

Python数据结构字典-dict
字典的定义
字典是key、value键值对的数据集合,字典是可变的、无序的、key值不重复。
字典dict初始化
d = dict()或者{},表示空字典
dict(**kwargs)使用name=value键值对初始化一个字典
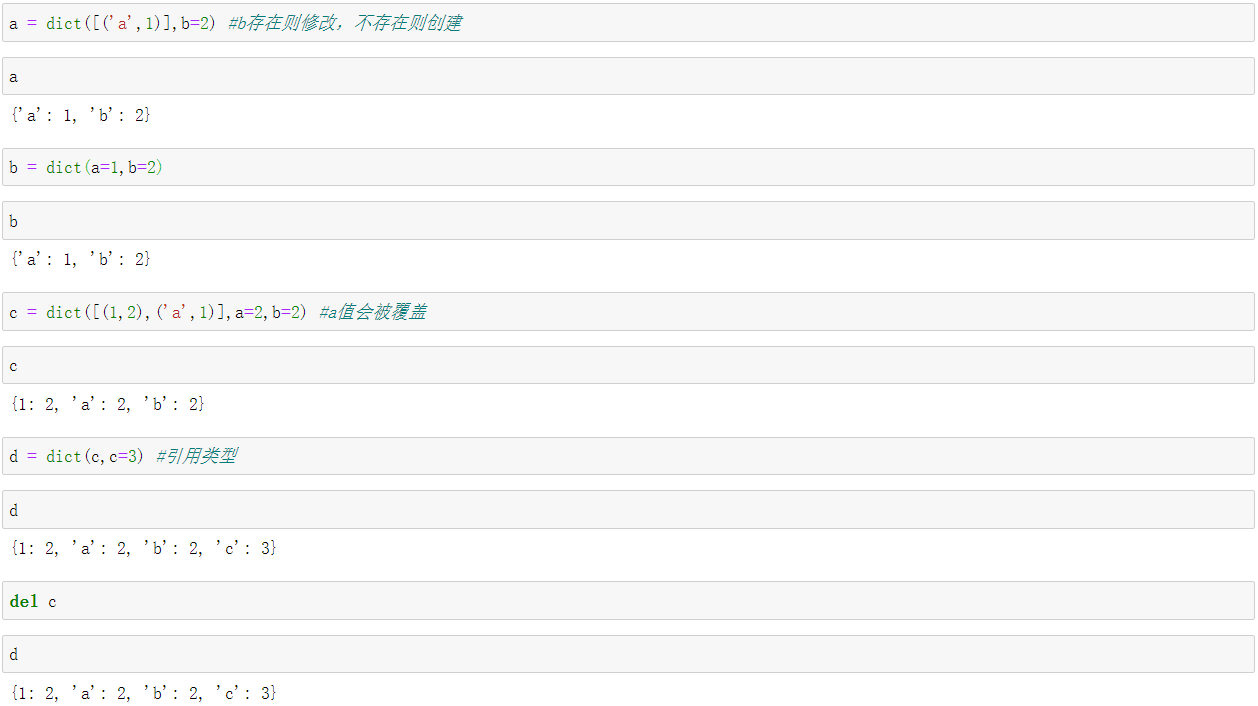
dict(mapping) -> new dictionary initialized from a mapping object's;使用字典构建另一个字典
dict(iterable) -> new dictionary initialized as if via:使用可迭代对象和name=value键值对构造字典,不过可迭代对象的元素必须是一个二元组,一个二元结构
示例:
d = dict(((1,'a'),(2,'b'))) d = dict(([1,'a'],[2,'b']),c=200)
d = {'a':10,'b':20,'c':None,'d':[1,2,3]}
#d1 = dict((('b','1'))) # 报错 ValueError: dictionary update sequence element #0 has length 1; 2 is required #d1 = dict(((1,'a'))) # TypeError: cannot convert dictionary update sequence element #0 to a sequence d = dict((('k','1'),('b','2'))) d = dict(('k','1'),) # 错误 d1 = dict((('k','1'))) #错误的 d1 = dict((('k','1'),)) #正确 d1 = dict([['a','a']]) #正确 d1 = dict((['a','a'])) #错误 d1 = dict((['a','a'],)) #正确
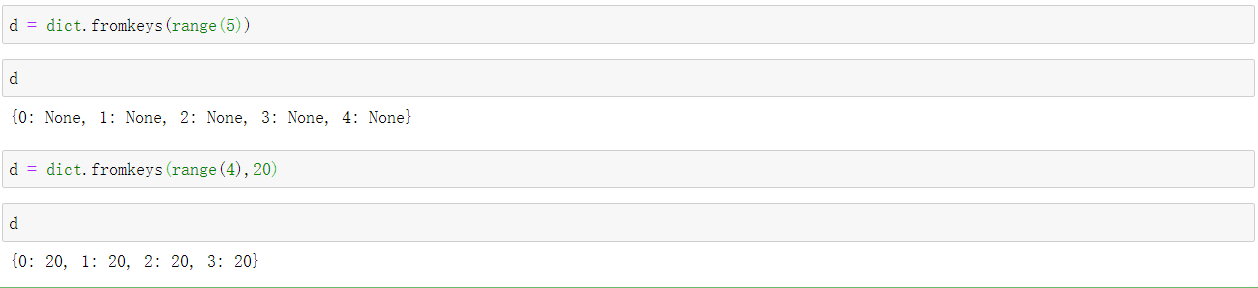
类方法:dict.fromkeys(iterable,value) value为填充值,不写默认使用None进行填充
d = dict.fromkeys(range(4),20)
d = dict.fromkeys(range(5))
d = dict.fromkeys(('abcdef),100)


1 str1 = "a1:1|a2:2|a3:3" 2 lst1 = str1.split('|') 3 dict1 = {} 4 for k in range(len(lst1)): 5 dic = dict([lst1[k].split(':')]) 6 dict1.update(dic) 7 print(dict1) 8 9 for i in lst1: 10 k,v = i.split(':') 11 dict1[k] = v 12 print(dict1)
