
综合对应电路
本文讨论Verilog HDL与综合相关的问题。
一、赋值
本节讨论如何在Verilog中的实现不同的赋值,以及它们在逻辑综合中会推断出什么样的电路。
1.1、当对同一个net,使用多个assign语句,会综合出什么样的逻辑?
在可综合的verilog代码中,为同一个net使用多个assign语句是错误的。综合工具会报出语法错误,即“net is being driven by more than one source”。 例如,以下是错误的:
//only one type of output assignment is legal for synthesis
wire tmp ;
assign tmp = in1 & in2 ;
assign tmp = in1 | in2 ;但是,使用多个assign来驱动三态net 是合法的语句,如下示例所示:
input enable1 , enable2 ;
wire tmp ;
assigm tmp = (enable1 == 1’b1) ? (in1 & in2) : 1’bz ;
assigm tmp = (enable2 == 1’b1) ? (in3 & in3) : 1’bz ;1.2、条件赋值在逻辑综合时会推断出什么电路?
条件赋值通过“?:”实现。条件赋值在逻辑综合时被推断为MUX。 例如,以下示例是一个简单的MUX:
wire wire1 ;
assign wire1 = (sel == 1’b1) ? a : b ;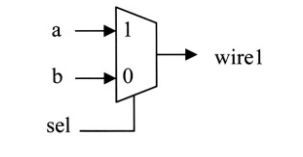
1.3、条件赋值嵌套会综合出什么样的电路?
如下例所示,条件赋值嵌套会被综合成MUX “tree ”:
assign out1 = (sel1 == 1’b1) ? in1 :
(sel2 == 1’b1) ? in2 :
(sel3 == 1’b1) ? in3 :in4 ; 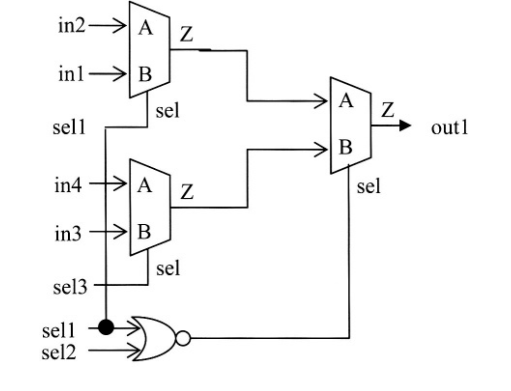
1.4 在同一个always语句块中,对同一个reg变量多次赋值会综合出什么电路 ?
在同一个always语句块中,对同一个reg变量进行多次非阻塞赋值时,逻辑综合时会选择最后一个赋值。 例如:
module lower(clk ,in1 ,in2 ,out2) ;
input clk ,in1 , in2 ;
outout out2 ;
reg tmp ;
always@(posedge clk) begin
tmp <= (in1 ^ in2) ;
tmp <= (in1 & in2) ;
tmp <= (in1 | in2) ;
end
assign out2 = tmp ;
endmodule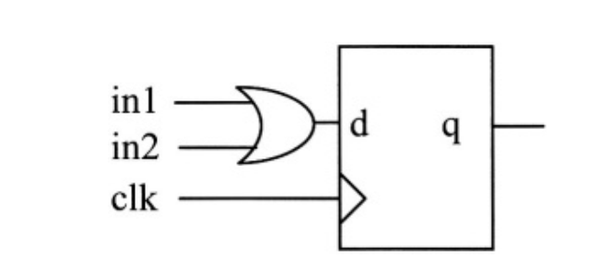
在刚刚的示例中,OR逻辑是最后一个赋值。因此,综合出来的逻辑是OR门。 如果最后一个赋值是“&”运算符,它会综合成一个AND逻辑。
对于组合逻辑中always语句块中的阻塞赋值来说,情况也是如此。
always@(in1 , in2) begin
tmp = (in1 & in2) ;
tmp = (in1 ^ in2) ;
tmp = (in1 | in2) ; // The final logic picked up is the OR gate
end如果多次赋值存在于if-else或case语句中。 例如,
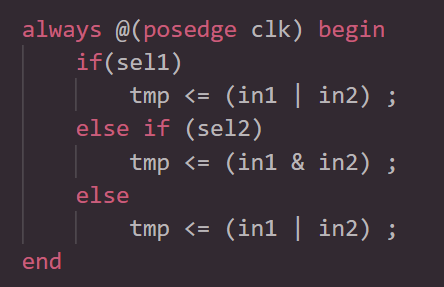
在这种情况下,在每个时钟周期仅执行一个唯一的赋值。
在上面的例子中,没有关于哪个语句会被执行赋值的歧义,因为分支控制是明确定义的。
1.5 为什么时序逻辑应该用非阻塞赋值,如果用阻塞赋值会发生什么?并且与组合逻辑进行比较。
阻塞赋值和非阻塞赋值之间的主要区别是阻塞赋值中的RHS会被立即赋值到LHS,而非阻塞赋值,LHS的赋值是发生在RHS值被计算之后。
以下说明了在时序逻辑中使用阻塞赋值和非阻塞赋值的不同场景:
1.5.1 在时序逻辑中使用阻塞赋值
以下是时序逻辑中使用阻塞赋值的Verilog模块示例:
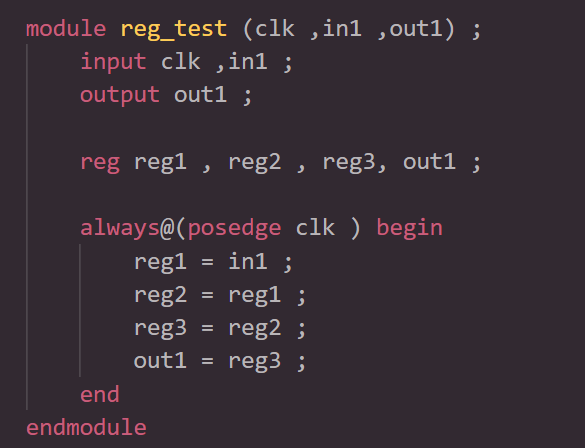
