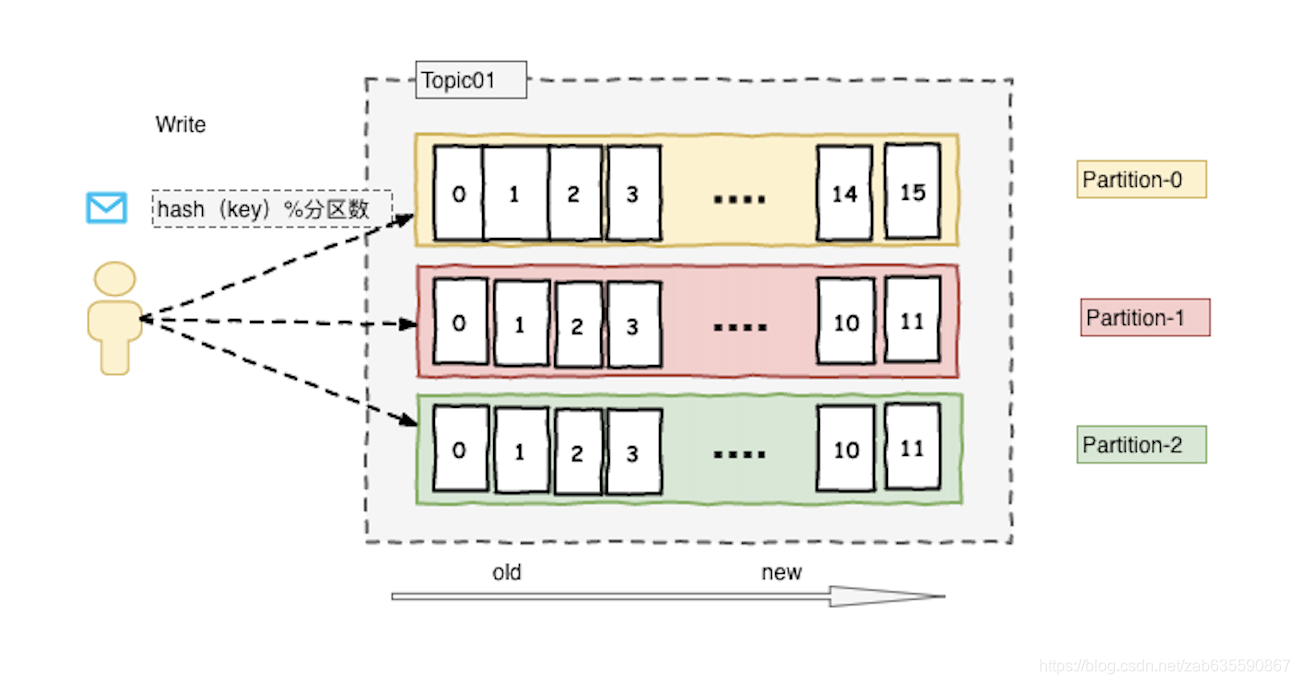
分区作用:每个分区其实都是有对应物理机作为载体的,分区越多,理论上速度越快,存储能力越强。
消费组概念:
1、每个消费组有多个消费者实例
2、同一个消费组内的消费者实例均匀消费同一个topic下的不同分区的消息
类比ActiveMq
不同消费组对于同一个topic有点类似于发布-订阅模式
偏移量概念:
下一次读取消息的位置。
消费者是如何提交偏移量的呢?消费者往一个名为 _consumer_offset 的默认主题发送消息,消息里包含每个分区的偏移量。 如果消费者一直都没有挂,那么偏移量就不起什么作用。不过,如果消费者挂了或者有新的消费者加入群组,就会触发再均衡,完成再均衡之后,每个消费者可能分配到新的分区,而不是之前处理的那个。为了能够继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续处理
kafka高性能之道
- 消息生产者而言
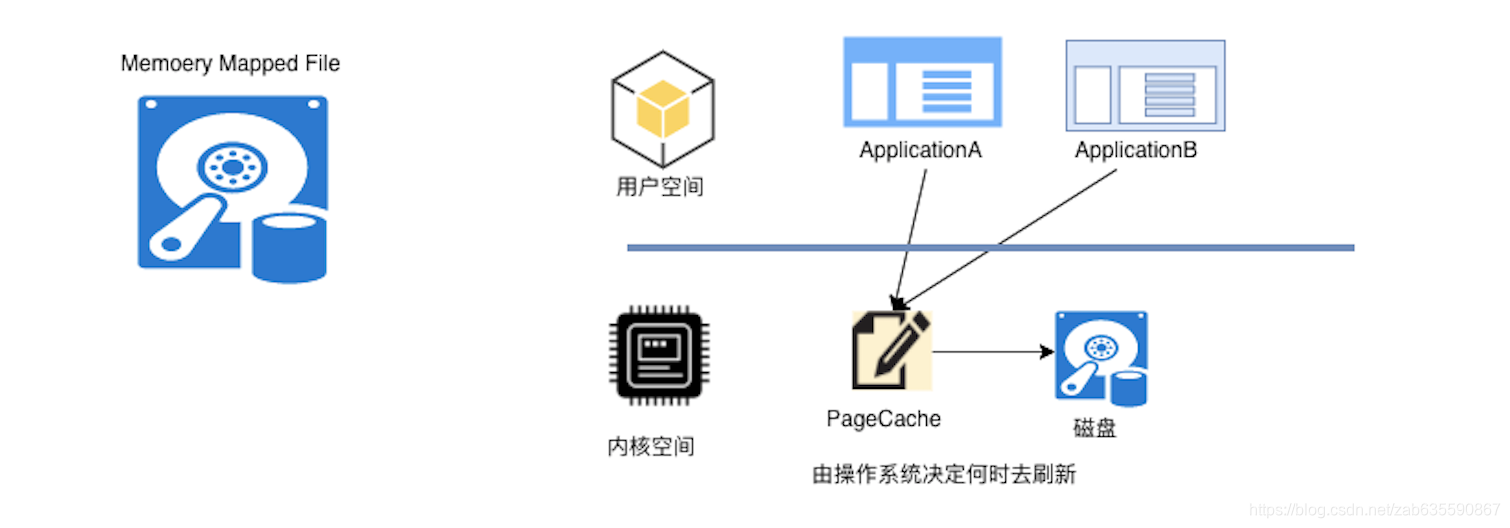
kafka消息生产会落盘,但是速度却可以媲美内存。
原因有二:
- kafka采用了MMAP(Memory Mapped Files),它的工作原理是直接利用操作系统的Page实现文件到物理内存的直接映射。减少了内存到磁盘的IO操作。
- kafka是顺序写入,对于机械硬盘顺序写入相比于随机写入高效得多。中间省去了耗时的寻址操作。
- 消息消费者而言
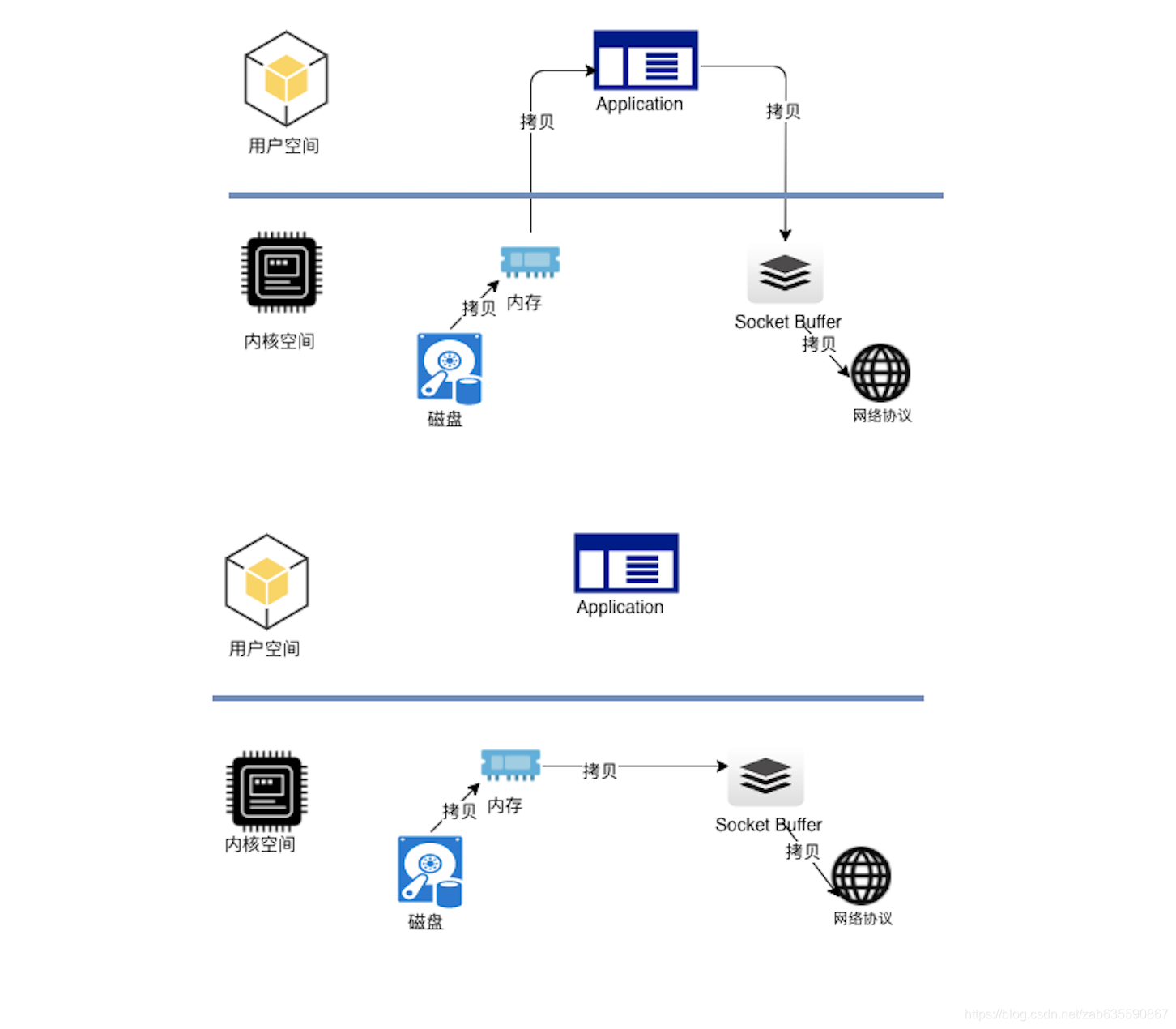
kafka消费时,也就是数据读出,采用了零拷贝技术,就是减少了内核态到用户态的无意义系统调用
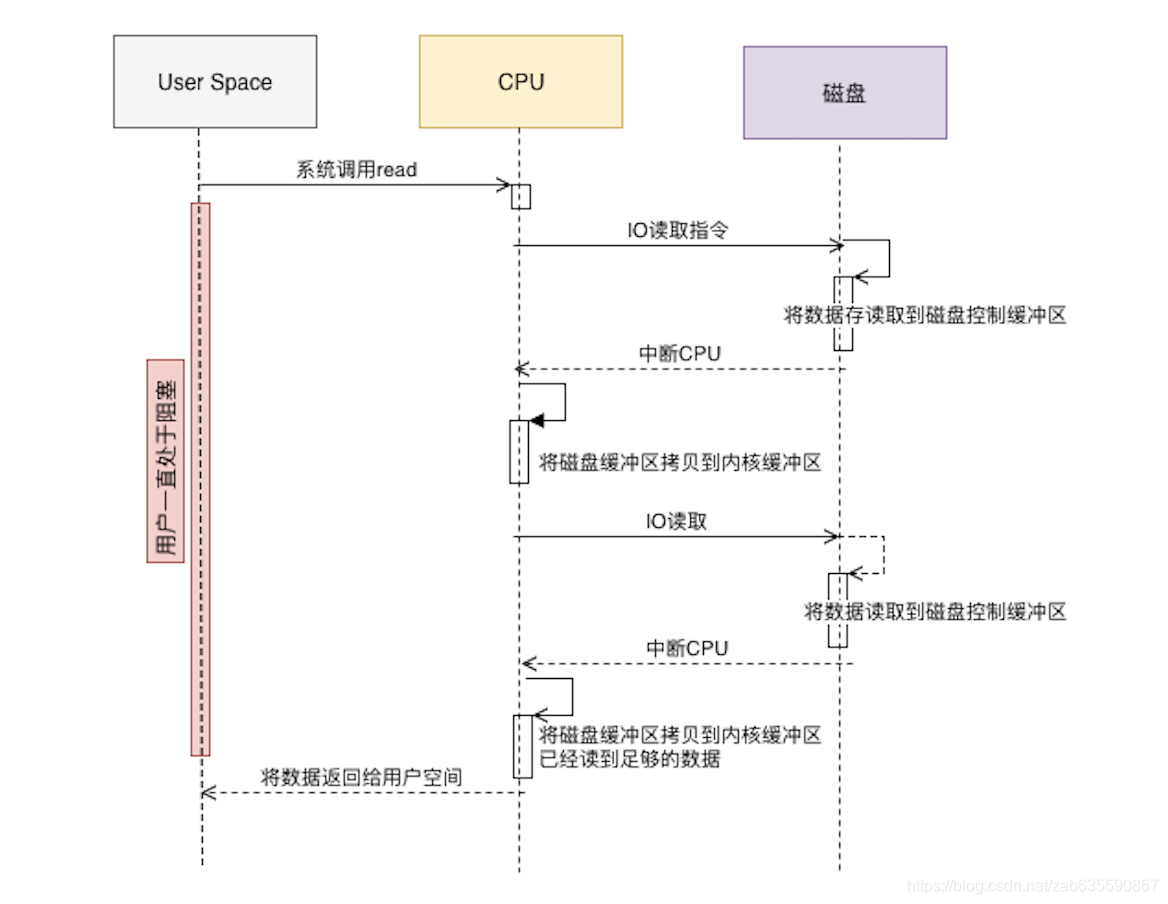
现代计算机对于磁盘-内存的数据IO操作还增加了DMA协处理器来处理,传统流程是
有DMA处理流程是
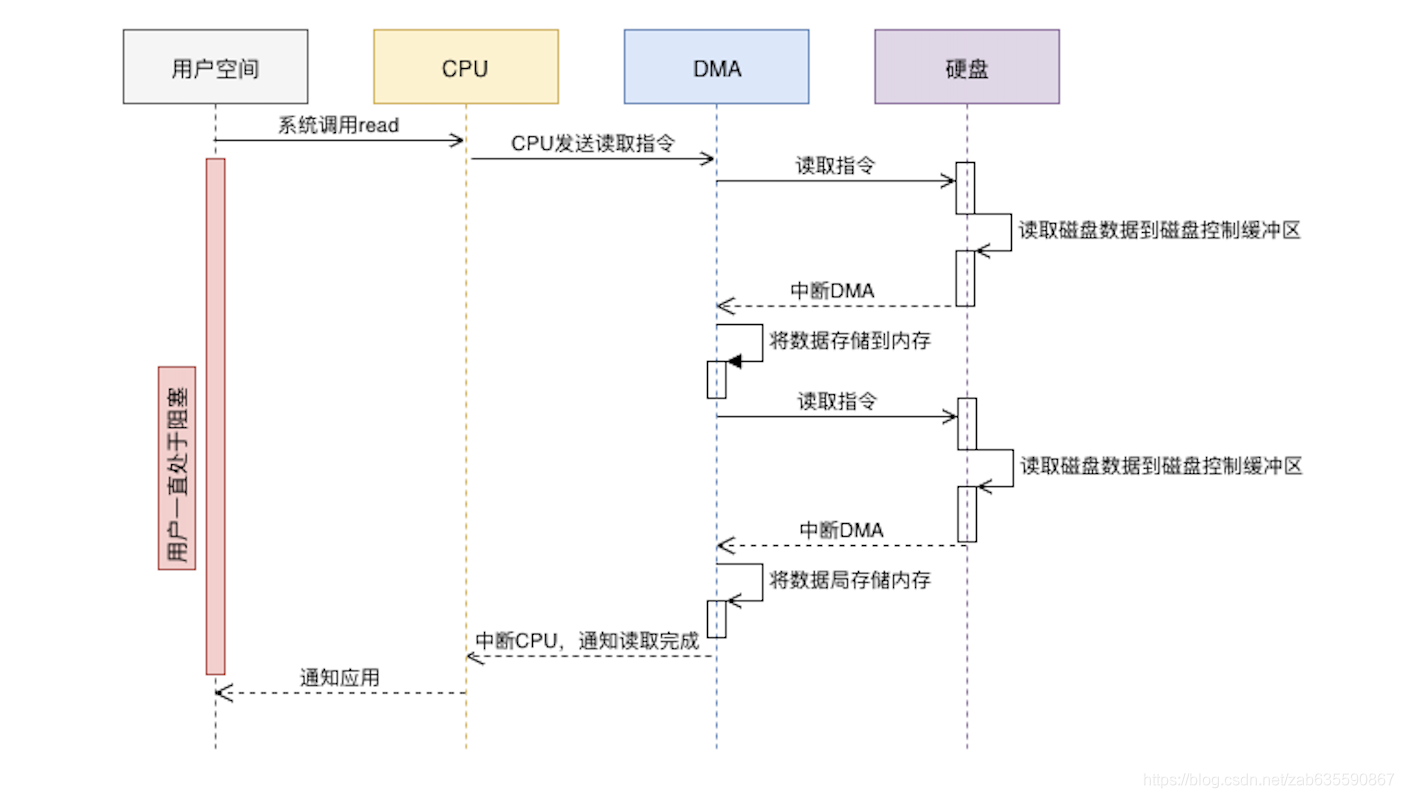
有了DMA,CPU可以专注于其他计算,而不是浪费性能在IO拷贝上。
kafka集群搭建
kafka用到了zookeeper作为协调工具,搭建kafka分布式集群,必须先有zk集群。下述搭建流程是单机伪分布式搭建流程
- zk集群搭建
下载
https://downloads.apache.org/zookeeper/stable/ 下载要带bin的
安装
上传到/usr/local/自定义目录
解压
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