字典元素的访问
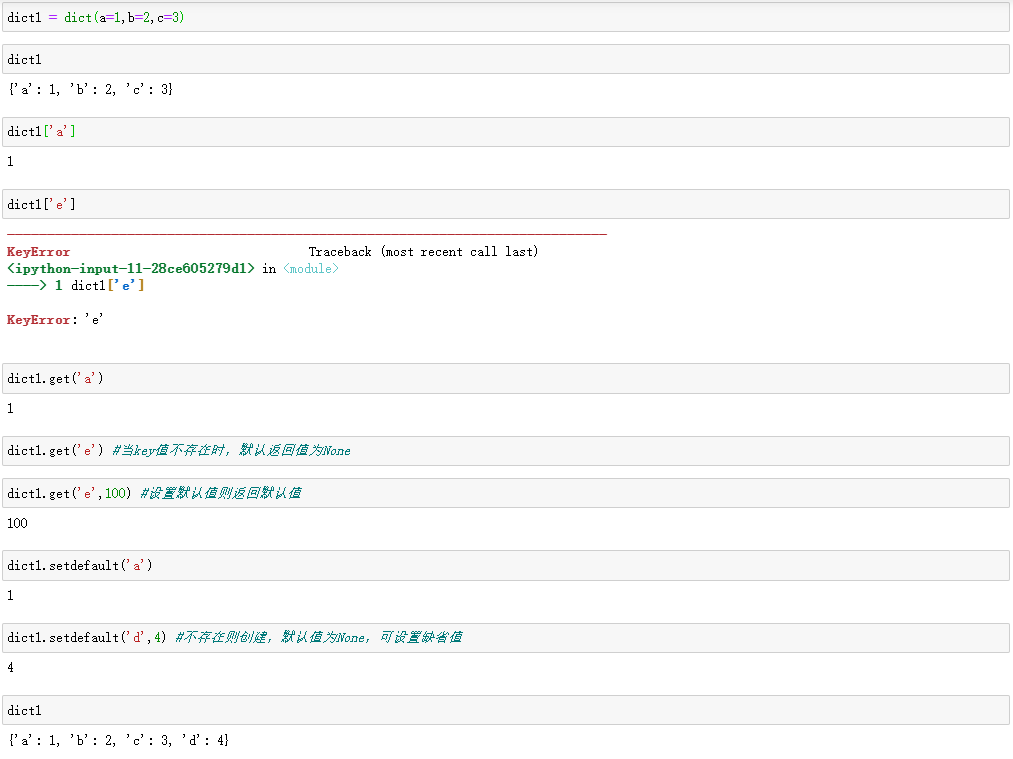
d[key]:返回key对应值value,key不存在则爆出异常KeyError
get(key,[default]):返回key对应的值,如果key不存在则返回缺省值,默认为None,可自行定义返回值
setdefault(key [default]):返回key对应的值value,key不存在添加kv对,value设置为default,并返回default,如果default没有设置,缺省值为None
字典的增加和修改
d[key] = value:将key对应的值修改为value,key不存在则增加新的k/v对
update([other]) ->None:使用另一个字典的kv对更新本字典,key不存在就添加,key存在则就覆盖原有的key对应的值,就地修改

字典删除
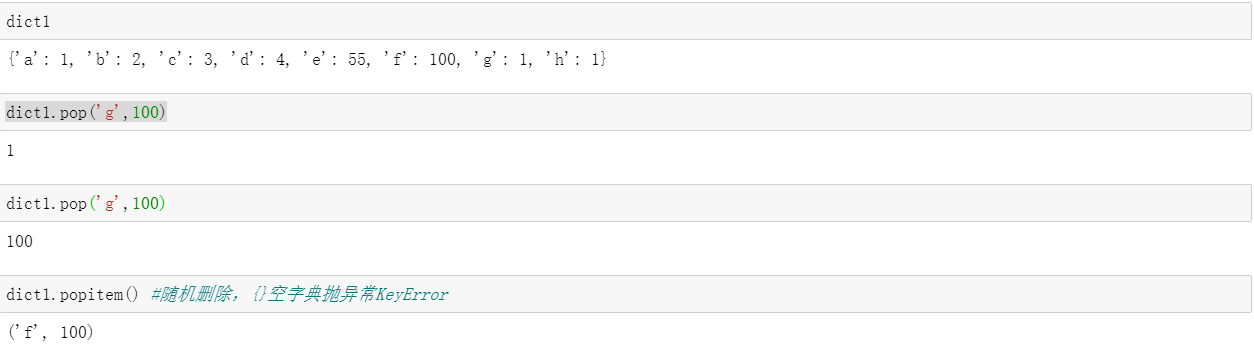
pop(key[,default]):key存在则移除他,并返回他的value,key不存在返回给定的default值,default值不设置,key不存在则抛出异常
popitem():移除并返回一个任意的键值对,字典为empty则抛出异常KeyError
clear():清空字典
del dict:删除对象引用
字典的遍历
for ... in dict
遍历key:
for k in d:
print(k)
for k in d.keys():
print(k)
遍历value:
for k in d:
print(d[k])
for k in d.keys():
print(d.get(k))
for v in d.values():
print(v)
遍历key-value对,item:
for item in d.items():
print(item)
for k,v in d.items():
print(k,v)
for _,v in d.items():
print(v)
for k,_ in d.items():
print(k)
遍历总结:
Python3中keys、values、items方法返回一个类似一个生成器的可迭代对象,不会吧函数的返回结果复制到内存中,dictiona view对象,可食用len()、iter()、in操作
字典的entry的动态视图,字典的变化,视图将反应出这些变化
keys返回一个类set对象,可就是可以看做是一个set集合。如果values都可hash,那么items也可以看做类的se对象,取决于values值得类型,为可hash还是不可hash
Python2 中,上面的方法会返回一个新的列表,占据新的内存空间,索引Python2 中建议使用iterkeys. itervalues,iteritems版本,返回一个迭代器,而不是一个copy
字典的遍历和移除
