Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction阅读笔记
动机
本文是2021年SIGIR上的一篇论文。CTR预估任务是在线广告系统中最核心的任务,目前深度学习模型在CTR预估任务中取得了巨大成功,但是这些模型在新广告上效果不佳。之前的一些工作都是从新广告本身来解决这个问题(我的理解是只用到新广告本身的信息),而忽略了旧广告中可能包含的有用的信息。针对上述问题,作者提出了Graph Meta Embedding(GME)模型,它同时利用到了新广告和旧广告的信息,该模型通过图神经网络和元学习快速为新广告生成一个较为理想的embedding。
方法
GME主要包含两部分:1.embedding生成(EG),生成广告的embedding。2.图注意力网络(GAT),自适应提取出有效信息。
作者从不同的角度提出了三个特定的GME,分别是GME-P,利用预训练好的邻居用户id embedding;GME-G,利用生成的邻居节点用户embedding;GME-A,利用邻居属性。
建图
因为GME模型利用到了新广告和相关的旧广告,首先需要构建一个图连接它们。给定一个新广告,我们可以获取该广告的id和相关属性,将新广告与具有相同属性的旧广告连接,这些与新广告相连的旧广告就成为了新广告的邻居。
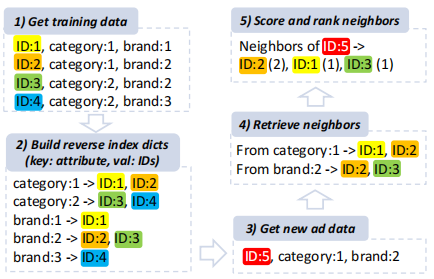
以上图为例,具体流程如下:
1.获取训练数据,得到旧广告的信息。
2.构建一个反索引字典,其中键是属性,值是具有这个属性的广告集合。
3.得到新广告相关信息。
4.根据每个属性找到新广告的邻居。
5.计算相似度分数,例如图中ID为2的旧广告与ID为5的新广告有两个属性相同,它们的相似度就为2。

GME-P
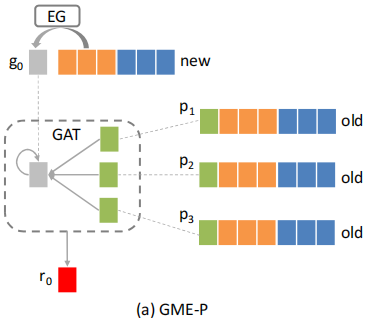
GME-P的思想是我们可以从之前的CTR预估模型得到已经训练好的旧广告的ID embedding得到有用信息。由于新广告未参与之前的CTR预估模型训练,因此我们只有新广告属性的embedding,没有它的ID embedding,本模型的目的就是为新广告生成一个合适的ID embedding。
第一步,得到初步的新广告ID embedding。我们根据新广告相关属性\(x_0\)查询该属性对应的embedding,再将这些属性的embedding拼接成一个长的embedding \(z_0\)。有了\(z_0\)之后通过一个embedding生成器\(g_0=f(z_0)\)就可以得到初步的新广告的ID embedidng \(g_0\)。我们简单将其实例化为
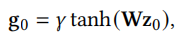
其中\(W\)是可以训练的参数。
第二步,细化embedding表示。我们通过GAT为不同邻居节点分配不同的重要性,计算新广告0和旧广告i之间的注意力系数为
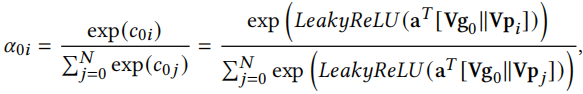
V是可学习的参数。
最后通过加权计算新广告的ID embedding
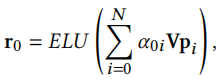
由于我们得到的初步ID embedding是根据属性得来的,它可能和真正的ID embedding并没有很大关系,因此这里使用图注意力网络是没有意义的。
GME-G
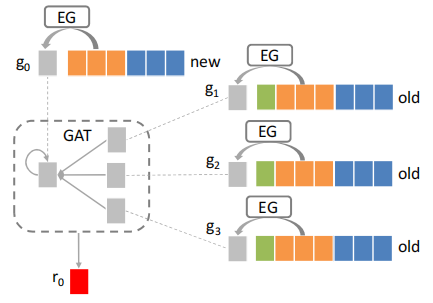