修改配置文件
- 修改目录下conf 的zoo_sample.cfg文件为zoo.cfg
- 修改dataDir=自定义目录
- 修改dataLogDir=自定义目录
dataDir=/usr/local/services/zookeeper/apache-zookeeper-3.5.8-bin/data1
dataLogDir=/usr/local/services/zookeeper/apache-zookeeper-3.5.8-bin/logs1
clientPort=2181
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
添加myid
到dataDir配置的的目录下,添加一个myid
echo "1" > /usr/local/services/zookeeper/apache-zookeeper-3.5.8-bin/data1/myid
echo "2" > /usr/local/services/zookeeper/apache-zookeeper-3.5.8-bin/data2/myid
echo "3" > /usr/local/services/zookeeper/apache-zookeeper-3.5.8-bin/data3/myid
启动
切到软件解压根目录,指定配置文件的方式启动
./bin/zkServer.sh start ./conf/zoo1.cfg
- kafka集群搭建
如何下载kafka不同版本
https://archive.apache.org/dist/kafka
安装
上传到/usr/local/自定义目录
解压
tar -zxvf kafka-2.2.0-src.tgz
启动
启动前,先启动zookeeper
bin/kafka-server-start.sh --config/server.properties
集群配置
kafka目录下config文件夹 server.properties
- broker.id=自定义值
- advertised.listeners=PLAINTEXT://IP地址:9092
- listeners=PLAINTEXT://0.0.0.0:9092
- zookeeper.connect=IP地址:2181
listeners=PLAINTEXT://0.0.0.0:9092 broker.id=0
advertised.listeners=PLAINTEXT://118.24.232.124:9092
advertised.host.name=118.24.232.124
