Python:电子商务网站用户行为分析及服务推荐,数据库操作、协同过滤算法
问题描述
本文主要研究对象是北京某家法律网站,这是家电子商务类大型法律资讯网站,致力为用户提供丰富的法律信息与专业咨询服务,也为律师与律所提供有效的互联网整合营销解决方案,访问量剧增,数据信息量也大幅增长,面对大量信息用户无法及时从中获得自己需要的信息,信息使用效率越来越低;低效的信息供给是无法满足用户需求的,容易流失客户,基于此背景寻求用户行为分析及服务推荐系统开发。
问题目标分析
- (1) 网站用户行为分析,挖掘各种行为特征(针对用户群整体、分群),如访问量、访问页面类别、点击次数、停留时间等
- (2)根据用户访问需求特征(习惯),更加高效、人性化的服务推荐(推荐高关联度的、热门的、未浏览过的等)
本文代码略长,主要在数据分析即用户行为分析花费时间较多,且书中代码不全,本文中代码来自整理网上资源和自编。
分析思路、步骤及代码
数据入库
可用文的MariaDB也可用MySQL5.6,直接把数据导入,数据库取数
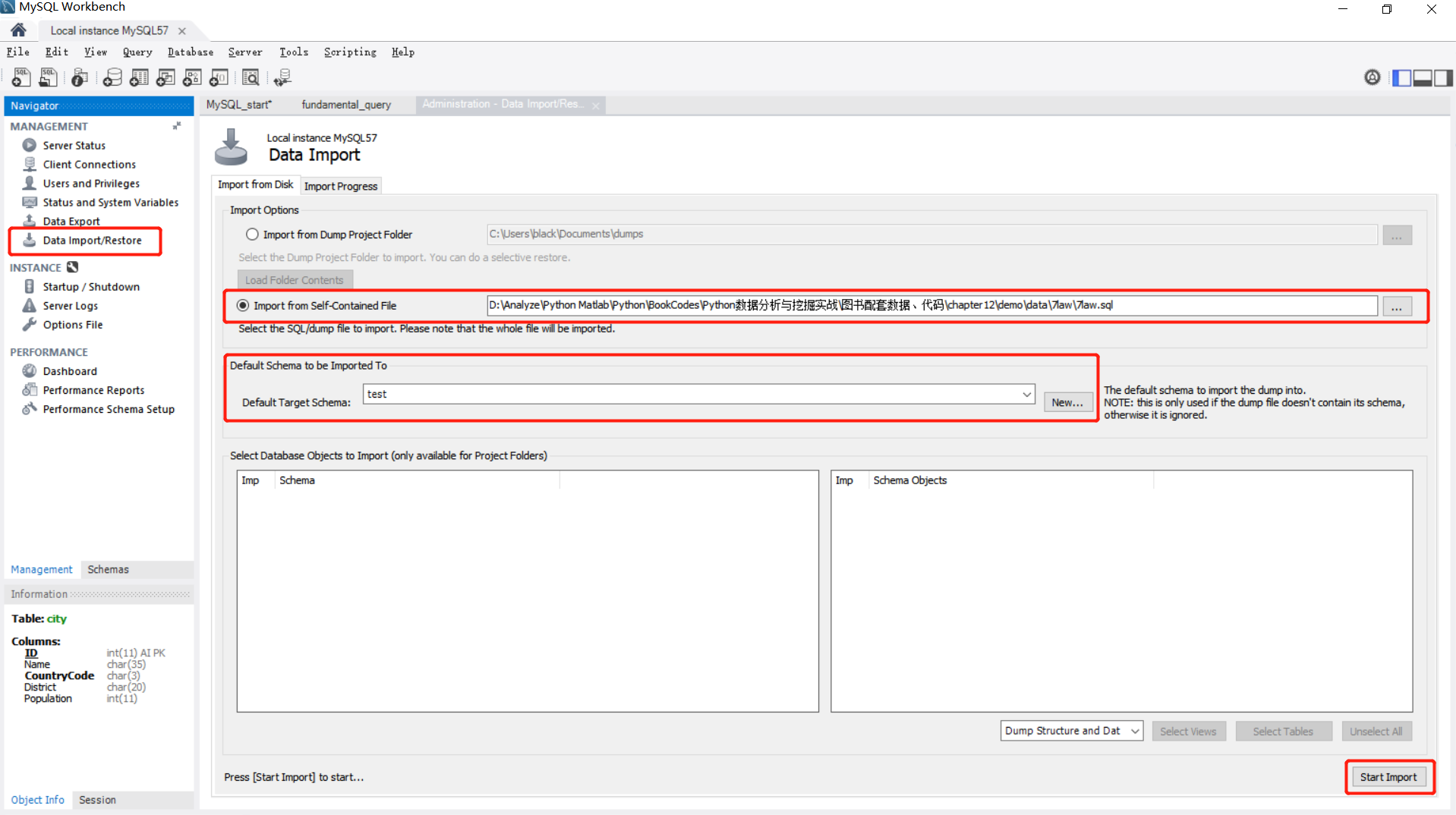
1 import pandas as pd 2 from sqlalchemy import create_engine 3 import matplotlib.pyplot as plt 4 import re 5 import numpy as np 6 import time 7 8 9 engine=create_engine('mysql+pymysql://root:****@localhost:3306/test') # ****数据库的密码 10 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 11 12 counts1=[i['fullURLId'].value_counts() for i in sql] # counts1此时是个列表 13 counts1 14 counts1=pd.concat(counts1).groupby(level=0).sum() # 由于sql分块的 上面counts1也是,concat纵向向链接 15 counts1=counts1.reset_index() 16 counts1.columns=['index','num'] 17 counts1['type']=counts1['index'].str.extract('(\d{3})',expand=True) 18 counts1.head() 19 counts1_=counts1[['type','num']].groupby('type').sum() 20 counts1_.sort_values(by='num',ascending=False,inplace=True) 21 counts1_['percentage']=(counts1_['num']/counts1_['num'].sum())*100 22 counts1_.head() 23 # 以上是区分URLId 查看用户浏览习惯,那个浏览较多 24 # 保存生成的表可用 pd.to_csv()/pd.to_excel(),以下不赘述 25 26 a=counts1.set_index('type') 27 b=counts1.groupby('type').sum() 28 c=pd.merge(a,b,left_index=True,right_index=True)# 均以行索引为链接键 合并 29 c['percentage']=(c['num_x']/c['num_y'])*100 30 c.head() 31 c.reset_index(inplace=True) # inplace是否改变自身,True则改变原数据 32 d=c.sort_values(by=['type','percentage'],ascending=[True,False]).reset_index() 33 d.head() # 常见到groupby中level=0也终于现身了,就是原index(不精确) 34 #del d['level_0'] # 删去某列 35 # 以上是查看 Id中大类别下小类别比重,突出重点
各种用户行为分析
数据探索分析
- 网页类型分析:(网页ID,fullURLId)咨询相关、知识相关、其他类型(大类及子类分布情况、占比)
- 点击次数分析:(真实IP,realIP),点击次数分析、点击分布特征、网页类型排名及占比
- 网页排名(点击):点击网址排名、翻页网页统计
1 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 2 def count107(i): 3 j=i[['fullURL']][i['fullURLId'].str.contains('107')].copy() 4 j['type']=None 5 j['type'][j['fullURL'].str.contains('info/.+?/')]='知识首页' 6 j['type'][j['fullURL'].str.contains('info/.+?/.+?')]='知识列表页' 7 j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]='知识内容页' 8 return j['type'].value_counts() 9 counts2=[count107(i) for i in sql] 10 counts2=pd.concat(counts2).groupby(level=0).sum() 11 counts2.head() 12 counts2_=pd.DataFrame(counts2).reset_index() 13 counts2_['percentage']=(counts2_['type']/counts2_['type'].sum())*100 14 counts2_.columns=['107类型','num','百分比'] 15 # 以上是 统计107开头(知识类,源于问题分析中网址分类:咨询,知识,其他) 16 17 def countquestion(i): 18 j=i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() 19 return j 20 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 21 counts3=[countquestion(i)['fullURLId'].value_counts() for i in sql] 22 counts3=pd.concat(counts3).groupby(level=0).sum() 23 counts3 24 counts3_=pd.DataFrame(counts3) 25 counts3_['percentage']=(counts3_['fullURLId']/counts3_['fullURLId'].sum())*100 26 counts3_.reset_index(inplace=True) 27 counts3_.columns=['fullURLId','num','percentage'] 28 counts3_.sort_values(by='percentage',ascending=False,inplace=True) 29 counts3_.reset_index(inplace=True) 30 c3=(counts3_['num'].sum()/counts1['num'].sum())*100 31 c3 32 # 以上是统计?网页各类占比情况,探究?网页特征及在总样本占比 33 34 def page199(i): 35 j=i[['pageTitle']][i['fullURLId'].str.contains('199') & i['fullURL'].str.contains('\?')] 