Meta Matrix Factorization for Federated Rating Predictions阅读笔记
动机
本文是2020年SIGIR上的一篇论文。之前的大多数研究联邦推荐系统的工作忽略了移动设备的存储、计算能力、通信带宽等方面的限制,本文针对这个问题,提出了MetaMF,它通过为每个移动设备生成物品私有嵌入向量和预测模型,使移动设备在使用一个较小的私人化的模型情况下,可以取得一个较好的效果。
算法
MetaMF主要由三部分组成,分别是协同记忆模块、元推荐模块、预测模块。整体框架如下图。
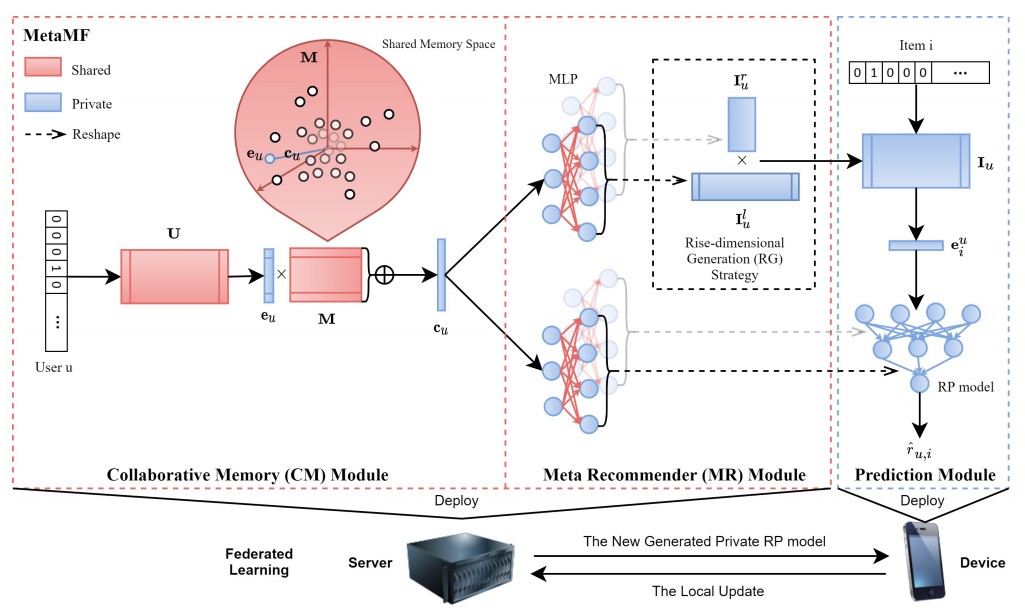
协同记忆模块
我们使用\(i_u\)和\(i_i\)作为用户和物品的指示向量,他们是one-hot向量。我们通过\(i_u\)和用户嵌入矩阵向量\(U\)得到用户的embedding
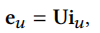
接下来,我们再根据一个共享记忆矩阵\(M\)得到用户的协同向量\(c_u\),这里相当于把用户embedding当成索引
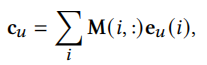
\(M\)中保存着协同向量。
元推荐模块
我们为每个用户生成一个私有的物品嵌入矩阵 ,但是该物品嵌入矩阵过大,直接生成较为困难,我们将其分解为两个低维矩阵\(I_u^l\)和\(I_u^r\)
,但是该物品嵌入矩阵过大,直接生成较为困难,我们将其分解为两个低维矩阵\(I_u^l\)和\(I_u^r\)
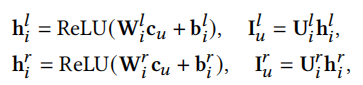
其中W,U为权重,b是偏置,都是可训练的。
最终\(I_u\)通过以下公式获得
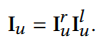
我们为每个用户生成一个私人推荐模型,这部分模型是一个多层感知机MLP,我们通过以下公式生成每层神经网络的\(W^u_l\)和\(b^u_l\)
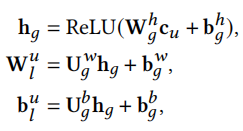
其中W和U是权重,b是偏置,这些是可以训练的。
item_embedding参数数量从\(O(d_i×n)\)降到\(O(d_i×s+s×n)\)。
推荐模块
物品的embedding和推荐模型都是在元推荐模块中生成的。
接下来,我们首先获得物品的embedding
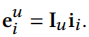
通过以下步骤来预测用户u对物品i的评分
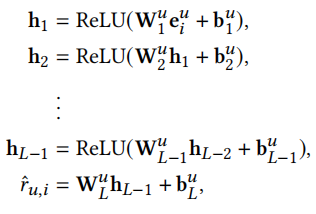
损失函数
损失函数两部分,第一部分是预测模型的损失
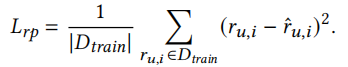
第二部分是正则化损失
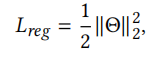
总的损失为
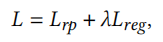
总体流程

结果
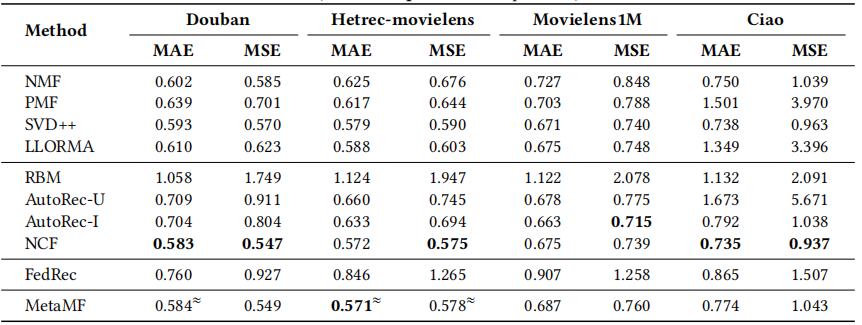
作者在四个数据集上做了实验,本文提出的MetaMF在各个数据集的表现都超越FedRec(也是一种联邦推荐),和集中训练的模型相比,大部分情况下超越了传统的推荐模型,略逊于NCF和AutoRec。
总结
本文提出的MetaMF为每个用户生成私有的物品嵌入表示和预测模型,在模型规模较小的情况下保证了模型的性能。本文提出的MetaMF存在一些隐私泄露问题,因为为用户生成私有的物品嵌入表示和预测模型是在服务器上完成的。同时,它还存在冷启动的问题,在用户拥有个性化数据较少的情况下,模型性能会下降很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号