在上面的例子中,reg1,reg2,reg3,out1都是阻塞赋值。 综合结果是单个FF触发器,输入为in1,q输出为out1,如图下图所示:
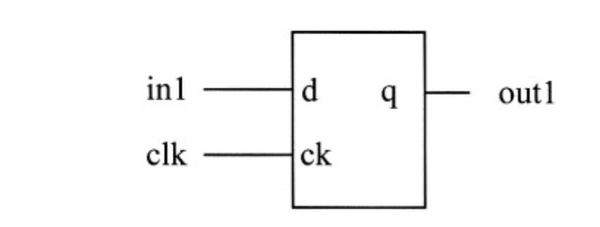
这是因为in1和out1之间的中间结果是以阻塞赋值形式存储在reg1,reg2和reg3中。 结果,对out1的RHS最终计算会被立即赋值到out1, reg1,reg2和reg3已经通过综合进行了优化。
1.5.2 在时序逻辑中使用非阻塞赋值
以下代码示例了时序逻辑中使用非阻塞赋值:
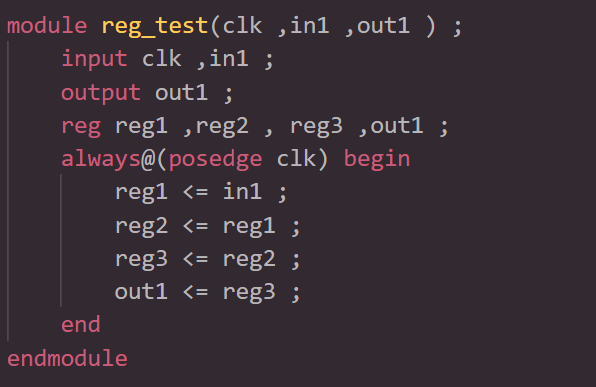
在上面的例子中,reg1,reg2,reg3,out1为非阻塞赋值。 综合结果为4个触发器。
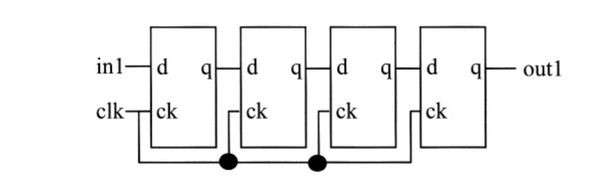
这是因为in1和out1之间的中间结果是以非阻塞赋值存储在reg1,reg2和reg3中。在这种情况下,输出是由clk事件控制的移位寄存器。
1.5.3 在组合逻辑中使用阻塞赋值
以下示例说明了组合逻辑中的阻塞赋值的用法:
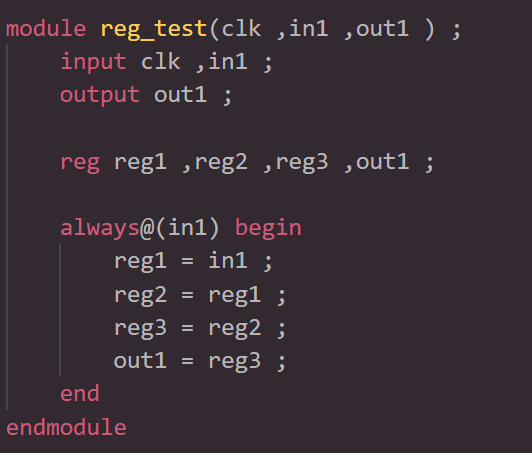
在上面的使用阻塞赋值的组合逻辑语句中,没有posedge,并且“<=”被“=”替换。 由此综合的逻辑很简单,是in1到out1之间的连线。
这是因为所有的赋值都是立即执行的,没有需要等待的事件。
2、Tasks 和Functions
Tasks 和 functions主要是有助于代码的可重用性。
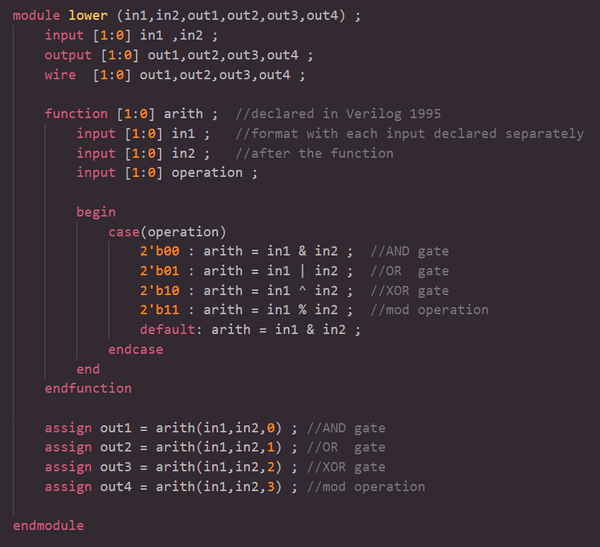
2.1 function中的逻辑被综合成了什么?
由于function中没有任何时序结构,function只能综合出组合逻辑。
例如,以下function有2个输入信号和一个控制信号,输出算术运算结果。
2.2Verilog function有哪些重要的注意事项?
2.2.1 每次调用function时,局部变量和返回值应该是都会被赋值,否则将导致形成锁存器。 例如,以下示例中,if条件语句没有else语句。也就是说,如果sel是false,该function将返回其先前调用的值,就好像结果被锁存住了。

2.2.2 fucntion只用于综合成组合逻辑。但是,fucntion的最终结果可以用作D触发器的输入。
2.2.3 fucntion不应包括延迟(#)或事件控制(@,wait)语句。
2.2.4 fucntion可以调用其他fucntion,但不能调用task。
2.2.5 fucntion在调用时会返回一个值。
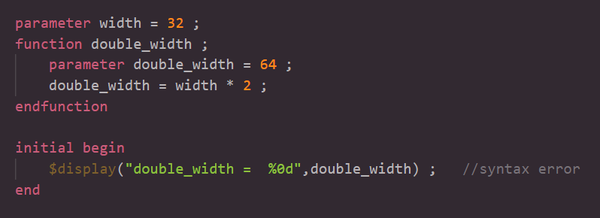
2.2.6 fucntion内声明的parameters,作用范围仅在本地,并且不能在fucntion之外使用。 在以下示例中,width参数在函数之外声明,double_width参数在函数内声明。
2.3 task中的逻辑被综合成了什么?
虽然在task中可以有@等时序控制结构中,它仅适用于仿真。综合工具会忽略所有task中的时序结构。因此,如果task中存在时序控制结构,可能会存在仿真和综合不匹配的现象。
因此,在可综合verilog中一般只会使用task综合基本的组合逻辑,在testbench中调用带有时序控制结构的task具有较好的通用性。
以下是组合逻辑task的示例,即comb_task,执行输入in1的位或(OR)。 注意int_out1和int_out2的声明是reg型,因为task的输出只能通过reg而不是wire接收。
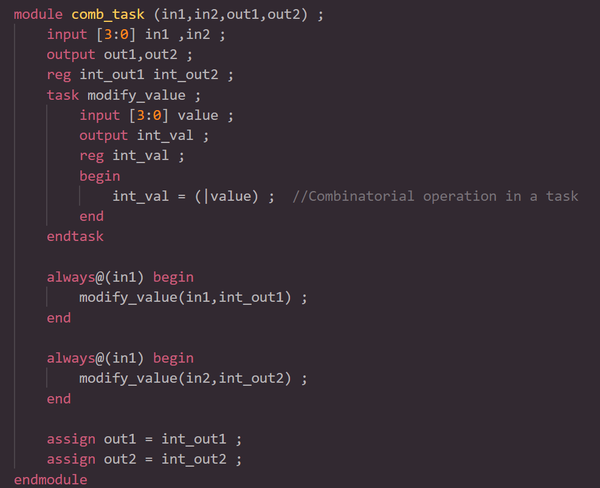
2.4 使用task和module实现可重用逻辑有什么区别?
下表总结了两种方法之间的差异:
task module
不能在task中例化module 可以在module中调用task
Task中的逻辑不能够在floorplan中定义为block进行pre_place布局,只是sea-of-gates
Module可以在floorplan中定义为block,进行pre_place
2.5 task和fucntion是否可以在module-endmodule之外声明么?
