
CNN Architecture Embedding With Hashing Semantic Feature-老年痴呆自我回忆手册
Hyperspectral Image Classification Method Based on CNN Architecture Embedding With Hashing Semantic Feature
基于CNN架构并嵌入哈希语义特征的高光谱图像分类方法
manifold learning and sparse theory 相关
基于流形学习和稀疏理论的一套高光谱图像分类方法取得了令人满意的性能[5] – [12]。

As the most popular and successful DL framework, convolutional neural network (CNN) utilizes a series of hidden layers to extract hierarchical features that has proved to be effective in HSIC [14]–[20].
作为最流行和成功的DL框架,卷积神经网络(CNN)利用一系列隐藏层来提取分层特征,这些特征在HSIC中被证明是有效的[14] – [20]。


Nowadays, the fused profiles fed into the CNN network mainly obtained by the HSI data transformation or segmentation results [21]–[24] ,Motivated by adding semantic features of HSI which can improve the classification efficiency and performance [25],
如今,馈入CNN网络的融合轮廓主要是通过HSI数据转换或分割结果获得的[21]-[24],其动机是通过添加HSI的语义特征来提高分类效率和性能[25]

in this paper, we presented a new classification method with hashing semantic feature fused into the CNN architecture On one hand, hash learning is used to encode both spectral features and spatial neighborhood information simultaneously to improve the distinguishing ability of the different classes. On the other hand, we adopted a simpler CNN architecture with two convolution layers to explore the classification features .
在本文中,我们提出了一种将哈希语义特征融合到CNN架构中的新分类方法,一方面,哈希学习用于同时对频谱特征和空间邻域信息进行编码,以提高不同类别的区分能力。另一方面,我们采用了具有两个卷积层的更简单的CNN架构来探索分类特征。
The paper contributes to the literature containing three major aspects
1)我们通过考虑特征类别之间的局部性和判别性学习子空间,并在语义上使用紧凑代码对高光谱数据进行编码,提出了一种新的语义特征提取方法。利用定义的类内和类内相似性约束,提取的特征通过最大化样本中心距离为后续的CNN框架提供了显着的分类信息。
2)除频谱和空间信息外,所提出的CNN分类体系结构还利用原始HSI多维数据集中合并的提取语义特征,实现了强大的区分能力,同时探索了卷积特征和语义上下文信息.
3)采用更简单的包括两个卷积层的CNN网络进行HSI分类,并设计去卷积层以增强深度特征,从而提高分类框架的鲁棒性。此外,为了演示反卷积层的性能和预处理的哈希过程,我们还设计了其他几种CNN架构来相应地评估分类性能。

A. Hash Function Definition
where N is the number of the data sample
is the kth data sample of the HSI cube ,and L is the total number of spectral bands.
We define categories of pixels denoted as
其中N是数据样本的数量,是HSI多维数据集的第k个数据样本,L是频谱带的总数。我们定义像素类别为
depends on whether the pixel is the target pixel or not, value “0” indicates that it is not the target of the ith class and “1” shows it is the target of the ith class.
取决于像素是否是目标像素,值“ 0”表示它不是第i类的目标,而值“ 1”表示它是第i类的目标。
In this paper, a series of hash functions are defined as h the value of the hash function
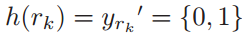

where w is the subspace projection vector and b is the offset
本文将一系列哈希函数定义为h哈希函数的值,其中w是子空间投影向量,b是偏移量
The within-class similarity in the same class should be small after the hash function , while the intraclass similarity between classes should be increased.
类内 需要变小,类间需要提高
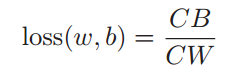
where CB denotes the intraclass similarity, while the CW denotes the within-class similarity
CB 类间,CW类内
B. Similarity Preserving
1)类内相似度:为了使最终的哈希映射代码能够更好地区分类和非类信息,类内相似度包括相同类和不同类之间的相似度。在本文中,我们用类中心的欧几里得距离评估了类之间的相似性。
对于第i类Ci, Ci和 非第i类中心ui之间的相似度等级定义如下:
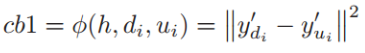
其中di是由Ci类的样本均值定义的Ci的聚类中心,而ui是定义如下的非第i类中心:
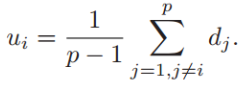
此外,Ci和Cj之间的相似度等级定义如下:
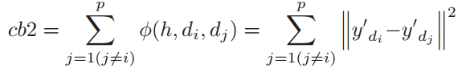
其中di和dj是与上述定义相同的Ci和Cj的类中心。
2)组内相似度:通过计算三种类型的距离来衡量组内相似度。一方k面,由于相同类别的样本之间的位置会具有相同的原始特征,对于Ci样本,\(r_k∈C_i\),\(r_k\)样本与类别\(C_i\)中心之间的距离
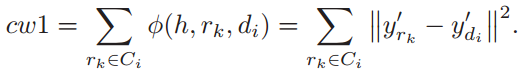
另一方面,为了强调空间特征对局部邻域的影响,通过计算像素\(r_k\)与邻域像素之间的距离来衡量其他类内相似度。
对于类\(C_i\)中的样本,\(C_i\)的邻居哈希值的度通过如下计算邻居之间的距离来定义:
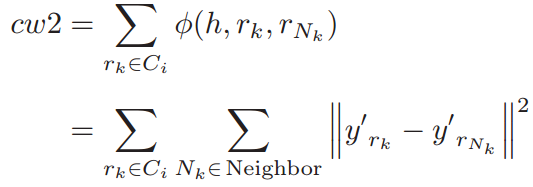
where \(N_k\) denotes the neighbor pixels of \(r_k\).
对于\(u_i\)类中的样本,第\(l\)个样本之间的距离旨在测量第\(l\)个样本与\(u_i\)之间的类内相似度,如下所示:
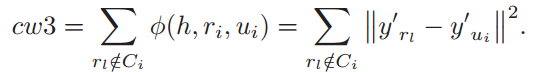

 浙公网安备 33010602011771号
浙公网安备 33010602011771号