36 j['title']=1 37 j['title'][j['pageTitle'].str.contains('法律快车-律师助手')]='法律快车-律师助手' 38 j['title'][j['pageTitle'].str.contains('免费发布法律咨询')]='免费发布法律咨询' 39 j['title'][j['pageTitle'].str.contains('咨询发布成功')]='咨询发布成功' 40 j['title'][j['pageTitle'].str.contains('法律快搜')]='快搜' 41 j['title'][j['title']==1]='其他类型' 42 return j 43 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 44 counts4=[page199(i) for i in sql] 45 counts4_=pd.concat(counts4) 46 ct4_result=counts4_['title'].value_counts() 47 ct4_result=pd.DataFrame(ct4_result) 48 ct4_result.reset_index(inplace=True) 49 ct4_result['percentage']=(ct4_result['title']/ct4_result['title'].sum())*100 50 ct4_result.columns=['title','num','percentage'] 51 ct4_result.sort_values(by='num',ascending=False,inplace=True) 52 ct4_result 53 # 以上是统计199,其他类网址细分类别特征,占比 54 55 def wandering(i): 56 j=i[['fullURLId','fullURL','pageTitle']][(i['fullURL'].str.contains('.html'))==False] 57 return j 58 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 59 counts5=[wandering(i) for i in sql] 60 counts5_=pd.concat(counts5) 61 62 ct5Id=counts5_['fullURLId'].value_counts() 63 ct5Id 64 ct5Id_=pd.DataFrame(ct5Id) 65 ct5Id_.reset_index(inplace=True) 66 ct5Id_['index']=ct5Id_['index'].str.extract('(\d{3})',expand=True) 67 ct5Id_=pd.DataFrame(ct5Id_.groupby('index').sum()) 68 ct5Id_['percentage']=(ct5Id_['fullURLId']/ct5Id_['fullURLId'].sum())*100 69 ct5Id_.reset_index(inplace=True) 70 ct5Id_.columns=['fullURLId','num','percentage'] 71 ct5Id_.sort_values(by='num',ascending=False,inplace=True) 72 ct5Id_.reset_index(inplace=True) 73 #del ct5Id_['index'] # 可直接在reset_index(drop=True) 74 75 # 以上是分析 闲逛网站的用户浏览特征,那些吸引了这些闲逛用户 76 77 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 78 counts6=[i['realIP'].value_counts() for i in sql] 79 counts6_=pd.concat(counts6).groupby(level=0).sum() 80 counts6_=pd.DataFrame(counts6_) 81 counts6_[1]=1 82 ct6=counts6_.groupby('realIP').sum() 83 ct6.columns=['用户数'] # 点击次数情况,来表征用户,即点击n次的用户数为m 84 ct6.index.name='点击次数' # realIP 出现次数 85 ct6['用户百分比']=ct6['用户数']/ct6['用户数'].sum()*100 86 ct6['记录百分比']= ct6['用户数']*ct6.index/counts6_['realIP'].sum()*100 # 点击n次记录数占总记录数的比值 87 ct6.sort_index(inplace=True) 88 ct6_=ct6.iloc[:7,:].T 89 ct6['用户数'].sum() #总点击次数 90 ct6_.insert(0,'总计',[ct6['用户数'].sum(),100,100]) 91 ct6_['7次以上']=ct6_.iloc[:,0]-ct6_.iloc[:,1:].sum(axis=1) 92 ct6_ 93 94 beyond7=ct6.index[7:] 95 bins=[7,100,1000,50000] #用于划分区间 96 beyond7_cut=pd.cut(beyond7,bins,right=True,labels=['8~100','101~1000','1000以上'])#right=True 即(7,100],(101,1000] 97 beyond7_cut_=pd.DataFrame(beyond7_cut.value_counts()) 98 beyond7_cut_.index.name='点击次数' 99 beyond7_cut_.columns=['用户数'] 100 beyond7_cut_.iloc[0,0]=ct6.loc[8:100,:]['用户数'].sum() #依次为点击在(7,100]用户数,iloc索引号比第几个少一 101 beyond7_cut_.iloc[1,0]=ct6.loc[101:1000,:]['用户数'].sum() #注意,这里使用iloc会有问题,因这里行索引并非0开始的连续整数,而是名称索引,非自然整数索引 102 beyond7_cut_.iloc[2,0]=ct6.loc[1001:,:]['用户数'].sum() 103 beyond7_cut_.sort_values(by='用户数',ascending=False,inplace=True) 104 beyond7_cut_.reset_index(drop=True,inplace=True) 105 beyond7_cut_ # 点击8次以上情况统计分析,点击分布情况 106 107 for_once=counts6_[counts6_['realIP']==1] # 分析点击一次用户行为特征 108 del for_once[1] # 去除多余列 109 for_once.columns=['点击次数'] 110 for_once.index.name='realIP' # IP 找到,以下开始以此为基准 链接数据,merge 111 112 sql=pd.read_sql('all_gzdata',engine,chunksize=10000) 113 for_once_=[i[['fullURLId','fullURL','realIP']] for i in sql] 114 for_once_=pd.concat(for_once_) 115 for_once_merge=pd.merge(for_once,for_once_,right_on='realIP',left_index=True,how='left') 116 for_once_merge #浏览一次用户行为信息,浏览的网页,可分析网页类型 117 for_once_url=pd.DataFrame(for_once_merge['fullURL'].value_counts()) 118 for_once_url.reset_index(inplace=True) 119 for_once_url.columns=['fullURL','num'] 120 for_once_url['percentage']=for_once_url['num']/for_once_url['num'].sum()*100 121 for_once_url #浏览一次用户行为信息,浏览的网页,可分析网页类型:税法、婚姻、问题 122 # 以上是分析用户点击情况,点击频率特征,点一次就走 跳失率。。 