字典在遍历自身的时候长度不能改变,否则抛异常,则需将需要删除keys取出来,迭代keys,再次使用pop('keys')进行删除
d = dict(a=1,b=2,c='123') keys =[] for k,v in d.items(): if isinstance(v,str): keys.append(k) print(keys) for k in keys: d.pop(k) print(d)
字典的key值
key的要求和set元素要求一致,set元素可以看做key,set可以看做dict的简化版,可hash才能作为key,可使用hash()测试
defaultdict
使用此函数,需from collections import defaultdict;collections.defaultdict([default_factory[,....])
第一个参数是default_factory,缺省值为None,它提供一个初始化函数,当key不存在的时候,会调用这个工厂函数来生成key对应的value
d = {} for i in 'abcdefg': for j in range(3): if i not in d.keys(): d[i] = [] d[i].append(j) print(d)
import random d1 = {} for k in 'abcdef': for i in range(random.randint(1,10)): if k not in d1.keys(): d1[k] = [] d1[k].append(i) print(d1)
from collections import defaultdict import random d1 = defaultdict(list) for i in 'abcdef': for j in range(random.randint(1,5)): d1[i].append(j) print(d1)
OrderedDict
collections.OrderedDict([items]):key并不是按照加入的顺序排列,Python3.6以上看到的是按照加入顺序排序的,实际是无序的,
Python内部做了一些优化,3.6以下则是无序的,可以使用OrderedDict记录顺序。有序字典可以记录元素插入的顺序,打印的时候也是按照这个顺序输出打印
from collections import OrderedDict import random d = {'a':1,'b':2,'c':3} print(d) keys = list(d.keys()) random.shuffle(keys) print(keys) old = OrderedDict() for key in keys: old[key] = d[key] print(old) print(old.keys())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号