numpy的统计函数
1.平均值:ndarray.mean()


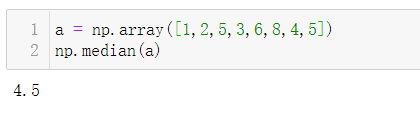
2.中位数:np.median(ndarra)
又称中点数,中值
是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值
平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据。
中位数:是一个不完全"虚拟"的数.
平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据。.中位数:是一个不完全"虚拟"的数.
中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的"中等水平"
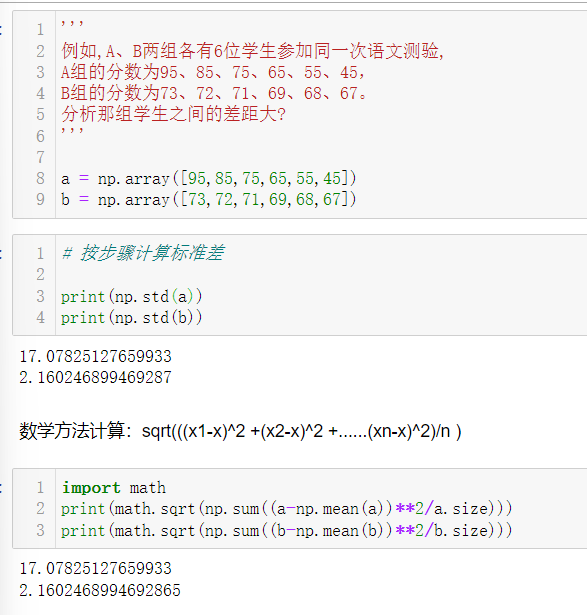
3.标准差:np.std(ndarray)
在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形·
标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;。
一个较小的标准差,代表这些数值较接近平均值。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越小,代表回报较为稳定,风险亦较小
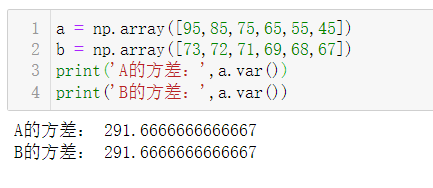
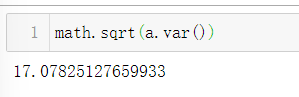
4.方差:ndarray.var()
衡量随机变量或一组数据时离散程度的度量:方差的算术平方根即时标准差
标准差有计量单位,而方差无计量单位,但两者的作用一样,
虽然能很好的描述数据与均值的偏离程度,处理结果是不符合我们的直观思维的。
5.最大值 ndarray.max() 最小值ndarray.min()


6.求和:ndarray.sum()

7.加权平均值 numpy.average()
即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数
numpy.average(a, axis=None, weights=None, returned=False)
weights:数组,可选
与a中的值关联的权重数组。a中的每个值都根据其关联的权重对平均值做出贡献。
权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的a的大小)或与
a具有相同的形状。如果weights=None,则假定a中的所有数据的权重等于1。一维计算是:
avg = sum(a * weights) / sum(weights)
对权重的唯一限制是sum(weights)不能为0。

作者:Ambitious
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号