advertised.port=9092
log.dirs=/usr/local/services/kafka/kafka_2.11-2.2.0/logs1
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
kafka基础命令行操作
创建一个名为“test”的topic,它有一个分区和一个副本:
1
> bin/kafka-topics.sh --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 1 --partitions 1 --topic test运行list(列表)命令来查看这个topic:
1
2
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test或者也可将代理配置为:在发布的topic不存在时,自动创建topic,而不是手动创建。
Kafka自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为message(消息)发送到Kafka集群。默认情况下,每行将作为单独的message发送。
运行 producer,然后在控制台输入一些消息以发送到服务器。
1
2
3
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topictest
This is a message
This is another messageKafka 还有一个命令行consumer(消费者),将消息转储到标准输出。
1
2
3
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topictest--from-beginning
This is a message
This is another message将上述命令在不同的终端中运行,那么现在就可以将消息输入到生产者终端中,并将它们在消费终端中显示出来。
kafka 原生API
- 原生API最简版使用
producer配置
bootstrap.servers=http://118.24.232.124:9092,http://118.24.232.124:9093,http://118.24.232.124:9094 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer
producer原生api代码
package com.changan.kafka.base;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.InputStream;
import java.util.Properties;
/**
* kafka原生api
*
* @author zab
* @date 2020-11-01 12:04
*/
public class KafkaProducerBase {
public static void main(String[] args) throws Exception {
sendMsg("topic3", "A坐标");
}
private static void sendMsg(String topic, String msg) throws Exception {
InputStream resourceAsStream = KafkaProducerBase.class.getResourceAsStream("/kafka.properties");
Properties properties = new Properties();
properties.load(resourceAsStream);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg);
producer.send(record);
producer.close();
}
}
consumer配置
bootstrap.servers=http://118.24.232.124:9092,http://118.24.232.124:9093,http://118.24.232.124:9094
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
group.id=group1consumer原生api代码
package com.changan.kafka.consumer.base;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.io.InputStream;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
/**
* kafka消费者原生api
*
* @author zab
* @date 2020-11-01 12:26
*/
public class KafkaConsumerBase {
public static void main(String[] args) throws Exception{