123 124 def url_click(i): 125 j=i[['fullURL','fullURLId','realIP']][i['fullURL'].str.contains('\.html')] # \带不带都一样 126 return j 127 128 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 129 counts8=[url_click(i) for i in sql] 130 counts8_=pd.concat(counts8) 131 ct8=counts8_['fullURL'].value_counts() 132 ct8=pd.DataFrame(ct8) 133 ct8.columns=['点击次数'] 134 ct8.index.name='网址' 135 ct8.sort_values(by='点击次数',ascending=False).iloc[:20,:] #网址的点击率排行,用户关注度 136 137 ct8_=ct8.reset_index() #500和501一样结果,思路不一样,推第一个500 138 click_beyond_500=ct8_[(ct8_['网址'].str.contains('/\d+?_*\d+?\.html')) & (ct8_['点击次数']>50)] 139 click_beyond_501=ct8_[ct8_['网址'].str.contains('/\d+?_*\d+?\.html')][ct8_['点击次数']>50] # 会报警 140 141 # 以上是网页点击情况分析,点击最多是那些,关注度 142 143 #for i in sql: #逐块变换并去重 144 # d = i.copy() 145 # d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html', '.html') #将下划线后面部分去掉,规范为标准网址 146 # d = d.drop_duplicates() #删除重复记录 147 # d.to_sql('changed_gzdata', engine, index = False, if_exists = 'append') #保存 148 149 def scanning_url(i): 150 j=i.copy() 151 j['fullURL']=j['fullURL'].str.replace('_\d{0,2}.html','.html') 152 return j 153 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 154 counts9=[scanning_url(i) for i in sql] 155 counts9_=pd.concat(counts9) 156 ct9=counts9_['fullURL'].value_counts() # 每个网页被点击总次数,多页合为一页 157 ct9_=counts9_[['realIP','fullURL']].groupby('fullURL').count() # 每个IP对所点击网页的点击次数,多页合为一页 158 ct9__=ct9_['realIP'].value_counts() 159 ct9__20=ct9__[:20] 160 ct9__20.plot() 161 162 #另一种分析视角,翻页行为统计分析 163 pattern=re.compile('http://(.*\d+?)_\w+_\w+\.html$|http://(.*\d+?)_\w+\.html$|http://(.*\w+?).html$',re.S) # re.S 字符串跨行匹配;# 获取网址中以http://与.html中间的主体部分,即去掉翻页的内容,即去掉尾部"_d" 164 # 三个分别对应 主站点, 165 c9=click_beyond_500.set_index('网址').sort_index().copy() #sort_index()保证了 同一主站翻页网页是按从第一页开始排列的,即首页、下一页,为下方计算下一页点击占上一页比率铺垫 166 c9['websitemain']=np.nan # 统计主站点,即记录主站点,翻页的首页点击次数 167 for i in range(len(c9)): 168 items=re.findall(pattern,c9.index[i]) 169 if len(items)==0: 170 temp=np.nan 171 else: 172 for j in items[0]: 173 if j!='': 174 temp=j 175 c9.iloc[i,1]=temp 176 c9.head() 177 c9_0=c9['websitemain'].value_counts() 178 c9_0=pd.DataFrame(c9_0) 179 c9_1=c9_0[c9_0['websitemain']>=2].copy() # 滤掉不存在翻页的网页 180 c9_1.columns=['Times'] # 用于识别是一类网页,主网址出现次数 181 c9_1.index.name='websitemain' 182 c9_1['num']=np.arange(1,len(c9_1)+1) 183 c9_2=pd.merge(c9,c9_1,left_on='websitemain',right_index=True,how='right') # 链接左列与右索引 且左列与右索引的保留二者的行,且已右边为基础(即右边全保留,在此基础上添加左边的二者有共通行的) 184 # 当列与列做链接 索引会被忽略舍去,链接列与索引或索引与索引时索引会保留 185 c9_2.sort_index(inplace=True) 186 187 c9_2['per']=np.nan 188 def getper(x): 189 print(x) 190 for i in range(len(x)-1): 191 x.iloc[i+1,-1]=x.iloc[i+1,0]/x.iloc[i,0] # 翻页与上一页点击率比值,保存在最后一列处;同类网页下一页与上一页点击率比 192 return x 193 result=pd.DataFrame() 194 for i in range(1,c9_2['num'].max()+1): # 多少种翻页类,c9_2['num'].max()+1,从1开始 195 k=getper(c9_2[c9_2['num']==i]) # 同类翻页网页下一页与上一页点击数比值 196 result=pd.concat([result,k]) 197 c9_2['Times'].value_counts() 198 199 flipPageResult=result[result['Times']<10] 200 flipPageResult.head() 201 # 以上是用户翻页行为分析,网站停留情况,文章分页优化 202 203 def countmidurl(i): # 删除数据规则之中间网页(带midques_) 204 j=i[['fullURL','fullURLId','realIP']].copy() 205 j['type']='非中间类型网页' 206 j['type'][j['fullURL'].str.contains('midques_')]='中间类型网页' 207 return j['type'].value_counts() 208 209 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 210 counts10=[countmidurl(i) for i in sql] 211 counts10_=pd.concat(counts10).groupby(level=0).sum() 212 counts10_ 213 214 def count_no_html(i): # 删除数据规则之目录页(带html) 215 j=i[['fullURL','pageTitle','fullURLId']].copy() 216 j['type']='有html' 217 j['type'][j['fullURL'].str.contains('\.html')==False]="无html" 218 return j['type'].value_counts() 219 