Alleviating Cold-start Problem in CTR Prediction with A Variational Embedding Learning Framework阅读笔记
动机
本文是2022年WWW上的一篇论文。之前关于冷启动的工作,大多是为新用户或新广告生成一个点(嵌入),但是因为冷启动用户或广告交互数据很少,冷启动用户或广告的嵌入并不是十分可靠,同时这些嵌入非常容易过拟合。为了学习到一个较为可靠的嵌入,同时避免过拟合,本文作者提出了一种通用的变分嵌入学习框架VELF,它为冷启动用户或广告生成一个分布,而不是一个固定的点。
方法
CTR预估
我们有一个数据集\((x,y)\in\mathcal D\),其中x包含了用户、广告、场景的特征,y是标签表示用户是否点积广告,
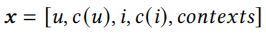
之后通过embedding层,将特征转换为稠密的表示
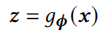
再通过一个MLP和sigmoid激活函数得到最终预测结果
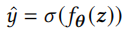
损失函数为交叉熵损失函数
变分推断
变分推断是一种求后验分布p(z|x)的近似解的技术,z是潜在变量,x是观察到的变量。通常,我们可以通过贝叶斯规则求出p(z|x)=p(x,z)/p(x),但由于\(p(x)=\int p(x,z)dz\)难以计算,变分推断通过最大化关于参数\(\Phi_q\)的证据下界(ELBO)来获得最佳近似后验分布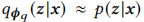
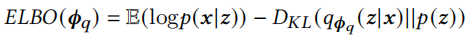
关于变分推断可参考以下文章:如何简单易懂地理解变分推断?和变分推断之傻瓜式推导ELBO
分布估计
作者提出的VELF旨在估计所有的用户与广告的embedding分布,需要学习的模型为\(p_{\phi,\theta}(y|x,z)\),z是观察不到的潜在变量,需要对z的分布进行一个估计,即p(z|x)。我们可以用变分推断来获取一个近似的分布,另外VELF中所有分布都是高斯分布。
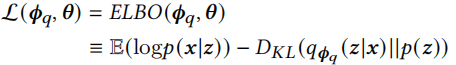
第一项通过最大似然来提高预测的置信度,第二项通过最小化KL散度来找到近似分布。第一项置信度的预测可以看作是log损失函数,KL散度看作是一种正则化,引入一个参数\(\alpha\)来控制其影响。p(z)是这个式子的关键,通常采用高斯分布,但是因为不同用户和广告之间差异较大,用一个固定的先验分布会限制模型的泛化能力,因此在作者提出的方法中,将p(z)参数化为p(z|c),c是用户和广告的ID特征。最终我们的优化目标为
