小样本学习总结1
这周粗读了两篇关于小样本学习的论文,分别是NLP和CV领域的。
Meta-LMTC: Meta-Learning for Large-Scale Multi-Label Text Classification
出自EMNLP2021。本篇文章是大规模多标签文本分类,用到的是基于优化的元学习方法MAML。

文章的关键是采样元学习任务的方法,一种是基于标签采样,一种是基于实例采样。两种方法各有优缺点,基于标签的采样首先从可以观察到的标签中随机采样一个标签,同时再随机采样一个拥有该标签的文本组成一对数据,这种方法采样得到的标签相对公平,但是它会倾向于采样那些拥有few-shot标签的文本。基于实例采样的方法是随机选出一个文本,这种方法对于文本来说是非常公平的,但是获得的标签却是经常出现的标签。
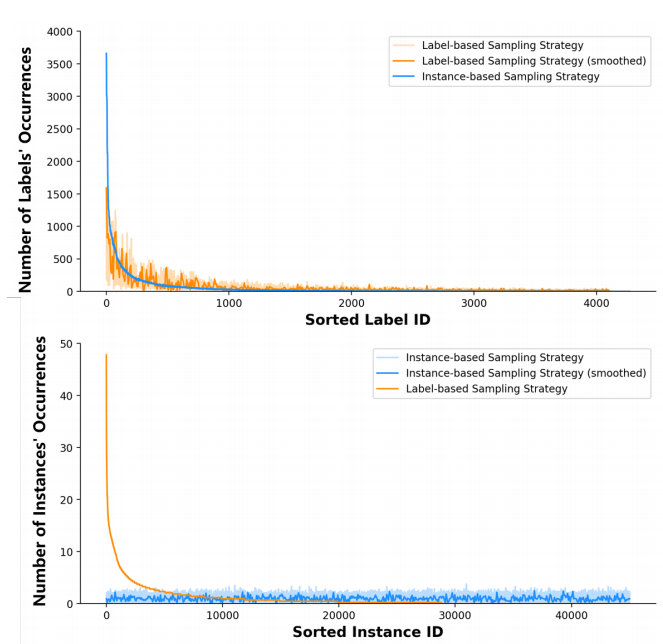
文章中设定了一个超参数p,别以p和1-p的概率选择基于标签采样和基于实例采样的方法进行任务采样。
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
出自CVPR2022。这篇论文没怎么读懂,参考了其他人的阅读笔记CVPR2022小样本分类|Mutual Centralized Learning for few-shot learning。目标是给定一个需要查询类别的图片q,q中包含r个特征,再给定一个支持集S,S中包含c个类别,每个类别有r个特征,需要根据以上信息找到图片q所属的类别。文章提出了一种双向随机游走的方法,用\(P_{Sq}和P_{qS}\)转移概率,分别将随机游走的过程用矩阵表示,最终平稳的状态中包含了q和S特征之间的关系,用这个关系可以进行预测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号