InputStream resourceAsStream = KafkaConsumerBase.class.getResourceAsStream("/kafka.properties");
Properties properties = new Properties();
properties.load(resourceAsStream);
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList("topic3"));
while(true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
Thread.sleep(3000);
while (recordIterator.hasNext()){
ConsumerRecord<String, String> record = recordIterator.next();
String key = record.key();
String value = record.value();
long offset = record.offset();
int partition = record.partition();
System.out.println("-----------------------------key:"+key+",value:"+value+",partition:"+partition+",offset:"+offset);
}
}
}
}
最简版kafka配置说明:
1、配置消息生产者、消费者的kafka集群地址
2、配置生产者的消息序列化及消费者的消息反序列化方式
3、根据前面的kafka架构分析,配置消费者的groupid
- 原生api操作topic
package com.changan.kafka.base;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.KafkaFuture;
import java.io.InputStream;
import java.util.*;
import java.util.concurrent.ExecutionException;
/**
* kafka topic基础操作
* @author zab
* @date 2020-11-01 22:44
*/
public class TopicBase {
public static void main(String[] args) throws Exception {
InputStream resourceAsStream = KafkaProducerBase.class.getResourceAsStream("/kafka.properties");
Properties properties = new Properties();
properties.load(resourceAsStream);
KafkaAdminClient adminClient= (KafkaAdminClient) KafkaAdminClient.create(properties);
//查询topics
KafkaFuture<Set<String>> nameFutures = adminClient.listTopics().names();
for (String name : nameFutures.get()) {
System.out.println(name);
}
//创建Topics
List<NewTopic> newTopics = Arrays.asList(new NewTopic("topic3", 2, (short) 3));
//删除Topic
adminClient.deleteTopics(Arrays.asList("testTopic"));
//查看Topic详情
DescribeTopicsResult describeTopics = adminClient.describeTopics(Arrays.asList("topic3"));
Map<String, TopicDescription> tdm = describeTopics.all().get();
for (Map.Entry<String, TopicDescription> entry : tdm.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
adminClient.close();
}
}
kafka参数详解及测试
1、偏移量配置及测试
配置参数:
#是否自动提交偏移量
enable.auto.commit=true
#多少时间提交一次偏移量
auto.commit.interval.ms=10000测试步骤:
- 在以上原生api代码中的consumer配置文件加上偏移量配置,设置auto.commit.interval.ms=60000,也就是一分钟
- 启动生产者发一条消息
- 启动消费者,可以看到消费了生产者发送的消息,消费后一分钟内关闭消费者进程。这时候该消费者偏移量尚未提交到服务器。
- 再次启动消费者,可以看到又能消费刚刚生产者发送的消息。
