CMML: Contextual Modulation Meta Learning for Cold-Start Recommendation阅读笔记
动机
本文是2021年CIKM上的一篇论文。元学习是解决推荐系统冷启动问题的一种很好的方法,但是常用的元学习方法(例如MAML)通常是计算量大且与当前主流工业部署不兼容的。因此本文作者提出了CMML框架,它由一个任务级的上下文编码器,一个混合用户物品对和任务级上下文的生成器,一个可以调节推荐模型以有效适应的上下文调制网络组成。
方法
以下是CMML的框架图和算法流程,CMML主要由三部分组成。首先通过上下文编码器获取任务级别的上下文表示,然后将其和用户-物品的表示一起输入进混合上下文生成器生成特定于该用户-物品的上下文表示,然后再将特定于用户-物品的上下文表示输入进基于上下文的调制网络获取最终表示,也就是用户对物品的偏好。
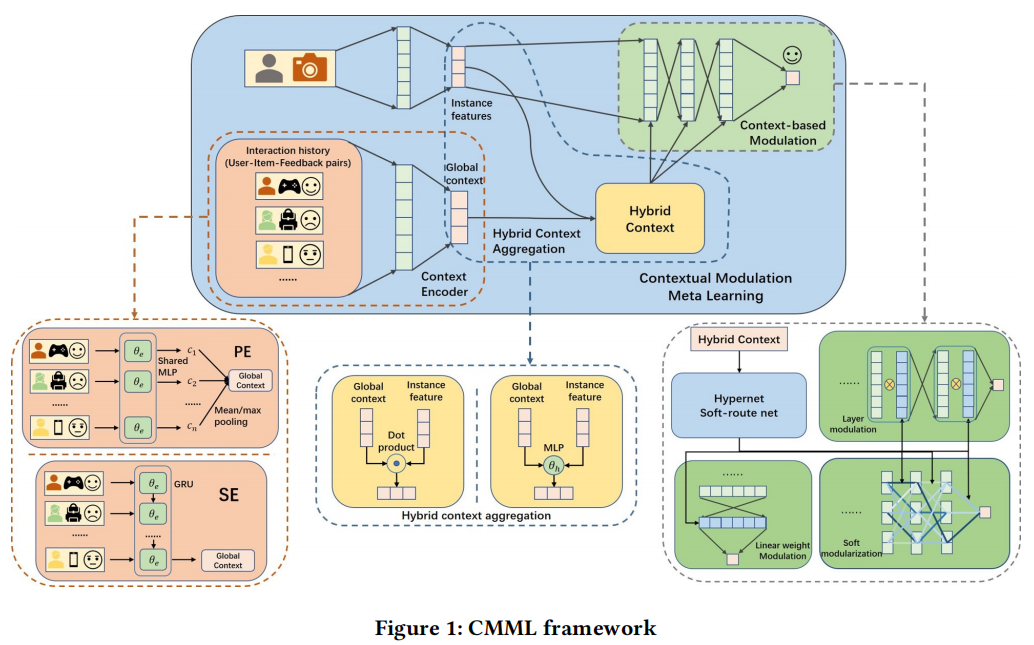

骨干网络
骨干网络由三部分构成:embedding层,隐藏层和输出层。embedding层有用户embedding矩阵\(M_u\)和物品embedding矩阵\(M_i\),根据用户的id\(x_u\)和物品的id\(x_i\)可获取用户和物品的表示\(e_u=M_ux_u\)、\(e_i=M_ix_i\)。隐藏层由激活函数为ReLU的MLP组成,它将连接在一起的用户与物品的特征\((e_u,e_i)\)映射为一个连续表示\(h_{ui}\)。输出层为\(o_{ui}=w^Th_{ui}+b\)。该部分网络参数记为\(\Phi\)。
上下文编码器
上下文编码器用于提取任务级别的信息,这里作者提供了两种选择:池化聚合编码器(PE)和序列聚合编码器(SE)。
池化聚合编码器。在获取用户与物品的embedding之后,将其输入激活函数为ReLU的MLP,这里表示为\(f_{\theta_e}\),之后通过一个池化操作得到该任务的上下文。
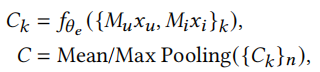
这种方式的优点是简单,且具有排列不变性,不必考虑排列顺序带来的影响。
序列聚合编码器。我们将任务中的所有用户项目对视为一个序列,将其输入进例如GRU这样的序列模型中,之后再将从GRU得到的结果输入进激活函数为ReLU的MLP中
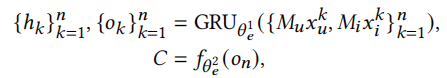
这里需要说明,数据集中通常不包含时间相关的信息,我们之所以选择序列模型是因为与池化聚合编码器相比,它有更好的上下文聚合能力,而不是因为它的顺序属性,我们在使用序列聚合编码器时,也可以在每次迭代的过程中打乱顺序使用。