可以。 在SystemVerilog中,可以在module-endmodule外声明task和function。在Verilog-1995或Verilog-2001中是不可以的,会产生编译错误。例如,以下代码中,在module-endmodule范围之外声明了task modify_value。
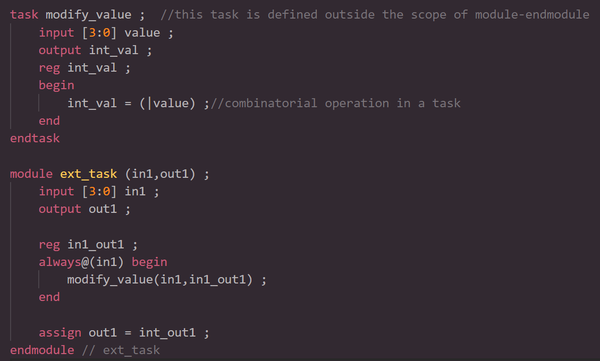
同样,在使用SystemVerilog中,function-endfunction也可以在同一文件中的module-endmodule范围之外声明。
3存储单元
在逻辑综合中可以推断出两种存储元素,即触发器和锁存器。 本节介绍这两个要素之间的实现和比较
3.1不同类型触发器的RTL模板
从RTL中综合出的触发器或锁存器的类型取决于它们的代码风格。 以下是几个不同触发器和锁存器RTL示例。 在触发器RTL中,posedge clk推断出正边沿触发器,negedge clk推断出负边沿触发器。
3.1.1 简单的D触发器
正边沿触发,无置位或复位
Module dff(clk , d,q) ;
Input clk ,d ;
Output q ;
Reg q ;
always@(posedge clk ) begin
q <= d ;
end
endmodule在SystemVerilog中,可以使用always_ff代替always实现相同的代码,如下所示:
Always_ff @(posedge clk) begin
Q<= d ;
End3.1.2 异步置位触发器
正边沿触发,高电平有效异步置位
Module asff(clk,d,set,q) ;
Input clk ,d,set ;
Ouput q ;
Reg q ;
always@(posedge clk or posedge set) begin
if(set) begin
q <= 1’b1
end
else begin
q <= d ;
end
end
endmodule3.1.3 异步复位触发器
正边沿触发,高电平有效异步复位
Module arff(clk ,d,reset,q) begin
Input clk ,d,reset ;
Output q ;
Reg q ;
always@(posedge clk or posedge reset) begin
if(reset) begin
q <= 1’b0 ;
end
else begin
q <= d ;
end
end
end3.1.4 异步置位和复位触发器
正边沿触发,高电平有效的异步置位,复位
Module arsff(clk,d,set,reset) ;
Input clk ,d,set,reset ;
Output q ;
Reg q ;
always@(posedge clk or posedge set or posedge reset) begin
if(set) begin
q <= 1’b1 ;
end
else if(reset) begin
q <= 1’b0 ;
end
else begin
q<= d ;
end
end
Endmodule3.1.5 同步置位触发器
正边沿触发,高电平有效的同步置位
Module ssff(clk , d,set,q) ;
Input clk ,d,set ;
Output q ;
Reg q ;
always@(posedge clk ) begin
if(set) begin
q <= 1’b1 ;
end
else begin
q <= d ;
end
end
endmodule3.1.6 同步复位触发器
正边沿触发,高电平有效的同步复位
Module srff(
Input clk ,d,reset ;
Output q );
Reg q ;
always@(posedge clk ) begin
if(reset) begin
q <= 1’b0 ;
end
else begin
q <= d ;
end
end
endmodule3.1.7 同步置位和赋值触发器
正边沿触发,高电平有效的同步置位和复位
Module ssrff(
Input clk ,
Input d ,
Input set ,
Input reset ,
Output q ) ;
Reg q ;
always@(posedge clk) begin
if(set) begin
q <= 1’b1 ;
end
else if(reset) begin
q <= 1’b0
end
else begin
q <= d ;
end
end3.2不同类型锁存器的RTL模板
3.2.1 简单的D锁存器
Module d1(sel ,d ,q) ;
Input sel ,d ;
Output q ;
Reg q ;
always@(*) begin
if(sel) begin
q <=d ;
end // note the else is missing
end
endmodule在systemverilog中可以用always_latch代替always,无需指定敏感列表。
Always_latch // no explicit sensitivity list
If(sel) begin
Q <= d ;
End
3.2. 2 异步置位锁存器
Module asl (sel,d,set,q) ;
Input sel ,d ,set;
Output q ;
Reg q ;
always@(*) begin
if(set) begin
q = 1’b1 ;
end
else if(sel) begin
q = d ;
end
end
endmodule- 异步复位锁存器
Module arl(sel,d,reset,q) ;
Input sel , d ,set ;
Output q ;
Reg q ;
always@(*) begin
if(reset) begin
q = 1’b0 ;
end
else if(sel) begin
q = d ;
end
end
endmodule- 异步复位置位锁存器
Module asrl(sel ,d, set,reset,q) ;
Input sel ,d,set,reset ;
Output q ;
Reg q ;
always@(*) begin
if(reset) begin
q = 1’b0 ;
end
else if(set) begin
q = 1’b1 ;
end
else if(sel) begin
q =d ;
end
end
endmodule以上所有示例都是一位存储元件。可以增加reg声明的位宽来增加触发器或锁存器的宽度。例如,
reg [3:0] out1;
这将创建4位触发器或锁存器。
触发器中异步或同步复位,哪一个更好?
异步复位:
- 复位信号不是数据路径中的一部分,不是触发器D输入的一部分
- 复位能在任何时候发生
- 不建议由内部逻辑生成异步复位
示例:
always@(posedge clk or negedge reset) begin
if(!reset) begin
out1 <= 0 ;
end
else begin
out1 <= in1 ;
end
end同步复位:
- 复位信号是数据路径的一部分
- 复位只能在时钟的有效边沿发生
- 可以由内部逻辑生成同步复位
示例:
always@(posedge clk ) begin
if(!reset) begin
out2 <= 0 ;
end
else begin
out2 <= in2 ;
end
end流程控制语句
Verilog主要有三种流程控制结构,即case,
if-else和“?:”。
本节主要说明了case和if-else结构的实现细节和问题
- 如何在case语句和嵌套if-else之间进行选择?
case和if-else都是流程控制结构。 两者在功能仿真上是类似的,但是使用场景是不同的。
通常为以下场景选择case语句:
条件是互斥的,只有一个变量控制case语句中的流程。 case变量本身可以是
不同信号的拼接。
通常在以下场景中选择多路if语句:
综合优先级编码逻辑,有多个变量控制语句流程。
使用case语句比if-else语句更具可读性,特别是用于状态机时。
在case结构中,如果未指定所有可能的case,并且缺少default语句,则会推断出锁存器。 同样,对于if-else结构,如果缺少最后的else语句,也会推断出锁存器。
如何避免if-else树中的优先级编码器?