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 220 counts11=[count_no_html(i) for i in sql] 221 counts11_=pd.concat(counts11).groupby(level=0).sum() 222 counts11_ 223 224 def count_law_consult(i): # 数据删除规则之咨询、律师助手登录 225 j=i[['fullURL','pageTitle','fullURLId']].copy() 226 j['type']='其他' 227 j['pageTitle'].fillna('空',inplace=True) 228 j['type'][j['pageTitle'].str.contains('快车-律师助手')]='快车-律师助手' 229 j['type'][j['pageTitle'].str.contains('咨询发布成功')]='咨询发布成功' 230 j['type'][(j['pageTitle'].str.contains('免费发布法律咨询')) | (j['pageTitle'].str.contains('法律快搜'))]='快搜免费发布法律咨询' 231 return j['type'].value_counts() 232 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 233 counts12=[count_law_consult(i) for i in sql] 234 counts12_=pd.concat(counts12).groupby(level=0).sum() 235 counts12_ 236 237 def count_law_ques(i): # 数据删除规则之去掉与分析网站无关的网页 238 j=i[['fullURL']].copy() 239 j['fullURL']=j['fullURL'].str.replace('\?.*','') 240 j['type']='主网址不包含关键字' 241 j['type'][j['fullURL'].str.contains('lawtime')]='主网址包含关键字' 242 return j 243 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 244 counts13=[count_law_ques(i) for i in sql] 245 counts13_=pd.concat(counts13)['type'].value_counts() 246 counts13_ 247 248 def count_duplicate(i): # 数据删除规则之去掉同一用户同一时间同一网页的重复数据(可能是记录错误) 249 j=i[['fullURL','realIP','timestamp_format']].copy() 250 return j 251 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 252 counts14=[count_duplicate(i) for i in sql] 253 counts14_=pd.concat(counts14) 254 print(len(counts14_[counts14_.duplicated()==True]),len(counts14_.drop_duplicates())) 255 256 ct14=counts14_.drop_duplicates() 257 258 # 以上是数据清洗的操作 259 # 开始对数据库数据进行清洗操作,构建模型数据 260 sql=pd.read_sql('select * from all_gzdata',engine,chunksize=10000) 261 for i in sql: #只要.html结尾的 & 截取问号左边的值 & 只要包含主网址(lawtime)的&网址中间没有midques_的 262 d = i[['realIP', 'fullURL','pageTitle','userID','timestamp_format']].copy() # 只要网址列 263 d['fullURL'] = d['fullURL'].str.replace('\?.*','') # 网址中问号后面的部分 264 d = d[(d['fullURL'].str.contains('\.html')) & (d['fullURL'].str.contains('lawtime')) & (d['fullURL'].str.contains('midques_') == False)] # 只要含有.html的网址 265 # 保存到数据库中 266 d.to_sql('cleaned_one', engine, index = False, if_exists = 'append') 267 268 sql=pd.read_sql('select * from cleaned_one',engine,chunksize=10000) 269 for i in sql: #删除 快车-律师助手 & 免费发布法律咨询 & 咨询发布成功 & 法律快搜) 270 d = i[['realIP','fullURL','pageTitle','userID','timestamp_format']]# 只要网址列 271 d['pageTitle'].fillna(u'空',inplace=True) 272 d = d[(d['pageTitle'].str.contains(u'快车-律师助手') == False) & (d['pageTitle'].str.contains(u'咨询发布成功') == False) & 273 (d['pageTitle'].str.contains(u'免费发布法律咨询') == False) & (d['pageTitle'].str.contains(u'法律快搜') == False) 274 ].copy() 275 # 保存到数据库中 276 d.to_sql('cleaned_two', engine, index = False, if_exists = 'append') 277 # 278 sql=pd.read_sql('select * from cleaned_two',engine,chunksize=10000) 279 def dropduplicate(i): 280 j = i[['realIP','fullURL','pageTitle','userID','timestamp_format']].copy() 281 return j 282 283 count15 = [dropduplicate(i) for i in sql] 284 count15 = pd.concat(count15) 285 print(len(count15)) # 2012895 286 count16 = count15.drop_duplicates(['fullURL','userID','timestamp_format']) # 一定要进行二次删除重复,因为不同的块中会有重复值 287 print(len(count16)) # 647300 288 count16.to_sql('cleaned_three', engine) 289 290 # 以上是数据清洗及保存到库的操作,清洗完毕 291 # 查看各表的长度 292 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) 293 lens = 0 294 for i in sql: 295 temp = len(i) 296 lens = temp + lens 297 print(lens) # 837450 298 # 查看cleaned_one表中的记录数 299 sql1 = pd.read_sql('cleaned_one', engine, chunksize = 10000) 300 lens1 = 0 301 for i in sql1: 302 temp = len(i) 303 lens1 = temp + lens1 304 print(lens1) # 1341930 305 # 查看cleaned_two表中的记录数 