为了克服GME-P中的问题,作者提出了GME-G,GME-G没有使用预训练好的旧广告中的ID embedding,而是为旧广告重新生成ID embedding。
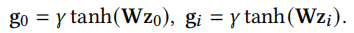
下面步骤和GME-P相同,通过一个图注意力网络计算出注意力系数,然后加权计算出新广告最终的ID embedding。
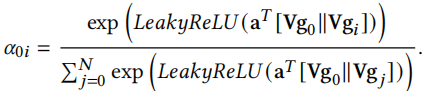
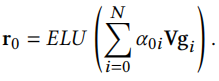
GME-G虽然解决了GME-P中的问题,但是由于它重复为旧广告生成ID embedding,这些embedding中可能包含噪声,重复生成embedding可能会传播噪声。
GME-A
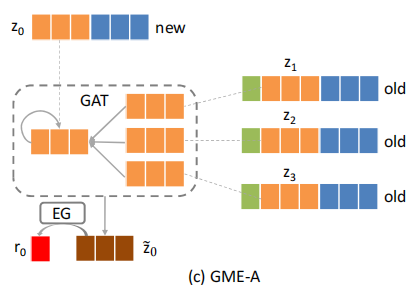
GME-A将生成和细化两个步骤反过来,这里细化的是属性的embedding而不是ID embedding。
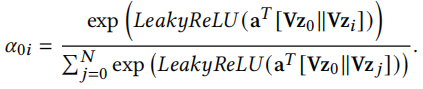
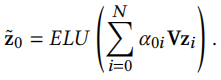
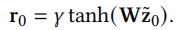
GME-A直接比较新广告和旧广告之间的属性,而且它只是用了一次EG,避免了GME-P和GME-G中的问题。
模型学习
首先,我们训练一个主模型进行CTR预测,这个模型有大量数据参与训练,我们认为它是比较可靠的,因此在接下来训练GME模型时,我们冻结主模型的参数(包括特征嵌入向量和一些其它参数)。在训练GME时,采用MAML,将每个训练广告id当作一个任务。损失考虑有两个方面:1.新广告的CTR预估误差应该要小。2.在收集了少量具有标记的数据后,少量的梯度更新可以快速学习。
给定一个训练过的旧广告\(ID_0\),选两个不相交的小批量标记数据\(D^a\)和\(D^b\),我们使用GME生成的初始ID embedding,计算在\(D^a\)上的损失
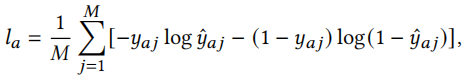
之后根据\(l_a\)更新id embedding \(r_0\)
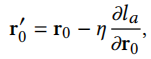
使用更新后的\(r_0^{'}\)计算在\(D^b\)上的损失
最终损失为
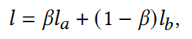
\(\beta\)是平衡两个损失的参数。
实验结果
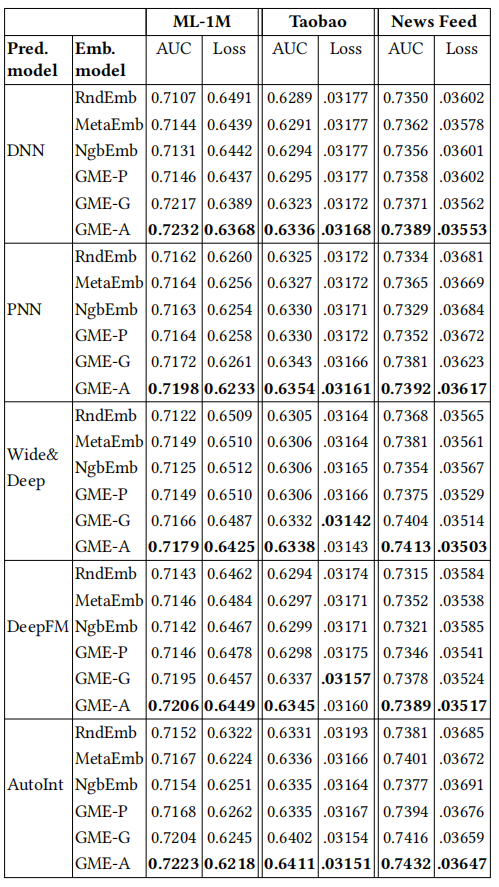
作者在多个主CTR预测模型上评估了冷启动ID嵌入模型,其中GME-A在绝大部分场景下都取得最好效果,这也和作者理论分析的相同。
总结
本文提出的GME核心思想就是首先根据广告属性建图将新广告和旧广告连接起来,再通过旧广告的信息来计算新广告的表示。根据我之前看过的一些推荐系统的论文,这里我有一个想法,通常来讲ID embedding应该携带的信息比一般的属性的embedding应该更具有代表性,如果可以为新广告找到更合适的邻居,并且通过一种更合适的方式计算新广告和旧广告之间的关系,然后将旧广告的ID embedding通过加权或其他方式传给新广告,这样子得到的新广告的ID embedding会不会更好一些?这和GME-P的思想很像,但是GME-P中计算新广告和旧广告之间的关系的方法并不合适,或许这是一个值得思考的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号