

Python封装与解构
封装
将多个值使用逗号分隔,组合在一起,本质上返回的是元组,只是省略了小括号;
t1 = (1,2) t2 = 1,2,3 print(t1,t2) ((1,2),(1,2,3)) type(t1),type(t2) (tuple, tuple)
a = 4 b = 5 temp = a a = b b = temp #如果不使用封装解构,则需要通过中间变量两记录a的值,否则变量在赋值的过程中就丢失
等价于下面的写法: a,b = b,a #右边使用了封装、左边使用了解构
解构
把线性结构的元素解开,并顺序的赋值给其他变量,左边接纳的变量要和右边解开的元素个数一致,否则抛出异常:ValueError: too many values to unpack (expected 2)
使用*变量名接收,但不能单独使用,被 *变量名收集后组成一个列表
lst = [3,5] first,second = lst print(first,second) #3,5 a,b = 1,2 a,b = (1,2) a,b = {1,2} a,b = {'a':1,'b':1} # a,b #字典解构值保留key值 a,b = [1,2] a,*b = 10,20,30 # (10,[20,30]) #使用*变量名接收,但不能单独使用,被 *变量名收集后组成一个列表
示例:
lst1 = list(range(1,20,2)) lst1 [1, 3, 5, 7, 9, 11, 13, 15, 17, 19] head,*mid,tail = lst1 mid [3, 5, 7, 9, 11, 13, 15, 17]
a,*b,c = 'abcdefg'
# head,*mid,*other,tail = lst1 #这种写法是错的,无法解构
# *all = lst1 也是错误的写法
丢弃变量
这是一个管理,是一个不成为的约定,不是标准,如果不关心一个变量,就可以定义该变量的名字为_
_是合法的标识符,也可以作为一个有效的变量使用,但是定义为下划线就是希望不被使用,除非明确知道这个数据需要使用
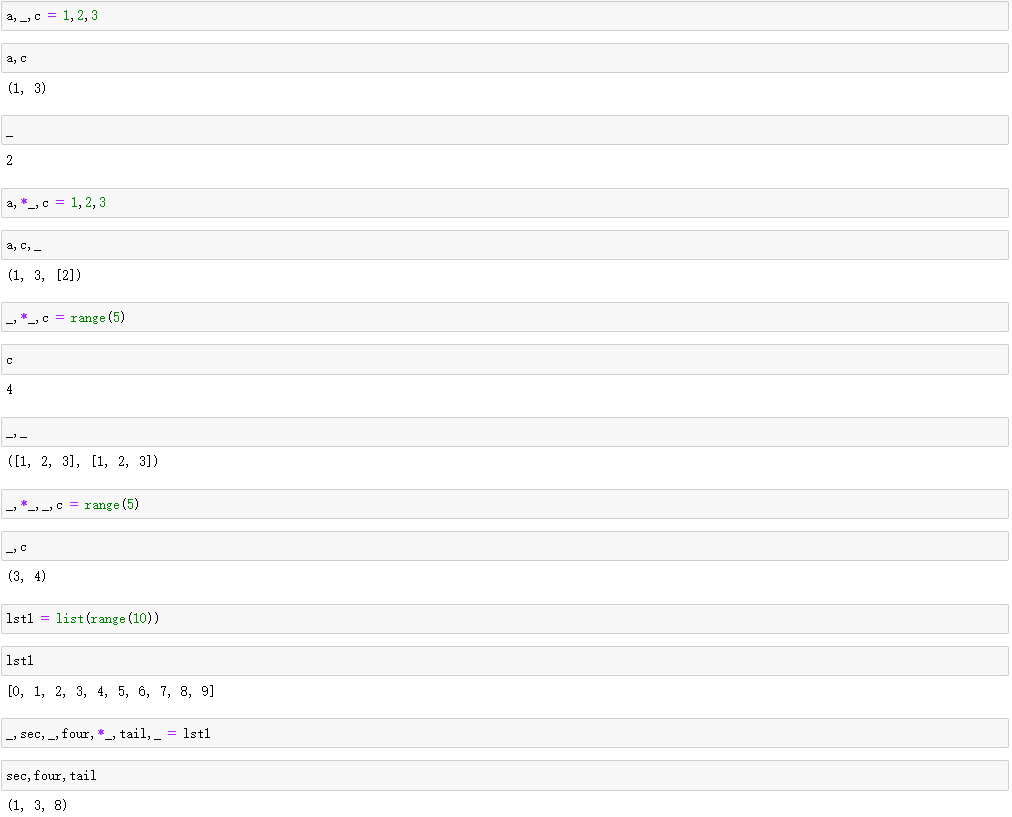
_,*_,_,c = range(5) #这种情况前面的的_会被后面的_覆盖 _,c 返回:(3,4)
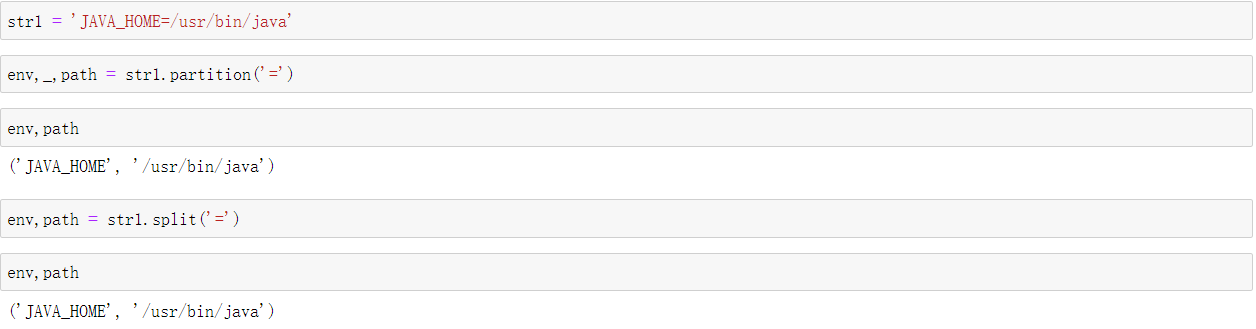
str1 = 'JAVA_HOME=/usr/bin/java' env,_,path = str1.partition('=') env,path env,path = str1.split('=') env,path
使用冒泡法进行排序,同时使用封装结构实现数据交换
nums = [1,9,8,7,6,4,3,2] length = len(nums) count = 0 swap = 0 for i in range(length): flag = False count +=1 for j in range(length -i -1): if nums[j] > nums[j+1]: nums[j],nums[j+1] = nums[j+1],nums[j] flag = True swap +=1 print(nums) if not flag: break print(nums) print(count,swap)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号