306 sql2 = pd.read_sql('cleaned_two', engine, chunksize = 10000) 307 lens2 = 0 308 for i in sql2: 309 temp = len(i) 310 lens2 = temp + lens2 311 print(lens2)#2012895 312 # 查看cleaned_three表中的记录数 313 sql3 = pd.read_sql('cleaned_three', engine, chunksize = 10000) 314 lens3 = 0 315 for i in sql3: 316 temp = len(i) 317 lens3 = temp + lens3 318 print(lens3) #1294600 319 320 # 以上是查看,处理的保存的各表长度,清洗掉的数据是不是太大 321 322 sql = pd.read_sql('cleaned_three', engine, chunksize = 10000) 323 l0 = 0 324 l1 = 0 325 l2 = 0 326 for i in sql: 327 d = i.copy() 328 # 获取所有记录的个数 329 l0 += len(d) 330 # 获取类似于http://www.lawtime.cn***/2007020619634_2.html格式的记录的个数 331 # 匹配1 易知,匹配1一定包含匹配2 332 x1 = d[d['fullURL'].str.contains('_\d{0,2}.html')] 333 l1 += len(x1) 334 # 匹配2 335 # 获取类似于http://www.lawtime.cn***/29_1_p3.html格式的记录的个数 336 x2 = d[d['fullURL'].str.contains('_\d{0,2}_\w{0,2}.html')] 337 l2 += len(x2) 338 # x1.to_sql('l1', engine, index=False, if_exists = 'append') # 保存 339 # x2.to_sql('l2', engine, index=False, if_exists = 'append') # 保存 340 341 print(l0,l1,l2) #1941900 166365 27780 342 343 344 # 去掉翻页的网址 345 sql = pd.read_sql('cleaned_three', engine, chunksize = 10000) 346 l4 = 0 347 for i in sql: #初筛 348 d = i.copy() 349 # 注意!!!替换1和替换2的顺序不能颠倒,否则删除不完整 350 # 替换1 将类似于http://www.lawtime.cn***/29_1_p3.html下划线后面部分"_1_p3"去掉,规范为标准网址 351 d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}_\w{0,2}.html','.html')#这部分网址有 9260 个 352 # 替换2 将类似于http://www.lawtime.cn***/2007020619634_2.html下划线后面部分"_2"去掉,规范为标准网址 353 d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html','.html') #这部分网址有 55455-9260 = 46195 个 354 d = d.drop_duplicates(['fullURL','userID']) # 删除重复记录(删除有相同网址和相同用户ID的)【不完整】因为不同的数据块中依然有重复数据 355 l4 += len(d) 356 d.to_sql('changed_1', engine, index=False, if_exists = 'append') # 保存 357 print(l4 )# 1643197 358 sql = pd.read_sql('changed_1', engine, chunksize = 10000) 359 def dropduplicate(i): #二次筛选 360 j = i[['realIP','fullURL','pageTitle','userID','timestamp_format']].copy() 361 return j 362 counts1 = [dropduplicate(i) for i in sql] 363 counts1 = pd.concat(counts1) 364 print(len(counts1))# 1095216 365 a = counts1.drop_duplicates(['fullURL','userID']) 366 print(len(a))# 528166 367 a.to_sql('changed_2', engine) # 保存 368 # 验证是否清洗干净,即changed_2已不存翻页网址 369 sql = pd.read_sql('changed_2', engine, chunksize = 10000) 370 l0 = 0 371 l1 = 0 372 l2 = 0 373 for i in sql: 374 d = i.copy() 375 # 获取所有记录的个数 376 l0 += len(d) 377 # 获取类似于http://www.lawtime.cn***/2007020619634_2.html格式的记录的个数 378 # 匹配1 易知,匹配1一定包含匹配2 379 x1 = d[d['fullURL'].str.contains('_\d{0,2}.html')] 380 l1 += len(x1) 381 # 匹配2 382 # 获取类似于http://www.lawtime.cn***/29_1_p3.html格式的记录的个数 383 x2 = d[d['fullURL'].str.contains('_\d{0,2}_\w{0,2}.html')] 384 l2 += len(x2) 385 print(l0,l1,l2)# 528166 0 0表示已经删除成功 386 387 # 手动添加咨询类和知识类网址的类别,type={'咨询类','知识类'} 388 sql = pd.read_sql('changed_2', engine, chunksize = 10000) 389 def countzhishi(i): 390 j = i[['fullURL']].copy() 391 j['type'] = 'else' 392 j['type'][j['fullURL'].str.contains('(info)|(faguizt)')] = 'zhishi' 393 j['type'][j['fullURL'].str.contains('(ask)|(askzt)')] = 'zixun' 394 return j 395 counts17 = [countzhishi(i) for i in sql] 396 counts17 = pd.concat(counts17) 397 counts17['type'].value_counts() 398 a = counts17['type'].value_counts() 399 b = pd.DataFrame(a) 400 b.columns = ['num'] 401 b.index.name = 'type' 402 b['per'] = b['num']/b['num'].sum()*100 403 b 404 # 接上;咨询类较单一,知识类有丰富的二级、三级分类,以下作分析 405 c = counts17[counts17['type']=='zhishi'] 406 d = c[c['fullURL'].str.contains('info')] 407 print(len(d)) # 102140 408 d['iszsk'] = 'else' # 结果显示是空 409 d['iszsk'][d['fullURL'].str.contains('info')] = 'infoelsezsk' # 102032 410 d['iszsk'][d['fullURL'].str.contains('zhishiku')] = 'zsk' # 108 411 d['iszsk'].value_counts() 412 # 由结果可知,除了‘info'和’zhishifku'没有其他类型,且 【info类型(不包含zhishiku):infoelsezsk】和【包含zhishiku:zsk】类型无相交的部分。 