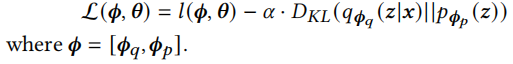
平均场变分嵌入框架
根据平均场理论,我们可以认为用户与广告的潜在变量\(z^u\)和\(z^i\)是独立的,因此优化目标可以重写为如下
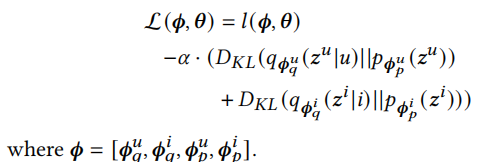
正则化先验
因为之前我们通过ID特征获取了非固定的参数化的ID的先验,这种方法存在过拟合的可能,因此我们强制参数化的先验近似于一个标准正态超先验:
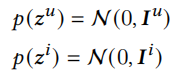
我们的目标函数重写为
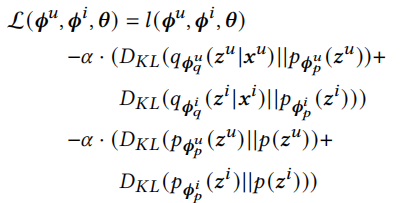
训练
VELF的结构如下图所示。
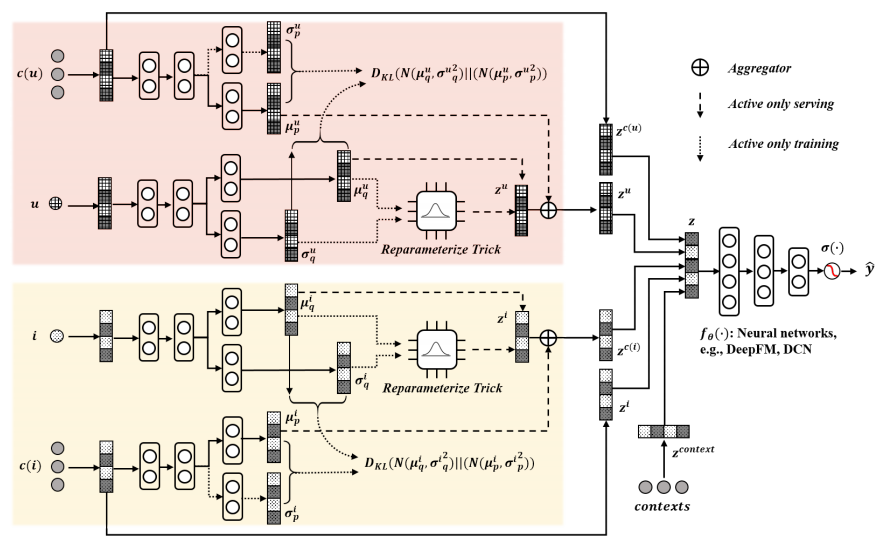
我们以用户u的潜在变量\(z^u\)为例,广告的潜在变量\(z^i\)可以用同样方法得出。通过相关函数获取后验分布和先验分布
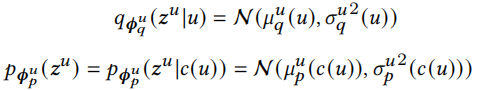
根据分布得出用户的潜在变量
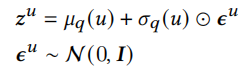
之后根据这些embedding求
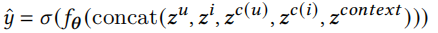
损失函数为
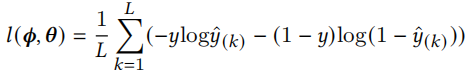
KL散度为(关于这部分推导可以参考KL散度(Kullback-Leibler Divergence)介绍及详细公式推导)
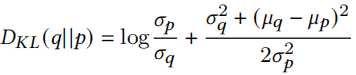
预测
还是以获取用户u的潜在变量为例,
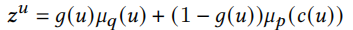
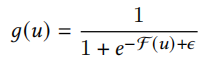
\(\mathcal F(u)\)是训练集中u的累计频率。
得到用户与广告的embedding后,就可以计算用户偏好分数\(\hat y\)。
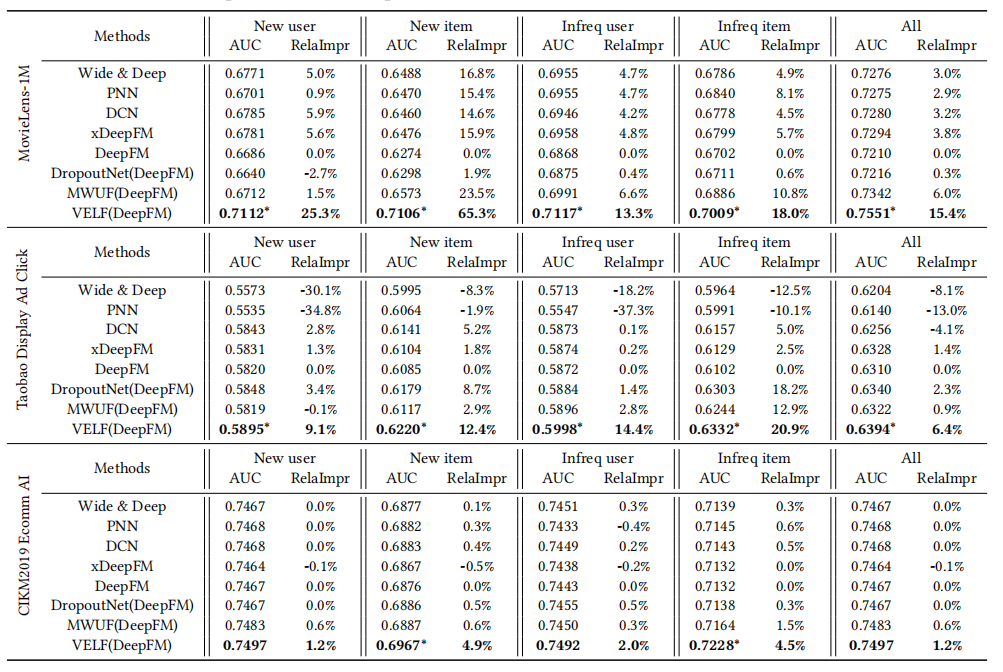
结果
作者以deepfm为骨干网络,进行了实验,在实验中作者提出的VELF在各个场景下都取得最好的效果。
总结
本文提出的解决冷启动问题是通过将用户与物品建模为一个分布,不是一个向量,通过分布采样到对应的embedding,并且结合先验和后验信息,再加入正则化防止过拟合。对于我来说,本文读起来难度有点大,因为我之前没深入了解过变分推断,之后有空再细读一遍文章,争取把每个点都弄懂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号