if-else树可能会综合出优先级编码逻辑。 例如:
module priorityencoder (ino,in1,in2,in3,sel) ;
input in0 , in1,in2,in3 ;
output [1:0] sel ;
always@(in0,in1,in2,in3) begin
sel = 2’b00 ;
if(in0) sel = 2’b00 ;
else (in1) sel = 2’b01 ;
else (in2) sel = 2’b10 ;
else (in3) sel = 2’b11 ;
end
endmodule //priorityencoder如果在in0和in1都是逻辑真的,in0分支将被采用,因为in0首先计算。EDA工具将综合出优先级编码逻辑。
?:能用在连续赋值里面,而if-else只能用在initial或者always语句块中。
Case语句中default子语句的重要性是什么?
case语句中的default子语句表示除case之外的其他情况。如果缺少default子语句,则输出默认会使用保存之前的值,因此会综合出锁存器(latch)。
例如,以下case语句将生成一个latch:
Module default_latch(in1,in2,opcode,out1) ;
Input [1:0] in1,in2,opcode ;
Output [1:0] out1 ;
always@(in1 or in2 or opcode) begin
case(opcode)
2’b00 : out1 = in1 & in2 ;
2’b01: out1 = in1 | in2 ;
2’b10 : out1 = in1 ^ in2 ;
//2’b11 : out1 = in1 % in2 ;
//default : out1 = in1 & in2 ;
endcase
end
endmodule在上面,通过两行注释,会综合出锁存器。
组合逻辑和时序逻辑中的嵌套if-else实现有什么区别?
组合逻辑和时序逻辑中的always语句块中的if-else实现是不同的。
在组合逻辑中,当缺少嵌套if-else语句中的最后一个else子句时,它将推断一个锁存器,因为寄存器必须记住原来的值。例如:
Reg latch1 ;
always@(sel ,in1) begin
if(sel) latch1 <= in1 ;
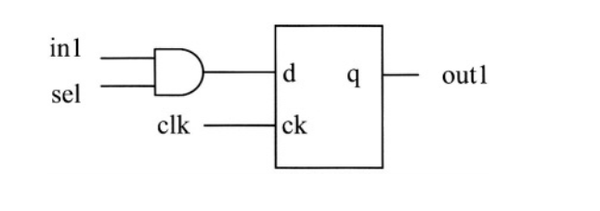
end在一个时序逻辑的always语句块中,如果最后的else语句丢失,仍然会继续推断出触发器。例如:
Reg ff1 ;
always@(posedge clk) begin
if(sel1) ff1 <= in1 ;
end上面的代码将推断出如下逻辑。触发器的D输入端是门控后的输出。
状态机
有限状态机(Finite State Machines)是设计中控制逻辑的重要部分。 本节讨论各种类型的FSM编码风格的差异。
同步状态机和异步状态机之间有什么区别?
同步状态机和异步状态机是状态机的两种基本类型。
异步状态机状态在输出信号经过一段时间延时后变化时,时间无法预测。同步状态机状态变化由时钟信号控制。
说明Mealy和Moore状态机之间的差异。
Mealy状态机和Moore状态机是两种常用的状态机编码风格。 这两种状态机的基本框图如下所示:
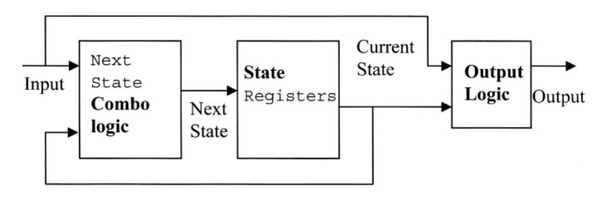
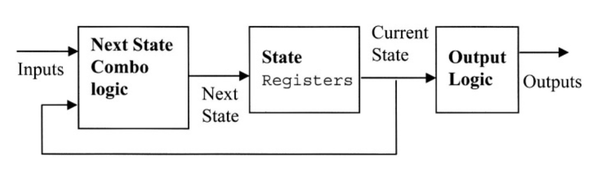
Mealy状态机输出是当前状态和输入信号的函数。
Moore状态机输出仅是当前状态的函数。
如果输入信号没有被寄存,Mealy状态机可能会有毛刺,并且组合逻辑路径比Moore状态机长。所以,Mealy状态机相对于Moore状态机可能有更低的工作频率。
说明二进制编码和onehot编码状态机之间的差异。
二进制编码需要更少的触发器,onehot编码需要的触发器和状态机状态一样多。因为输出存在组合逻辑,二进制编码时序没有onehot编码状态机好。在ASIC中,如果输出路径时序不是很关键的话,推荐使用二进制编码。在FPGA中,触发器资源较多,可以使用onehot编码。
Memory
Memory是芯片设计的重要组成部分。 Memory可以小到形成一个简单的寄存器组。随着芯片面积的增长,芯片中的Memory越来越多。本节讨论综合出设计中Memory的多维数组的含义和选择来自工艺厂商Memory的一些需要考虑的因素。
如何实现多维数组。
Memory可以由综合工具直接根据数组结构综合出来。以下是用于综合出小型存储器的实例 RTL代码。
Module my_memory (datai,datao,clk,wr_n,addr) ;
Parameter width = 4 ;
Parameter log2_depth = 16 ;
Input [width-1 : 0] datai ,addr ;
Input clk ,wr_n,rd_n ;
Output [width-1 :0] datao ;
Reg [width-1 :0] memory [log2_depth -1 :0] ;
Reg [width -1 : 0 ] datao ;
always@(posedge clk) begin
if(wr_n == 1’b0) memory[addr] <= datai ;
else if(rd_n == 1’b0) datao <= memory[addr] ; //Synchronous read
end
endmodule //my_module上述代码会综合出64个根据地址索引的触发器。
Verilog-2001引入了多维存储器。上面的例子可以扩展到三个维度,即x,y和z,如下:
Module my_memory(datai , datao , clk ,wr_n ,addr_x , addr_y ,addr_z) begin
Parameter width = 4 ;
Parameter log2_d = 4 ;
Input [width -1 : 0] datai , addr_x ,addr_y , addr_z ;
Input clk ,wr_n ,rd_n ;
Output [width -1 : 0] datao ;
Reg [width-1 :0] memory [log2_d -1 : 0 ] //addr_x
[log2_d -1 : 0 ] //addr_y
[log2_d -1 : 0 ] ; //addr_z
Reg [width-1 : 0] datao ;
always@(posedge clk) begin
if(wr_n == 1’b0 ) memory[addr_x][addr_y][addr_z] <= datai ;
else if(rd_n == 1’b0) datao <= memory[addr_x][addr_y][addr_z] ;
end
end上面的多维数组最终会被合成x * y * z * width=4 * 4 * 4 * 4= 256个单独的触发器。
使用来自半导体供应商的硬核memory会有更好的时序,面积和功耗,因为它的逻辑是经过优化的,而不是使用离散逻辑。
但是,例化一个工艺相关的memory将使得该设计在不同工艺下不可重用。所以,我们应该在顶层用一个wrapper实例化设计和memory,而不是在设计中实例化memory。
实例化工艺相关的memory有哪些需要考虑的因素?