413 # 因此分析知识类别下的二级类型时,需要分两部分考虑,求每部分的类别,再求并集,即为所有二级类型 414 415 # 对于http://www.lawtime.cn/info/jiaotong/jtsgcl/2011070996791.html类型的网址进行这样匹配,获取二级类别名称"jiaotong" 416 pattern = re.compile('/info/(.*?)/',re.S) 417 e = d[d['iszsk'] == 'infoelsezsk'] 418 for i in range(len(e)): #用上面已经处理的'iszsk'列分成两种类别的网址,分别使用正则表达式进行匹配,较慢 419 e.iloc[i,2] = re.findall(pattern, e.iloc[i,0])[0] 420 print(e.head()) 421 # 对于http://www.lawtime.cn/zhishiku/laodong/info/***.html类型的网址进行这样匹配,获取二级类别名称"laodong" 422 # 由于还有一类是http://www.lawtime.cn/zhishiku/laodong/***.html,所以使用'zhishiku/(.*?)/'进行匹配 423 pattern1 = re.compile('zhishiku/(.*?)/',re.S) 424 f = d[d['iszsk'] == 'zsk'] 425 for i in range(len(f)): 426 # print i 427 f.iloc[i,2] = re.findall(pattern1, f.iloc[i,0])[0] 428 print(f.head()) 429 430 e.columns = ['fullURL', 'type1', 'type2'] 431 print(e.head()) 432 f.columns = ['fullURL', 'type1', 'type2'] 433 print(f.head()) 434 # 将两类处理过二级类别的记录合并,求二级类别的交集 435 g = pd.concat([e,f]) 436 h = g['type2'].value_counts() 437 # 求两类网址中的二级类别数,由结果可知,两类网址的二级类别的集合的并集满足所需条件 438 len(e['type2'].value_counts()) # 66 439 len(f['type2'].value_counts()) # 31 440 len(g['type2'].value_counts()) # 69 441 print(h.head()) 442 print(h.index) # 列出知识类别下的所有的二级类别 443 444 for i in range(len(h.index)): # 将二级类别存入到数据库中 445 x=g[g['type2']==h.index[i]] 446 x.to_sql('h.index', engine, if_exists='append') 447 448 q = e.copy() 449 q['type3'] = np.nan 450 resultype3 = pd.DataFrame([],columns=q.columns) 451 for i in range(len(h.index)): # 正则匹配出三级类别 452 pattern2 = re.compile('/info/'+h.index[i]+'/(.*?)/',re.S) 453 current = q[q['type2'] == h.index[i]] 454 print(current.head()) 455 for j in range(len(current)): 456 findresult = re.findall(pattern2, current.iloc[j,0]) 457 if findresult == []: # 若匹配结果是空,则将空值进行赋值给三级类别 458 current.iloc[j,3] = np.nan 459 else: 460 current.iloc[j,3] = findresult[0] 461 resultype3 = pd.concat([resultype3,current])# 将处理后的数据拼接,即网址做索引,三列为一级、二级、三级类别 462 resultype3.set_index('fullURL',inplace=True) 463 resultype3.head(10) 464 # 统计婚姻类下面的三级类别的数目 465 j = resultype3[resultype3['type2'] == 'hunyin']['type3'].value_counts() 466 print(len(j)) # 145 467 j.head() 468 469 Type3nums = resultype3.pivot_table(index = ['type2','type3'], aggfunc = 'count') #类别3排序 470 # 方式2: Type3nums = resultype3.groupby([resultype3['type2'],resultype3['type3']]).count() 471 r = Type3nums.reset_index().sort_values(by=['type2','type1'],ascending=[True,False]) 472 r.set_index(['type2','type3'],inplace = True) 473 474 r.to_excel('2_2_3Type3nums.xlsx') 475 r 476 477 # 读取数据库数据 ,属性规约,提取模型需要的数据(属性);此处是只选择用户和用户访问的网页 478 sql = pd.read_sql('changed_2', engine, chunksize = 10000) 479 l1 = 0 480 l2 = 0 481 for i in sql: 482 zixun = i[['userID','fullURL']][i['fullURL'].str.contains('(ask)|(askzt)')].copy() 483 l1 = len(zixun) + l1 484 hunyin = i[['userID','fullURL']][i['fullURL'].str.contains('hunyin')].copy() 485 l2 = len(hunyin) + l2 486 zixun.to_sql('zixunformodel', engine, index=False,if_exists = 'append') 487 hunyin.to_sql('hunyinformodel', engine, index=False,if_exists = 'append') 488 print(l1,l2) # 393185 16982 489 # 方法二: 490 m = counts17[counts17['type'] == 'zixun'] 491 n = counts17[counts17['fullURL'].str.contains('hunyin')] 492 p = m[m['fullURL'].str.contains('hunyin')] 493 p # 结果为空,可知,包含zixun的页面中不包含hunyin,两者没有交集 494 #savetosql(m,'zixun') 495 #savetosql(n,'hunyin') 496 m.to_sql('zixun',engine) 497 n.to_sql('hunyin',engine)
服务推荐,协同过滤算法
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想,协同思想就是基于类似个体喜好推导目标喜好。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目录?
