关于正则表达式:
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
| 代码/语法 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| 名称 | 说明 |
|---|---|
| IgnoreCase(忽略大小写) | 匹配时不区分大小写。 |
| Multiline(多行模式) | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| ExplicitCapture(显式捕获) | 仅捕获已被显式命名的组。 |
| 代码/语法 | 说明 |
|---|---|
| \a | 报警字符(打印它的效果是电脑嘀一声) |
| \b | 通常是单词分界位置,但如果在字符类里使用代表退格 |
| \t | 制表符,Tab |
| \r | 回车 |
| \v | 竖向制表符 |
| \f | 换页符 |
| \n | 换行符 |
| \e | Escape |
| \0nn | ASCII代码中八进制代码为nn的字符 |
| \xnn | ASCII代码中十六进制代码为nn的字符 |
| \unnnn | Unicode代码中十六进制代码为nnnn的字符 |
| \cN | ASCII控制字符。比如\cC代表Ctrl+C |
| \A | 字符串开头(类似^,但不受处理多行选项的影响) |
| \Z | 字符串结尾或行尾(不受处理多行选项的影响) |
| \z | 字符串结尾(类似$,但不受处理多行选项的影响) |
| \G | 当前搜索的开头 |
| \p{name} | Unicode中命名为name的字符类,例如\p{IsGreek} |
| (?>exp) | 贪婪子表达式 |
| (?<x>-<y>exp) | 平衡组 |
| (?im-nsx:exp) | 在子表达式exp中改变处理选项 |
| (?im-nsx) | 为表达式后面的部分改变处理选项 |
| (?(exp)yes|no) | 把exp当作零宽正向先行断言,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no |
| (?(exp)yes) | 同上,只是使用空表达式作为no |
| (?(name)yes|no) | 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no |
| (?(name)yes) | 同上,只是使用空表达式作为no |
这几个表引自http://www.jb51.net/tools/zhengze.html#getstarted
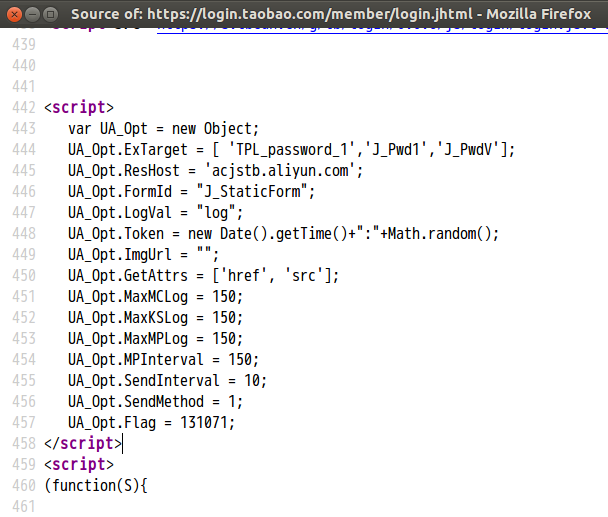
下面以获取淘宝登录页面(https://login.taobao.com/member/login.jhtml)的一个js方法为例:
如下所示,取UA_Opt的定义这一段内容.
package com.amos; import org.apache.http.HttpResponse; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.DefaultHttpClient; import org.apache.http.util.EntityUtils; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Test{ //main方法: public static void main(String args[]){ HttpClient httpClient = new DefaultHttpClient(); String loginURL = "https://login.taobao.com/member/login.jhtml"; HttpGet httpGet = new HttpGet(loginURL); HttpResponse loginResponse = httpClient.execute(httpGet); String loginString = EntityUtils.toString(loginResponse.getEntity()); System.out.println("loginString:\n"+loginString); Matcher matcher = Pattern.compile("var UA_Opt =(.*?)</script>").matcher(loginString.replaceAll("\\r|\\t|\\n|\\a","")); while(matcher.find()){ System.out.println(matcher.group(1)); } httpGet.releaseConnection(); }
}
注意上面的表格4的内容,这里用的就是上面的方法.
使用java截取js方法,首先,将换行符制表符回车符报警符都替换掉(loginString.replaceAll("\\r|\\t|\\n|\\a","")),这样在截取时就不会出问题了
截取的时候"var UA_Opt =(.*?)</script>",中间的(.*?)表示匹配任何内容,然后是以var UA_Opt=开的头,然后以</script>标签结尾,取到的内容,再以matcher.group(1),即取到了我们所需要的内容.
注意空格不要被替换掉了,不然一堆字符串就看的眼花了,最终的结果为:

new Object; UA_Opt.ExTarget = [ 'TPL_password_1','J_Pwd1','J_PwdV']; UA_Opt.ResHost = 'acjstb.aliyun.com'; UA_Opt.FormId = "J_StaticForm"; UA_Opt.LogVal = "log"; UA_Opt.Token = new Date().getTime()+":"+Math.random(); UA_Opt.ImgUrl = ""; UA_Opt.GetAttrs = ['href', 'src']; UA_Opt.MaxMCLog = 150; UA_Opt.MaxKSLog = 150; UA_Opt.MaxMPLog = 150; UA_Opt.MPInterval = 150; UA_Opt.SendInterval = 10; UA_Opt.SendMethod = 1; UA_Opt.Flag = 131071;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号