根据应用,memory的选择基于在以下性能参数上:
面积:如果该芯片,面积是主要关注点,那么就需要高密度的memory。通常而言,面积还取决于memory的工艺。
频率:如果速度是主要关注点,那么就需要高速的memory。
功耗:这是低电压和低功耗应用的关键问题之一。此外,如果功耗变高,则整个系统的性能变得更低。它还增加了最终的封装成本。
还需要考虑memory的其他设计变量:
memory容量:例如,将memory指定为512Kbits。
电压:某些memory是针对特定电压范围而设计的。
同步或异步:指定memory是否具有同步读/写或异步读/写。使用哪一个主要取决于是否存在时钟和匹配设计的时序要求。
单端口或多端口:确定memory是否由单个或多个读/写端口访问。使用多端口memory的一个关键问题是多个端口正在尝试写入相同地址的memory会发生什么问题。
触发器或基于锁存器:确定memory内的基本单元是否是基于触发器或者锁存器。
这种memory的重要考虑因素是可测试性和功耗。基于触发器的设计比基于锁存器更容易测试。随着memory大小的增加,memory的可扫描性是重要的标准。许多供应商都提供了BIST逻辑,使memory可扫描。
代码风格
以下要点总结了设计阶段的主要考虑因素:
寄存关键模块的所有输出。这将使得在系统级集成期间,接口时序很容易满足
根据时钟域和功能目标,对设计进行划分(Partition)
遵循命名约定,便于以后的维护。
避免实例化特定工艺的门
在设计中使用参数化代码
避免在设计内部生成时钟和复位
在顶层的模块实例化时避免使用胶合逻辑(glue logic)
2.7.2什么是“snake”路径,为什么要避免它们?
一条snake路径,就是一条穿越多个层次的路径。
设计中必须避免使用snake路径,原因如下:
在对顶层进行静态时序分析时,它将构成一个很长的时序路径。但是,在模块级的静态时序分析时可能不会被发现。
综合工具需要付出更多努力来优化跨层次的时序路径,同时增加综合时间。
为了避免snake路径:
寄存不同功能模块的输出。
在功能上划分设计,以避免跨越层次结构的过长的时序路径。
定期在集成后的,即使没有完全通过验证的设计中执行综合,检查是否存在snake路径。这将通过时序报告提供早期的反馈。
划分设计时有哪些注意事项?
大型设计需要以分层的方式处理。在划分这些设计时需要考虑以下因素:
功能:层次结构中逻辑的功能是划分设计的主要标准。典型层次结构的划分是:
地址和数据路径:此模块通常包含地址和数据寄存器,用于驱动总线的地址和数据。
控制逻辑:该模块通常包含有限状态机器(FSM)
时钟域:在多时钟设计中,建议将同一个时钟域中的模块划分在单个模块。当信号需要与不同时钟域中的模块进行交互时,需要通过一个同步模块,它将源时钟域中的信号同步到目的时钟域。
面积:模块中的逻辑太少会产生太多的层次结构,单个模块中的逻辑过多会在以后的Floorplan期间产生问题。
跨时钟域设计考虑因素
虽然每个模块都功能正常,但更重要的是模块间信号通信是否可靠。
在这方面,同步设计相当有优势。但是大多数设计都存在多个时钟。信号跨时钟域通信的可靠性变得越来越具有挑战性。本文讨论了信号跨越时钟域时要考虑的几个问题,以及如何提高可靠性。
如何跨时钟域可靠地传达控制信息?
当控制信号穿过时钟域时,信号相对于目标时钟域为异步输入。因此,该信号需要同步以满足目的时钟域的建立和保持要求,否则触发器会进入亚稳态。
常用方法之一是在源时钟域和目标时钟域之间采用两级触发器同步器。 如果第一个触发器进入亚稳态,那么第一个触发器中的Q值是未知的,即1或0(仿真中的“x”)。
通过串联两个触发器,第二个触发器总能确保捕获第一个触发器的输出作为稳定数据。
以下是2级同步器。 请注意,数据来自源时钟clk1,而两个触发器由clk2驱动。
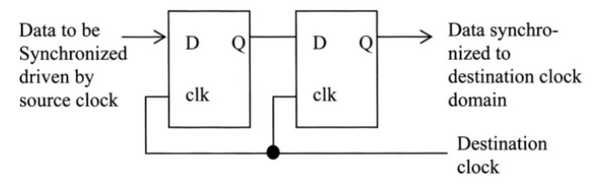
一些工艺厂商和IP供应商甚至还有用于同步目的的特殊优化单元。 虽然这些单元有更少的建立和保持时间要求,但是面积可能比正常的触发器大,也消耗更多的功耗。 同时,实例化特定工艺的门会使设计的重用性较差。在这种情况下,建议使用两个触发器定义一个同步模块,并在设计中实例化它们。
上述同步器只能处理目标时钟可以采样到的足够长的电平信号。 如果脉冲信号宽度小于目标时钟周期,上面的同步器就没有用。
传输跨时钟域的,不同总线宽度数据的安全策略是什么?
当需要跨时钟域传输不同总线宽度的数据时,FIFO(First In First Out,先进先出)是理想的组件。 如果总线写入(将数据推入FIFO)和读取(从FIFO中弹出数据)之间的宽度是不同的,则需要一个不对称的FIFO。 许多工艺厂商的库中都有非对称FIFO。如下图所示:
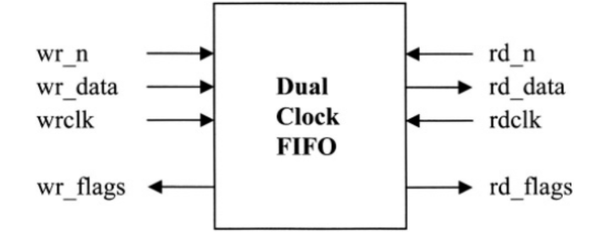
上面FIFO中的标志通常是full, empty, almost-full 和almost-empty.。FIFO的阈值可以设置为输入信号或作为实例化参数。 wr_data和rd_data的宽度
可以是不同的,但通常是整数倍的关系。
可综合RTL中常见的“陷阱”
本文介绍了一些代码中可能存在的可综合 “陷阱”。
2.9.1只有输入,没有输出的模块将会综合成什么?
仅有输入且无输出的模块将会被综合成没有逻辑的模块。
2.9.2为什么在综合出的逻辑中看到锁存器?
