Deep Neural Networks for YouTube Recommendations阅读笔记
动机
本文是2016年谷歌团队提出的在YouTube上的推荐系统(YouTube算是谷歌的子公司,查之前我还奇怪为什么谷歌会研究YouTube的推荐系统)。在YouTube上做推荐有三个难点:1.规模大。YouTube上有非常多的视频和用户,许多在小规模数据集上运作很好的模型未必在YouTube上合适。2.更新速度快。每秒都有小时级视频上传,系统需要有足够的响应速度为这些视频建模并实时。3.噪声。用户的行为是稀疏的,且用户没有一个明确的满意度标识,同时视频数据本身是非结构化的,这对算法带来了不少挑战。
方法
以下是本文提出的推荐系统的整体结构。主要由两部分构成,候选集生成模块和排序模块,我认为就是目前常见推荐系统的召回层和排序层。候选集生成是从百万数量级的视频选出数百个用户最可能感兴趣的视频,这部分是粗排,对单个视频的评估消耗必须非常小;排序模块是精排,是更细粒度建模。
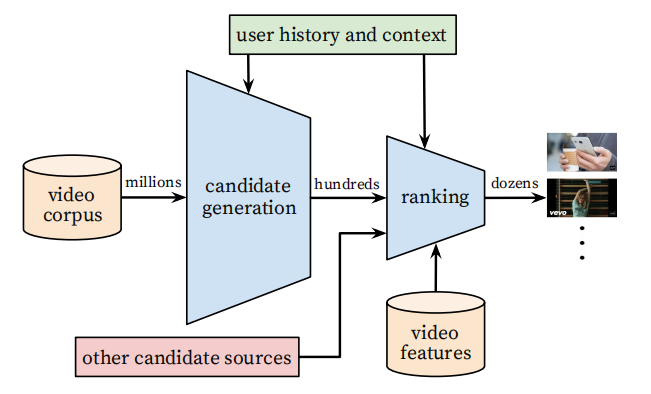
候选集生成
这部分推荐问题看作一个大规模分类问题,用户的个人信息和场景信息用\(u\)表示,第i类视频用\(v_i\)表示,有
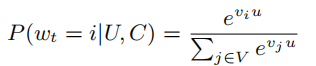
由于视频类别有数百万个,为了加速计算,这里使用负采样技术并且使用重要性加权进行校正。线上服务对响应时间有较高要求,这里通过最近邻搜索找到与用户最相关的N个视频。
模型结构如下。
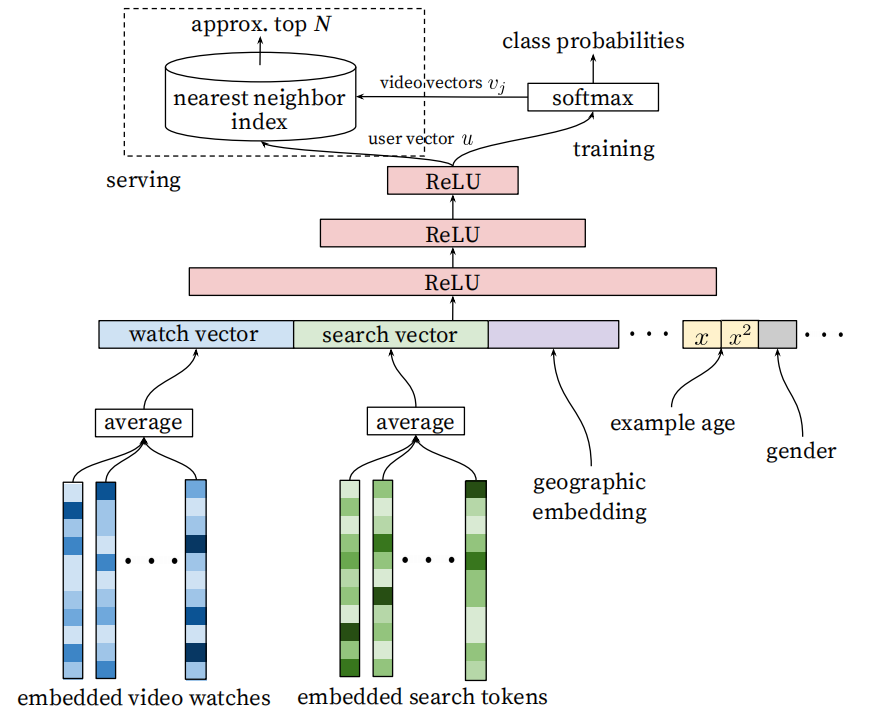