混合上下文生成器
混合上下文生成器是混合了任务级别的信息和实例级别用户项目对的信息。作者提供了两种方式,一种是MLP,另一种是哈达玛积(原文中讲的是dot-product,翻译过来是点积,点积最终结果是一个标量,不合适,我认为这部分应该是哈达玛积更合适)。这里的C是上下文编码器的输出。
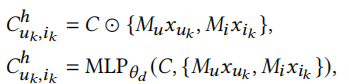
基于上下文的调制网络
基于上下文的调制网络目标是调制骨干网络\(\Phi\)使其快速适应特定的任务。作者提出了三种方法,分别是权重调制、层调制、软模块化。
权重调制。这种方法简单直接,只针对最后一层线性层生成权重和偏置。
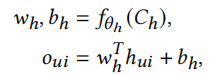
这种方法在任务完全不同时,可能没有足够的表征能力和快速适应的能力。
层调制。针对每一层进行调制,作者提供了两种方法,第一种是根据被Sigmoid函数激活的超网络生成的参数与输出的对应元素的积,第二种方法是利用骨干网络上的特征线性调制,超网络对层输出的线性调制产生权值和偏差。
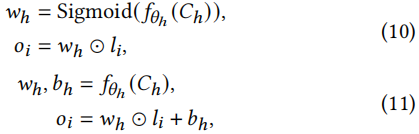
这种方法权重仍是高维,可解释性不强。
软模块化。将每一层网络分为若干个模块,计算当前层的每个模块到下一层的每个模块的概率,生成一个概率矩阵,再根据这个概率矩阵和骨干模型的输出生成输出。
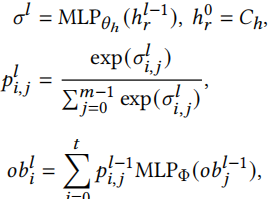
这里没有介绍h如何计算,我猜测是将每层的各个模块结果拼在一起。
这种方法虽然性能稍逊色于层调制,但是它的参数是低维的,有较强的可解释性。
实验结果
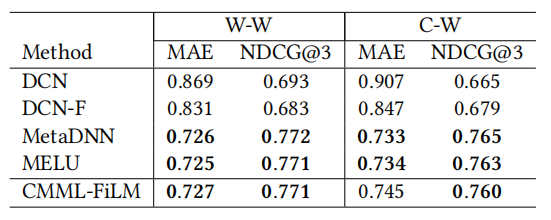
作者在三个数据集上做了相关的实验,此处是场景冷启动,本文提出的方法在淘宝数据集和混合数据集上取得最好的效果,在Movielens数据集上也取得了与\(s^2Meta\)相当的效果。
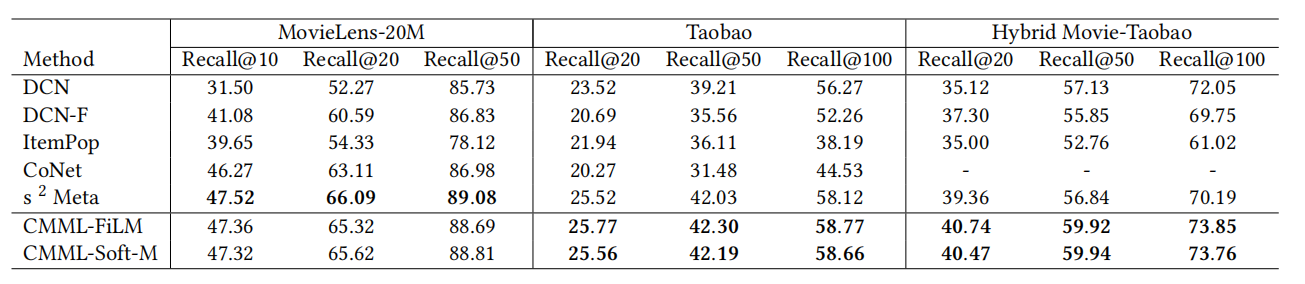
在用户冷启动中也有较好的表现。
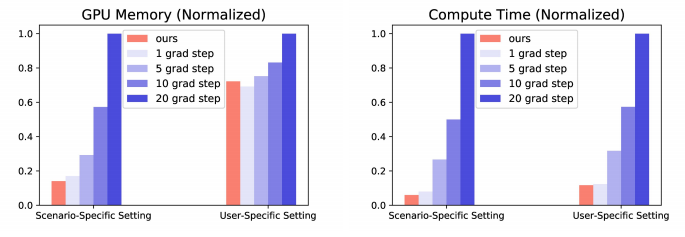
在计算使用资源方面表现优异(对比\(s^2Meta\))。
总结
本文所提出的CMML框架主要由上下文编码器、混合上下文生成器、基于上下文的调制网络这三部分组成,优点是计算速度快且使用资源较少。但是本模型也存在着不稳定的问题,设置不同的初始值可能对模型结果影响较大,而且模型的性能不算突出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号