协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,就是你的品位偏好,所以它更多可以作为个性化推荐的算法思想。可以想象,这种推荐策略在 Web 2.0 的长尾中是很重要的,将大众流行的东西推荐给长尾中的人怎么可能得到好的效果,这也回到推荐系统的一个核心问题:了解你的用户,然后才能给出更好的推荐 。协同过滤推荐算法主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品,算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:人以类聚,物以群分。
- 基于用户的协同过滤:将物品A推荐给哪个用户?(假设答案是用户B);适用于用户少、物品多的场景
- 基于物品的协同过滤:将哪个物品推荐给用户B?(按前假设,物品A);适用于用户多、物品少的场景(可减少计算量)
本文分析目标:长尾网页丰富、个性化需求强烈。网页数是小于用户量的,适用于基于物品的协同过滤推荐系统对用户个性化推荐。步骤如下:
- 计算物品之间相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
相似度计算方式
夹角余弦、杰卡德相似系数、相关系数(Pearson Correlation)、欧氏距离
夹角余弦
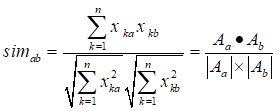
相似系数
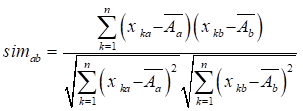
杰卡德(Jaccard)相似系数(针对0-1矩阵),杰卡德距离=1-杰卡德系数
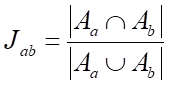 ,同时喜欢ab产品的用户数与喜欢a或b用户数比值
,同时喜欢ab产品的用户数与喜欢a或b用户数比值
改进相似度,考虑新老用户活跃度不同,活跃用户(老用户)对物品相似度贡献会小于不活跃的用户(新用户)
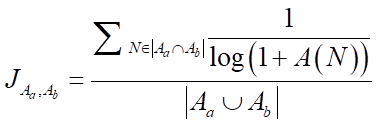 ,N为同时喜好ab产品的用户,A(N)为该用户的活跃度(如点击量)
,N为同时喜好ab产品的用户,A(N)为该用户的活跃度(如点击量)
用户-物品评分矩阵
P=R*SIM;P用户对物品感兴趣程度,R用户对物品兴趣(二元选择,0-1阵),SIM所有物品之间相似度。
模型评价
离线测试评测指标
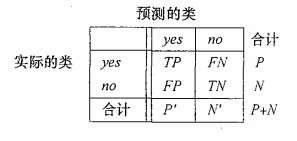
- 预测准确度:均方根误差(RMSE)、平均绝对误差(MAE)
- 分类准确度:准确率(P,precesion)=TP/(TP+FP)、召回率(R,recall)=TP/(TP+FN)、F1=2*PR/(P+R)
对本题来讲,P表示用户对一个被推荐产品感兴趣的可能性,R表示一个用户喜欢的产品被推荐的概率,F1指标综合考虑了P、R。
推荐算法
数据集清洗完毕输出模型所需格式包括:用户ID,网址。该部分引用CSDN:江流静一
1 ## 推荐,基于物品的协同过滤推荐、随机推荐、按流行度推荐 2 3 data=pd.read_sql('hunyinformodel',engine) 4 data.head() 5 def jaccard(a,b): # 杰卡德相似系数,对0-1矩阵,故需要先将数据转成0-1矩阵 6 return 1.0*(a*b).sum()/(a+b-a*b).sum() 7 class recommender(): 8 sim=None 9 def similarity(self,x,distance): 10 y=np.ones((len(x),len(x))) 11 for i in range(len(x)): 12 for j in range(len(x)): 13 y[i,j]=distance(x[i],x[j]) 14 return y 15 def fit(self,x,distance=jaccard): 16 self.sim=self.similarity(x,distance) 17 return self.sim 18 def recommend(self,a): 19 return np.dot(self.sim,a)*(1-a) 20 len(data['fullURL'].value_counts()) 21 len(data['realIP'].value_counts()) 22 # 网址数远小于用户数,即商品数小于使用的客户数,采用物品的协同过滤推荐 23 24 start0=time.clock() 25 data.sort_values(by=['realIP','fullURL'],ascending=[True,True],inplace=True) 26 realIP=data['realIP'].value_counts().index 27 realIP=np.sort(realIP) 28 fullURL=data['fullURL'].value_counts().index 29 fullURl=np.sort(fullURL) 30 d=pd.DataFrame([],index=realIP,columns=fullURL) 31 for i in range(len(data)): 32 a=data.iloc[i,0] 33 b=data.iloc[i,1] 34 d.loc[a,b]=1 35 d.fillna(0,inplace=True) 36 end0=time.clock() 37 usetime0=end0-start0 38 print('转化0-1矩阵耗时' + str(usetime0) +'s!') 39 #d.to_csv() 40 41 df=d.copy() 42 sampler=np.random.permutation(len(df)) 43 df = df.take(sample) 44 train=df.iloc[:int(len(df)*0.9),:] 45 test=df.iloc[int(len(df)*0.9):,:] 46 47 df=df.values() 48 df_train=df[:int(len(df)*0.9),:] # 9299 49 df_test=df[int(len(df)*0.9):,:] # 1034 50 df_train=df_tain.T 51 df_test=df_test.T 52 print(df_train.shape,df_test.shape) # (4339L, 9299L) (4339L, 1034L) 53 54 start1=time.clock() 55 r=recommender() 56 sim=r.fit(df_train) # 计算相似度矩阵 57 end1=time.clock() 58 a=pd.DataFrame(sim) 59 usetime1=end1-start1 60 print('建立矩阵耗时'+ str(usetime1)+'s!') 61 print(a.shape) 62 63 a.index=train.columns 64 #a.columns=train.columns 65 a.columns=train.index 66 a.head(20) 67 68 start2=time.clock() 69 result=r.recommend(df_test) 70 end2=time.clock() 71 72 result1=pd.DataFrame(result) 73 usetime2=end2-start2 74 75 print('测试集推荐函数耗时'+str(usetime2)+'s!') 76 result1.head() 77 result1.index=test.columns 78 result1.columns=test.index 79 result1 80 81 def xietong_result(k,recomMatrix): # k表推荐个数,recomMatrix推荐矩阵表DataFrame 82 recomMatrix.fillna(0.0,inplace=True) 83 n=range(1,k+1) 84 recommends=['xietong'+str(y) for y in n] 85 currentemp=pd.DataFrame([],index=recomMatrix.columns,columns=recommends) 86 for i in range(len(recomMatrix.columns)): 87 temp = recomMatrix.sort_values(by = recomMatrix.columns[i], ascending = False) 88 j = 0 