MAMO: Memory-Augmented Meta-Optimization for Cold-start Recommendation阅读笔记
动机
本文是2020年KDD上的一篇论文。当时的工作已经有不少方法使用元学习来缓解推荐系统冷启动问题,它们大部分都是基于MAML的,这种方法通常是为所有冷启动用户(物品)生成一个初始化向量,然后让这些冷启动用户(物品)经过少量训练就可以快速收敛到一个不错的值。但是上述这种方法会导致部分用户局部收敛,泛化性能较差。针对以上问题,本文作者提出了一种MAMO方法。
方法
本文提出的方法主要是额外引入了几个额外的记忆模块\(M=\{M_U,M_P,M_{U,I}\}\),分别表示用户embedding记忆、用户个人信息的记忆以及特定任务记忆。
以下是本方法的训练过程。

首先我们需要对训练集中的每个用户计算出一个个性化偏置项\(b_u\),这个偏置项可以帮助当前用户更快速适应推荐系统,由以下方法计算得出
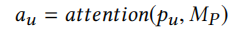
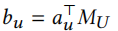
之后是得到本地参数,这里用于计算物品embedding的参数和推荐部分的参数直接从全局参数获取,用于计算物品embedding的参数需要进行个性化处理
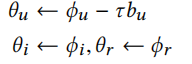
然后获取用户对应的特定任务记忆信息
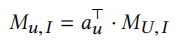
接着进入本地更新,推荐模型首先需要获取用户和物品的embedding,这里\(p_u\)和\(p_i\)分别表示用户和物品的信息,将这些信息输入进全连接层获取embedding
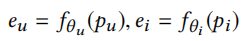
之后将物品与用户embedding和用户对应的特定任务记忆信息输入进全连接层获取用户对物品的评分
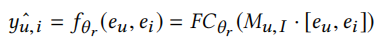
更新本地参数。
训练集中所有用户进行本地更新后,再进行全局更新。
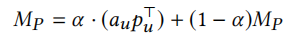
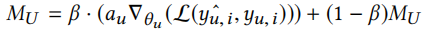
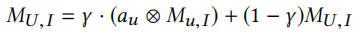
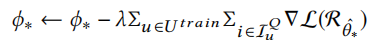
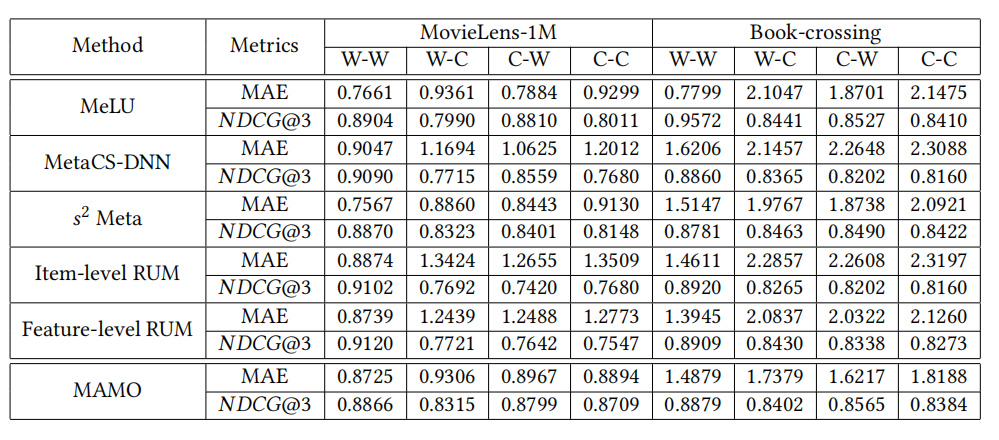
实验结果
作者在四种情况下进行实验,分别是:1.正常用户正常物品。2.正常用户冷启动物品。3.冷启动用户正常物品。4.冷启动用户冷启动物品。在冷启动场景下,MAMO表现优异。
总结
本文提出的MAMO关键在于使用了多个记忆模块,使得模型可以为每个用户生成更合适的初始值,增强了模型的泛化能力。这里可以从实验结果看出模型的效果有些情况下并没有基准模型好,还有一定的优化空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号