有很多原因会导致在综合出的逻辑中存在锁存器。通常在综合工具的日志中都有详细的说明。
1、always语句块中的if-else子句没有最终的else子句,并且没有初始值。
2、case语句块中没有default子句,并且在进入case语句块中没有被赋初始默认值。
2.9.3什么是“组合时序环(combinatorial timing loops)”?为什么要避免?
combinatorial timing loops是指一个门或者很长的组合逻辑输出被反馈作为其中一个门的输入。这些路径通常是由于大的组合逻辑块中一个信号驱动同一个组合逻辑块中的另一个信号。
这些组合反馈回路是不被需要的:
1、由于组合反馈回路中没有时钟来打断路径,所以组合逻辑环将无限振荡
,其占空比取决于组合路径上的延迟。例如,以下代码是组合逻辑环:
assign out1 = out1 & in1 ;
这将导致out1作为其中一个组合逻辑输入。
这些循环会导致可测试性的问题。
可以通过以下手段在早期发现组合逻辑环:
1、在使用HDL语言设计过程中定期使用linting工具。
这是迄今为止,捕获和修复组合逻辑循环的最佳和最简单的方法。
- 在功能仿真期间,期望的输出行为没有出现在输出中,或者仿真根本没有进行,因为仿真器停止在组合逻辑环了。
- 如果在仿真期间未检测到组合逻辑环路,许多综合工具都具有合适的报告命令,用于检测组合逻辑环的存在。
综合工具会打破关键路径分析的循环时序弧,然后继续进行静态时序分析。
2.9.4组合always语句块中的敏感列表如何影响综合前后的仿真?
在Verilog-1995中,在综合和仿真之间, RHS中的所有元素都应该作为组合逻辑always语句块的敏感列表的一部分。
虽然综合工具会根据不在敏感列表中的变量继续综合,但是仿真工具将忽略不在敏感列表中的变量的变化。结果是,功能仿真和综合后仿真的行为是不同的。
通常,文本编辑器(如具有Verilog语言模式的emacs)能够自动推断出正确的敏感列表变量,并自动将其添加到敏感列表中。 Linting工具也会在解析期间提供错误消息
从Verilog-2001开始,这不再是一个问题。@(*)添加了所有的变量到敏感列表。例如,将RHS的所有元素都添加到敏感列表中:
在Verilog-1995中:
always@(in1 or in2 or in3 or in4) begin
out1 = (in1 ^ in2) & (in3 | in4) ;
end在Verilog-2001中:
//note the use of “,”in the place of ”or”
always@(in1,in2,in3,in4) begin
out1 = (in1 ^ in2) & (in3 | in4) ;
end
or
//note the use of “*”
always@(*) begin
out1 = (in1 ^ in2) & (in3 | in4) ;
end
在SystemVerilog中可以使用always_comb,如下:
Always_comb
Begin
out1 = (in1 ^ in2) & (in3 | in4) ;
end此时,代码更加简单,也更易于维护。
RTL代码,让你的芯片更小
本文描述了一个优化软核面积的 RTL编码技术。优化掉不需要的逻辑不仅减少了芯片面积,还减少了电路的开关活动,因此也减少了功耗。
`ifdef,`ifndef,`elsif,`endif结构如何帮助最小化面积?
以下是如何使用编译器指令最小化逻辑设计面积的示例:
`define MIN
Module area_min_byifdef(in1,in2,in3,in4,out1) ;
Input in1 ,in2 ,in3 ,in4;
Output out1 ;
`ifdef MIN
Assign out1 = in1 & in2 ; // minimal area
`else //large area
Assign out1 = (in1 & in2) | (in3 ^ in4) ;
`endif
Endmodule使用编译器指令可以选择适当的模块。在以下代码中,使用编译器指令选择正确类型的计数器,即ripple 计数器和carry lookahead 计数器。
//`define CLA
Module area_min_by_ifdef (a.b,c,sum,cout) ;
Input a,b,c ;
Output sum,cout ;
`ifndef CLA
Ripple_adder U_ripple (
.in1(a) ,
.in2(b) ,
.in3(c) ,
.sum(sum) ,
.cout(cout)
) ; // smaller area , longer timing
`else
cla_adder U_cla (
.in1(a) ,
.in2(b) ,
.in3(c) ,
.sum(sum) ,
.cout(cout)
) ; // larger area , faster timing
`endif
Endmodule在上面的例子中,`ifndef是指缺少CLA的`define。
因此,使用这种方法中,来选择适当的代码去实现你的电路功能。
声明一些reg位,但不赋值和使用会发生什么?
当声明一些reg位,但不赋值和使用时,对应于那些位的逻辑会被优化掉。 例如,在下面的代码中,虽然声明了int_tmp,但是2:1位是未使用的。 该代码将综合出int_tmp [3]和int_tmp [0]相关的逻辑, tmp [2:1] 相关的逻辑会被优化掉。
Module lower(in1,in1,clk,reset,out1 );
Input in1 ,in2 ;
Input clk ,reset ;
Output [1:0] out1 ;
Reg [3:0] int_tmp ;
always@(posedge clk or negedge reset) begin
if(!reset) int_tmp <= 0 ;
else begin
//Only bits 0 and 3 are used .
//Bits [2:1] are not assigned
Int_tmp[0] <= in1 ;
Int_tmp[3] <= in2;
end
end
endmoduleRTL时序优化
当一个设计被综合成网表后,路径中的门延迟和走线延迟等会对芯片的整体性能有影响。在设计的早期即模块划分和功能设计阶段,就应该考虑到时序的影响。在功能验证时考虑时序的影响就太晚了。
设计中的关键路径(critical path)是什么?理解关键路径的重点是什么?
关键路径是通过具有最小slack的电路时序路径。它不一定是设计中最长的路径。在一个设计中可以有不止一个关键路径。所有路径中到达时间(arrival)和要求时间(required)之差为负值时,该路径是一条违例路径(violating path)。
理解和识别设计中的关键路径:
1、它有助于修复静态时序问题,特别是建立时间违例的关键路径
2、缩短关键路径延迟可以提高频率,和芯片的性能。
如果在设计流程的早期就确定了关键路径,可以适当地进行功能更改来缩短关键路径延迟。考虑到路径中触发器的插入,会增加设计中的latency。
如果关键路径来自模块中的输入端口,建议寄存输入。虽然这会增加latency,但有助于提高设计工作的频率。
如何适当地划分设计以实现更好的静态时序?
正确地划分设计,在设计的多个阶段,直到后端流程都有帮助。在编写HDL代码之前就需要对设计进行划分。
以下是一些设计划分的建议:
1.逻辑划分:通常我们会根据逻辑相关性来划分设计。例如,数据路径、控制模块(FSMs)、存储器和I / O。模块划分有助于多个团队成员进行模块级验证,和项目管理、版本控制。通常,模块大小应该在大约5 k门左右。
在逻辑划分时,寄存输出关键模块的输出将大大减少长组合逻辑路径和跨越多个层次的组合逻辑路径,因此会有更好的静态时序分析结果。
对于特别的逻辑,如I/O、复位、时钟应该位于单独的模块中。
2、根据时钟域划分:按照相同的时钟域进行逻辑划分在综合、静态时序分析中起着重要的作用,并且需要在跨时钟域间的同步模块中定义false path。
寄存器之间的“retime”是什么意思?
retime是指保持设计功能行为的情况下,改变寄存器位置的过程。
retime有助于平衡流水线之间关键路径的路径延时,但是retime之后的形式验证可能与原来的设计不同。
为什么在高速设计中,FSM首选one-hot编码?