89 while j < k: 90 currentemp.iloc[i,j] = temp.index[j] 91 if temp.iloc[j,i] == 0.0: 92 currentemp.iloc[i,j:k] = np.nan 93 break 94 j += 1 95 return currentemp 96 start3 = time.clock() 97 xietong_result = xietong_result(3, result1) 98 end3 = time.clock() 99 print('按照协同过滤推荐方法为用户推荐3个未浏览过的网址耗时为' + str(end3 - start3)+'s!') #29.4996622053s! 100 xietong_result.head() 101 102 # test = df.iloc[int(len(df)*0.9):, :] # 所有测试数据df此时是矩阵,这样不能用 103 randata = 1 - df_test # df_test是用户浏览过的网页的矩阵形式,randata则表示是用户未浏览过的网页的矩阵形式 104 randmatrix = pd.DataFrame(randata, index = test.columns,columns=test.index)#这是用户未浏览过(待推荐)的网页的表格形式 105 def rand_recommd(K, recomMatrix):# 106 import random # 注意:这个random是random模块, 107 import numpy as np 108 109 recomMatrix.fillna(0.0,inplace=True) # 此处必须先填充空值 110 recommends = ['recommed'+str(y) for y in range(1,K+1)] 111 currentemp = pd.DataFrame([],index = recomMatrix.columns, columns = recommends) 112 113 for i in range(len(recomMatrix.columns)): #len(res.columns)1 114 curentcol = recomMatrix.columns[i] 115 temp = recomMatrix[curentcol][recomMatrix[curentcol]!=0] # 未曾浏览过 116 # = temp.index[random.randint(0,len(temp))] 117 if len(temp) == 0: 118 currentemp.iloc[i,:] = np.nan 119 elif len(temp) < K: 120 r = temp.index.take(np.random.permutation(len(temp))) #注意:这个random是numpy模块的下属模块 121 currentemp.iloc[i,:len(r)] = r 122 else: 123 r = random.sample(temp.index, K) 124 currentemp.iloc[i,:] = r 125 return currentemp 126 127 start4 = time.clock() 128 random_result = rand_recommd(3, randmatrix) # 调用随机推荐函数 129 end4 = time.clock() 130 print('随机为用户推荐3个未浏览过的网址耗时为' + str(end4 - start4)+'s!') # 2.1900423292s! 131 #保存的表名命名格式为“3_1_k此表功能名称”,是本小节生成的第5张表格,功能为random_result:显示随机推荐的结果 132 #random_result.to_csv('random_result.csv') 133 random_result # 结果中出现了全空的行,这是冷启动现象,浏览该网页仅此IP一个,其他IP不曾浏览无相似系数 134 135 def popular_recommed(K, recomMatrix): 136 recomMatrix.fillna(0.0,inplace=True) 137 import numpy as np 138 recommends = ['recommed'+str(y) for y in range(1,K+1)] 139 currentemp = pd.DataFrame([],index = recomMatrix.columns, columns = recommends) 140 141 for i in range(len(recomMatrix.columns)): 142 curentcol = recomMatrix.columns[i] 143 temp = recomMatrix[curentcol][recomMatrix[curentcol]!=0] 144 if len(temp) == 0: 145 currentemp.iloc[i,:] = np.nan 146 elif len(temp) < K: 147 r = temp.index #注意:这个random是numpy模块的下属模块 148 currentemp.iloc[i,:len(r)] = r 149 else: 150 r = temp.index[:K] 151 currentemp.iloc[i,:] = r 152 153 return currentemp 154 155 # 确定用户未浏览的网页(可推荐的)的数据表格 156 TEST = 1-df_test # df_test是用户浏览过的网页的矩阵形式,TEST则是未曾浏览过的 157 test2 = pd.DataFrame(TEST, index = test.columns, columns=test.index) 158 print(test2.head()) 159 print(test2.shape ) 160 161 # 确定网页浏览热度排名: 162 hotPopular = data['fullURL'].value_counts() 163 hotPopular = pd.DataFrame(hotPopular) 164 print(hotPopular.head()) 165 print(hotPopular.shape) 166 167 # 按照流行度对可推荐的所有网址排序 168 test3 = test2.reset_index() 169 list_custom = list(hotPopular.index) 170 test3['index'] = test3['index'].astype('category') 171 test3['index'].cat.reorder_categories(list_custom, inplace=True) 172 test3.sort_values('index',inplace = True) 173 test3.set_index ('index', inplace = True) 174 print(test3.head()) 175 print(test3.shape) 176 177 # 按照流行度为用户推荐3个未浏览过的网址 178 recomMatrix = test3 # 179 start5 = time.clock() 180 popular_result = popular_recommed(3, recomMatrix) 181 end5 = time.clock() 182 print('按照流行度为用户推荐3个未浏览过的网址耗时为' + str(end5 - start5)+'s!')#7.70043007471s! 183 184 #保存的表名命名格式为“3_1_k此表功能名称”,是本小节生成的第6张表格,功能为popular_result:显示按流行度推荐的结果 185 #popular_result.to_csv('3_1_6popular_result.csv') 186 187 popular_result
Ref:
《Python数据分析与挖掘实战》第12章(上)——协同推荐
推荐系统:协同过滤collaborative filtering
《Python数据分析与挖掘实战》第12章(中)——协同推荐
《Python数据分析与挖掘实战》第12章(下)——协同推荐
《数据分析与挖掘实战》:源代码及数据需要可自取:https://github.com/Luove/Data

 浙公网安备 33010602011771号
浙公网安备 33010602011771号