- 设置auto.commit.interval.ms=1000,也就1秒钟提交一次偏移量,再次启动消费者,消费消息后,一秒后关闭消费者进程。
- 再次启动,再也无法看到之前重复消费的消息了。
2、确认消息配置
通常为了消息正确接收并处理成功,把消息的确认设置为手动提交
#是否自动提交偏移量
enable.auto.commit=false
测试步骤:
- consumer配置文件加上自动提交偏移量为false,也就是不会自动提交,需要代码确认后,亲自写提交代码
- 启动生产者发一条消息
- 启动消费者,可以看到消费了生产者发送的消息,这时关闭消费者,因为代码没有手动提交,kafka服务器不会知道该consumer的偏移量
- 不论多长时间重新启动消费者,都可以看到生产者最初发送的消息
- 添加以下手动提交代码,再次启动可以看到继续消费了生产者发送的消息,但是再启动,就发现已经提交,无法再次消费了
while(true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> recordIterator = consumerRecords.iterator();
Thread.sleep(3000);
while (recordIterator.hasNext()){
ConsumerRecord<String, String> record = recordIterator.next();
String key = record.key();
String value = record.value();
long offset = record.offset();
int partition = record.partition();
System.out.println("-----------------------------key:"+key+",value:"+value+",partition:"+partition+",offset:"+offset);
}
consumer.commitSync();
}3、指定消费分区
通过指定消费某分区,会失去组管理特性
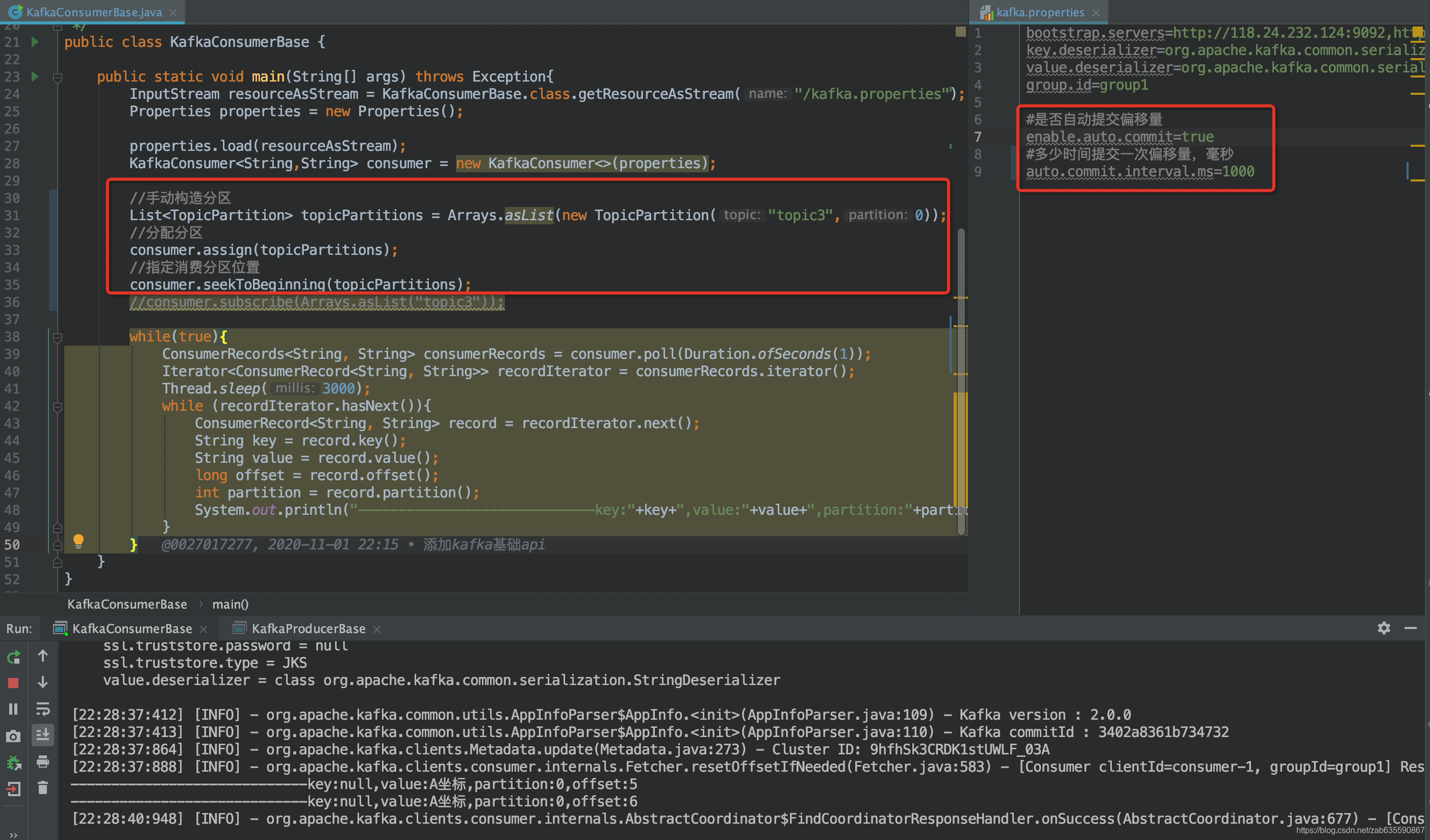
测试步骤:
- 注释消费者订阅的topic,添加图片所示的指定分区的代码
- 重新启动消费者实例,可以看到消费了两条数据,但是group1分组是已经消费了这两条数据的
- 再次重启消费者实例,还可以看到消费了两条数据,说明失去了组管理特性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号