由于one-hot编码的每个状态存在一个显式的触发器状态,不需要输出状态解码。 因此,触发器的clock to q延迟是唯一的延迟。 这使得one-hot编码适合用于高速设计
可测性设计(DFT)
可测试性(DFT)用来确保设计最终是可以测试的。DFT在增加故障覆盖率(fault coverage)的同时也增加了面积。
影响设计可测试性的主要因素是什么?
1、设计中存在三态总线
2、由一个触发器的输出驱动另一个触发器的复位
3、设计中存在生成时钟
4、设计中存在门控时钟
5、设计中存在锁存器
芯片上片上三态总线对可测试性有什么影响,该如何处理它?
通常,芯片内不应存在三态总线,因为它们消耗更多的功耗。如果芯片上存在三态总线,应注意避免总线竞争,即同一时间在总线上驱动不同的值。总线冲突会消耗更多的功耗,进而导致芯片损坏。 在扫描测试阶段避免总线竞争的途径是控制三态缓冲器的使能,即与扫描使能信号进行“与”运算。
在正常工作模式,scan_en_n信号为逻辑“1”,允许控制信号通过。
在测试模式下,scan_en_n信号为逻辑“0”假定这些使能的控制输入来自触发器的输出。 如下图所示:
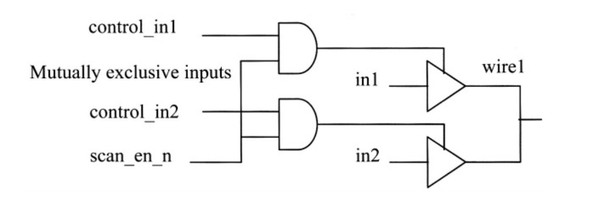
这些缓冲器的Verilog示例代码如下所示:
Assign wire1 = (control_in1 & ~scan_en_n) ? in1 : 1’bz ;
Assign wire1 = (control_in2 & ~scan_en_n) ? in2 : 1’bz ; 芯片中的一些触发器的复位由其他触发器驱动对可测试性有什么影响,该如何处理它?
通常,触发器的异步置位或复位来自模块和设计的输入引脚。有时候,不可避免地由一个触发器的输出驱动另一个触发器的异步置位/复位。在这种情况下,在扫描测试期间,如果驱动触发器获得一个测试向量,使其复位另一个触发器,则会发生功能错误。 为防止这种情况,复位信号应该和test_mode测试模式信号异或。如下图所示:
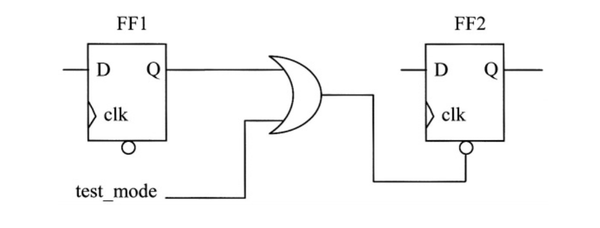
在正常工作模式, test_mode为1'b0。但是,在测试期间,test_mode信号为1'b1,从而使异步复位失效。
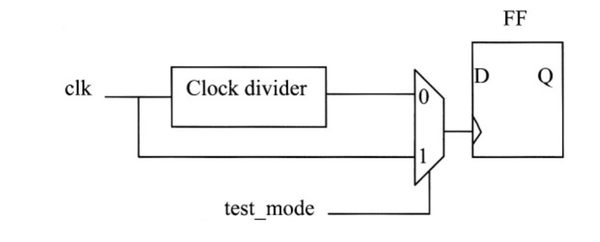
芯片中存在生成时钟对可测试性有什么影响,该如何处理它?
生成时钟由时钟分频器通过触发器或芯片中的PLL产生。
在这种情况下,需要在时钟路径中添加多路复用器,使用test_mode作为控制信号,多路复用器的输入是常规时钟和生成时钟。
芯片中有门控时钟对可测试性有什么影响,该如何处理它?
在某些设计中,门控时钟是不可避免的,它可以用来降低功耗。 因为时钟现在通过组合逻辑,从而无法扫描测试。
解决方法如下:
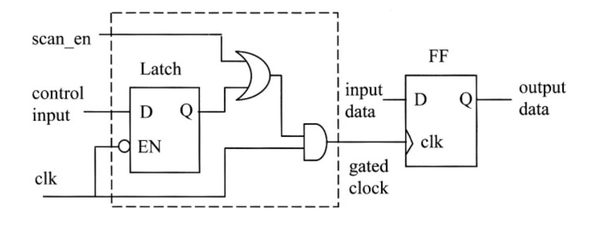
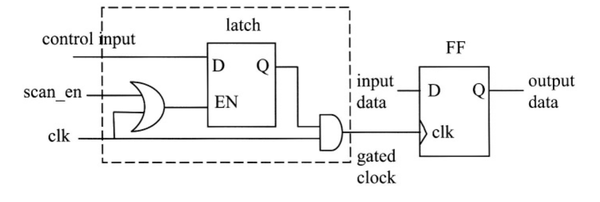
组合反馈逻辑对可测试性有什么影响,该如何处理它?
在任何设计的任何阶段都应该避免存在组合逻辑反馈。我们应该使用lint和综合工具定期地检查。组合逻辑反馈电路的存在会导致设计中不可预测的逻辑行为。 由于组合逻辑环的行为依赖于延迟,我们无法使用任何ATPG算法进行测试。 因此,在逻辑上应该避免组合逻辑环。
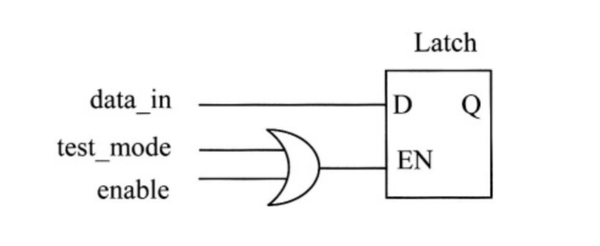
锁存器对可测试性有什么影响,该如何处理它?
为了使锁存器具有可控性,需要使能和测试模式信号进行异或。如下图
所示:
低功耗
低功耗是当今大多数芯片的关键要求。 芯片的功耗越大,设备就会越热
,运行速度越慢。并且在高温下,芯片的可靠性会降低。 本文讨论如何在RTL级对功耗进行优化。
在RTL编码期间可以有哪些方法降低功耗?
在芯片逻辑转换期间,CMOS电路中的任何开关活动都会产生瞬时电流,因此增加了功耗。
设计中最常见的存储元件是同步触发器,它的输出会在输入数据和时钟改变时改变。 因此,如果输入数据和时钟只有在需要时才存在或者触发就可以减少
电路信号开关活动,降低功耗。 以下总结了一些降低功耗的机制:
1、减少输入数据的切换。
2、减少触发器的时钟切换。
3、减小芯片面积,因为可以减少门/触发器的开关切换。
以下深入讨论了在RTL中实现的问题:
如何减少触发器的输入数据切换来降低功耗?