模型的输入是用户的观看历史、搜索历史、地理信息、年龄等上下文信息。之后是一个MLP,最终输出是用户的向量表示。在训练阶段,还需要将用户的向量输入进softmax层,而在模型服务阶段,则是利用用户向量进行最近邻搜索(例如局部敏感哈希)。
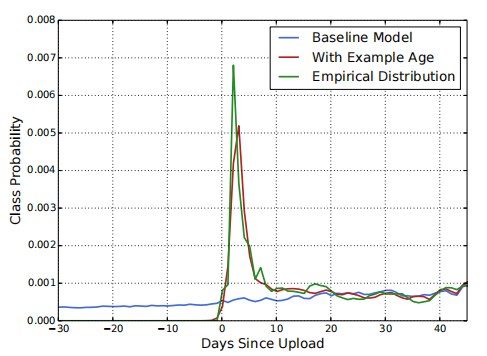
作者重点提到了“视频上传时间”这一特征,根据直觉,一般新上传的视频看的人会多一些,之后看的人会渐渐变少,作者将视频的“年龄”这一属性加入后,模型性能更好。
对于标签和上下文选择,作者有以下几个设计:1.使用更广泛的数据源来训练。2.为每个用户生成固定数量的训练样本。3.使用无序化数据。4.不对称的共同浏览,在预测下一次的浏览视频时,只使用之前的浏览行为。
作者还进行了不同深度的网络和特征实验,结果如下图。
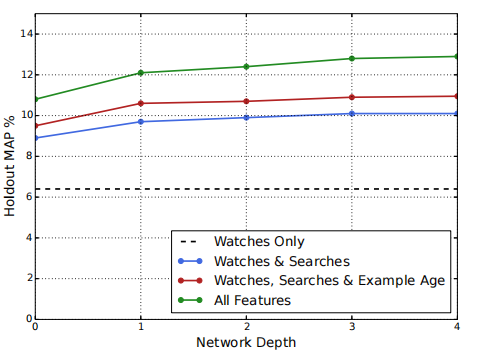
排序
排序阶段是更精确地估计用户对视频的喜好程度,用更多的特征进行更细粒度地建模。在模型目标我们选择的是期望观看时长,而不是CTR指标。
模型结构如下图。
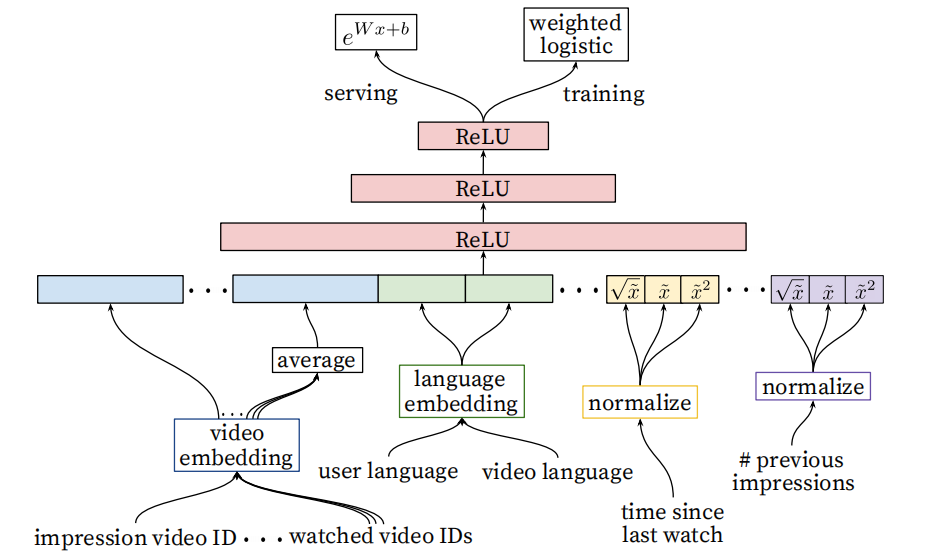
关于建模期望观看时长,作者使用weighted logistic regression作为期望观看时长的近似,可以参考这篇博客里的内容,讲的非常好。YouTube深度学习推荐系统
不同隐藏层的实验结果。

总结
本文讲述的是YouTube深度学习推荐模型,是一篇工业界的论文,论文中考虑的不少问题都和学术界的不同。本文值得关注的点在于候选集选择阶段中的example age特征,训练和服务对应不同的方法(考虑到性能问题);排序阶段以期望观看时间为目标,并用一个比较巧妙的方法进行近似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号