使用PyPDF2库给PDF加多级书签
因为PDF是扫描的图片格式,所以加书签会很麻烦
可以先使用OCR软件将目录中的文字识别
这里我将目录处理成两个文件
bookmark.txt存放分级书签信息
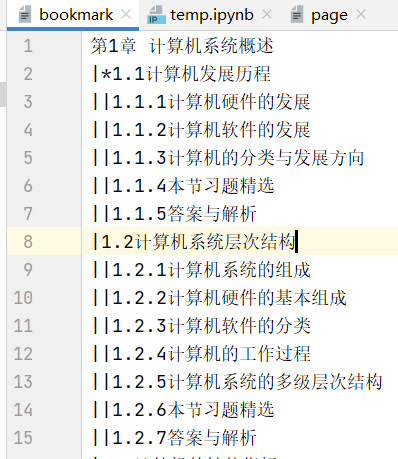
page.txt存放对应的页数
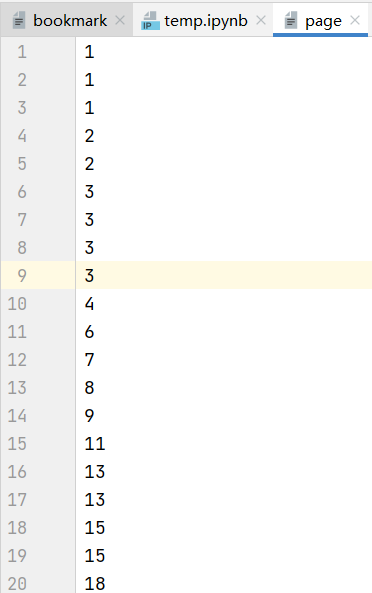
注意:页数和实际书籍页数可能会不一致(例如pdf页码是从封面开始算的,而书籍的第一页并不算封面和内容)
我们可以编写如下代码:
# 按行读取两个文件
fbookmark = open('bookmark',encoding='utf8').readlines()
page = open('page').readlines()
# 创建(几级书签,标题,页码)元组
bookmark = [(content.rfind('|') + 1,
content.strip()[content.rfind('|') + 1:],
int(p.strip())
) for content,p in zip(fbookmark,page)]
from PyPDF2 import PdfFileReader, PdfFileWriter
# 打开文件
input = PdfFileReader(open('input.pdf', 'rb'))
# 复制文件
output = PdfFileWriter()
pages = [input.getPage(i) for i in range(input.getNumPages())]
for page in pages:
output.addPage(page)
parent_set = {}
DELTA = 12 # 偏移量
# 创建分级书签(注1)
for bm in bookmark:
# 将字典中小一个等级的书签当做父节点
parent = output.addBookmark(bm[1],
bm[2] + DELTA,
parent=parent_set.get(bm[0]-1))
# 向自己作为字典中该等级的节点
parent_set[bm[0]] = parent
with open('result.pdf','wb+') as f:
output.write(f)
注1:这里创建分级书签的方式尝试了有一会儿,尝试了栈结构,后来发现字典结构合适、方便。
效果如下:
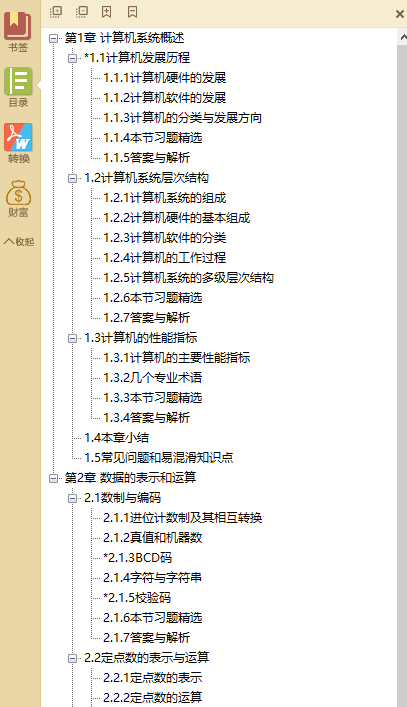
(用于解析目录,自动添加|分隔符)
with open('bookmark','r',encoding='utf8') as f:
c = f.readlines()
with open('bookmark2','w+',encoding='utf8') as output:
for line in c:
if line[0].isnumeric():
if line[1] == '.' and line[2].isnumeric():
output.write('|')
if line[3] == '.' and line[4].isnumeric():
output.write('|')
output.write(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号