Spark设置executor-memory后,executor显示的内存不符问题
以该命令为例,我们设置一个executor并分配内存为2800m,可以看到ui上只给executor分配了1.5G的内存。同理,如果你设置了--executor-memory=2g,那么实际上只会有1048.8M((2048 - 300) * 0.6)的内存会被分配。
spark-submit --master yarn \
--num-executors=1 \
--executor-memory=2800m \
--class org.apache.spark.examples.SparkPi \
/opt/module/spark-3.5.1-bin-hadoop3/examples/jars/spark-examples_2.12-3.5.1.jar 1000
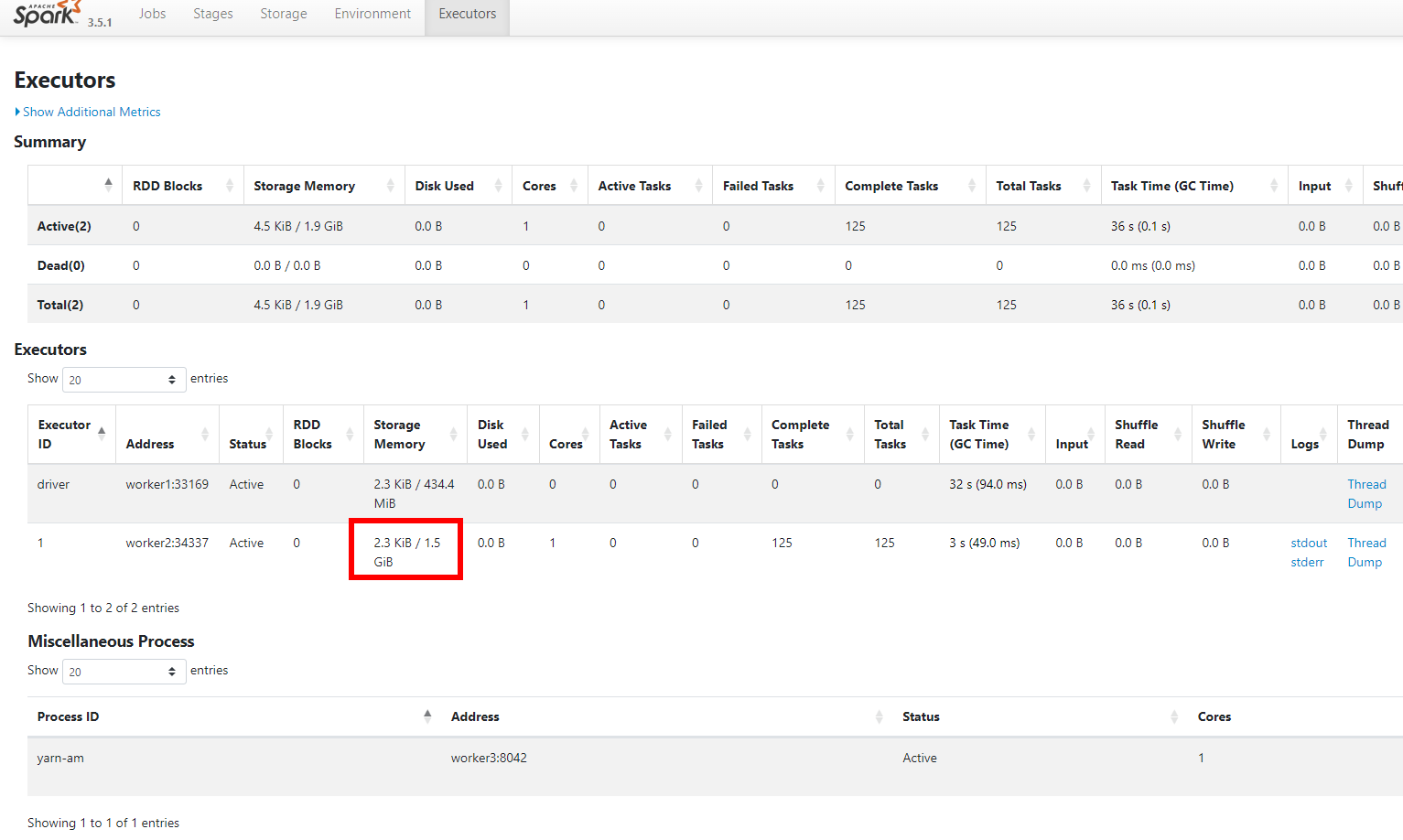
这个问题是因为显示的内存为,(heap space - 300MB) * spark.memory.fraction所划分的内存。详细介绍参见文档 https://spark.apache.org/docs/latest/tuning.html#memory-management-overview
内存管理概览
在 Spark 中,内存使用主要分为两大类:执行内存和存储内存。执行内存用于计算处理,如 shuffles(洗牌)、joins(连接)、sorts(排序)和 aggregations(聚合);而存储内存则用于缓存和在集群中传播内部数据。在 Spark 中,执行内存和存储内存共享一个统一的区域(M)。当没有使用执行内存时,存储内存可以占用所有可用的内存,反之亦然。在必要时,执行内存可以驱逐存储内存,但只到存储内存的使用量降到某个阈值(R)以下。换句话说,R 描述了 M 中的一个子区域,在该区域内,缓存的数据块不会被驱逐。由于实现机制的复杂性,存储内存不能驱逐执行内存。
此设计确保了几项理想的特性。首先,不利用缓存的应用可以使用全部内存空间进行执行操作,避免不必要的磁盘溢出。其次,利用缓存的应用可以预留一定的存储空间(R),确保其数据块不会被驱逐。最后,这种方法为多种工作负载提供了合理的即插即用性能,而无需用户深入了解内部内存划分的细节。
尽管有两个相关的配置参数,但典型用户通常不需要调整它们,因为默认值已适用于大多数工作负载:
spark.memory.fraction表示 M 占用的比例,计算公式为 (JVM 堆空间 - 300MiB) 的百分比(默认值为 0.6)。其余的空间(40%)留给用户数据结构、Spark 的内部元数据以及作为安全储备,以防出现稀疏或异常大的记录导致的 OOM(内存溢出)错误。spark.memory.storageFraction表示 R 占 M 的比例(默认值为 0.5)。R 是 M 内部的一块存储区域,其内的缓存数据块不会被执行操作驱逐。
spark.memory.fraction 的值应该设置在能够在 JVM 的老年代或“终身代”中舒适适应这部分堆空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号