对于相对于时钟很少更新的触发器来说,应该仅在合适的时候更新触发器,避免触发器输出没有必要的更新。
这可以通过使能触发器实现,如下图所示:
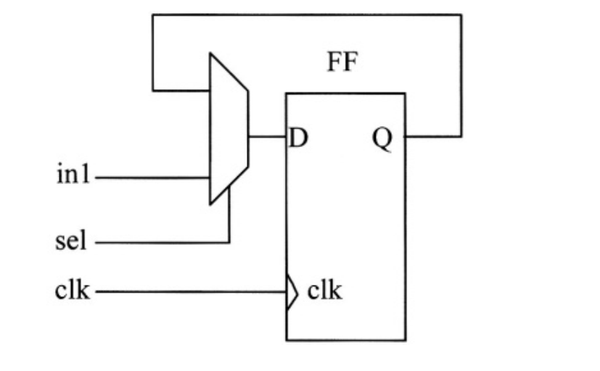
实现使能触发器的Verilog RTL的示例如下:
Module enable_ff(
Clk ,
Sel ,
Reset_n ,
In1 ,
out1 );
input clk ,reset_n,sel ,in1 ;
outpu out1 ;
reg out1 ;
always@(posedge clk or negedge reset_n) begin
if(!reset_n) begin
out1 <= 1’b0 ;
end
else if(sel) begin
out1 <= in1 ;
end
else out1 <= out1 ;
end
endmodule通过遵循上述的编码风格来降低功耗是不够的,因为它有一个缺点:
尽管使用使能触发器可以减少数据切换,但是它引入了额外的逻辑到触发器的
D输入,可能会增加关键路径的延迟。
另一个副作用是,会增加芯片的面积。
时钟门控如何减少功耗
时钟门控是节省功耗最常用的机制。 这种技术通过以下方式减少触发器输出的切换:
1、无需在寄存器中重新加载相同的值
2、降低时钟网络功耗。
时钟门控最常用的方法是使用锁存器
和一个门,如下图:
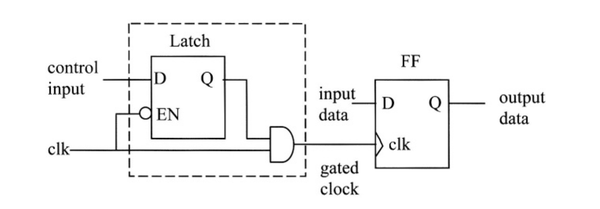
当clk处于低电平时,锁存器被使能。如果输入控制信号为高,则Q在时钟低电平时为高电平,并保持不变直到下一个clk的低电平。
电路中的锁存器输出很容易满足触发器的建立时间要求。当输入控制信号为低电平时,会阻止了clk的传播。这使得门控时钟网络没有任何转换活动。
一个简单的Verilog代码可以描述上述逻辑,如下:
Module gated_ff(in1 , cntrl_in , clk ,reset_n , out1 ) ;
Input cntrl_in , in1 ,reset_n ;
Output out1 ;
Wire gated_clk ;
Reg d_latch , out1 ;
always@(cntrl_in , clk ) begin
if(!clk) d_latch <= cntrl_in ;
end
assign gated_clk = d_latch & clk ;
always@(posedge clk or negedge reset_n) begin
if(reset_n) begin
out1 <= 1’b0 ;
end
else begin
out1 <= in1 ;
end
end
endmodule在大型设计中门控时钟都是通过综合工具完成的,无需手动实现。
此外,门控元件AND门可以根据使能的逻辑电平和触发器边沿触发类型改变。
锁存器时钟门控有哪些副作用,如何去修复?
虽然使用锁存器时钟门控是一种很好的降低功耗方法,但是它引入了可测试性问题。 因为使用锁存器门控时钟时,时钟信号现在仅受输入控制信号的控制。在
测试时,如果此信号为低,则时钟信号无法传播。
要解决上述问题,需要添加其他逻辑增强可测试性。一种方法时钟是在锁存器的输入端引入一个控制逻辑,使锁存器在扫描测试期间处于“使能”状态。 如下图所示:
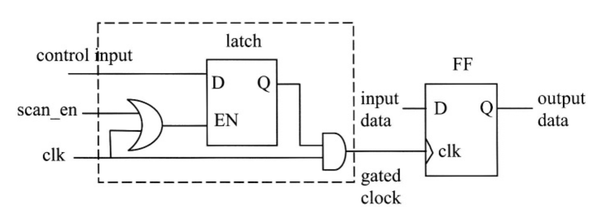
一个简单的Verilog代码可以描述上述逻辑,如下:
Module gated_ff (in1 , scan_en ,clk , reset_n , cntrl_in , out1) ;
Input scan_en , in1 ,clk , reset_n , cntrl_in ;
Output out1 ;
wire gated_clk ,latch_en ;
reg d_latch , out1 ;
assign latch_en = scan_en | clk ;
always@(cntrl_in , latch_en ) begin
if(latch_en) d_latch <= cntrl_in ;
end
assign gated_clk = d_latch & clk ;
always@(posedge gated_clk or negedge reset_n) begin
if(!reset_n) out1 <= 1’b0 ;
else out1 <= in1 ;
end
endmodule在大型设计中,上述逻辑可以通过综合工具完成的,无需手动实现。
在RTL设计阶段还有其他的低功耗设计技术么?
- 高频信号通过尽可能少的逻辑。一些必要的逻辑在高频下运行,其余逻辑可以相对较低的频率下运行。
- 仅使用必要数量的触发器来存储数据值,即如果仅使用32位寄存器的4位,则不需要剩下的28位寄存器。通常,未使用的触发器会综合工具优化掉
- 使用芯片片选信号。来自CPU的地址不断变化,不会一直指向所有的模块。在这种情况下,最好在各个模块根据地址译码生成一个片选信号,以减少
不必要的信号切换。
4、状态机选择格雷码而不是二进制编码:
由于格雷码转换只有一位发生变化,因此触发器切换以及它所驱动的逻辑的切换都会减少。但是,格雷码比二进制编码需要更多的触发器。
5、使用多路复用器而不是片上三态总线,因为三态总线可能会发生总线竞争,此时会导致内部总线短路。多路复用器的选择避免了总线竞争,但会增加逻辑门的数量。三态总线还需要内部上拉电阻和更高的电流驱动。
除RTL级外,有哪些系统级技术,影响芯片的功耗?
1、降低工作电压:功耗和电压的平方成正比,在较低的电压下工作
一种降低功耗的方法。许多工艺厂商都有专为低功耗而设计的库。
- 降低工作频率:功耗和频率成正比。设计可以考虑在较低的频率下工作,然后增加总线宽度,以维持数据速率要求。例如, 100MHz的32位总线的数据传输与50MHz的64位总线相同。
- 降低走线的电容。
在后端分析阶段,可以采用哪些降低功耗的技术?
以下是后端阶段需要关心的,显著影响整体功耗的几个参数:
1、功耗和时序敏感的逻辑走线更短:因为走线电容是长度,宽度和阻抗的函数,长的走线路径通常具有更高的电容。 由于动态功耗与电容成比例,即电容越低
功耗越低。所以,逻辑块需要彼此相互接近

 浙公网安备 33010602011771号
浙公网安备 33010602011771号