

Python内置数据结构--字符串
一、字符串
定义:
1、一个字符组成的有序的序列,是字符的集合,示例:‘abcd’
2、使用单引号、双引号、三引号引住的内容字符序列
3、字符串是字面常量,一旦定义,不可修改,且有序、可迭代
初始化:
示例:

r前缀:所有的字符都是本来的意思,没有转义,例如\n代表换行,加了r前缀则只表示'\n'字符
f前缀:3.6开始,使用变量插值
索引
字符串是有序的序列,支持下标访问,但不可变,不可修改元素。
sql = "select * from user where name = 'tom'"
sql[5] ----> 't'
sql[5] = 'abc' #不可修改,执行则抛异常
'str' object does not support item assignment
有序的字符序列是可以用for循环进行迭代:
示例:
for i in sql:
print(type(i),i)
返回单个字符串常量,'s' ,'e','l','e','c','t'........
连接: + 加号
将字符串连接起来,返回一个新的字符串
i = 1
j = 2
str(i) + '*' + str(j) + '=' + str(i*j) 返回:'1*2=2'
join方法:
使用指定的字符串作为分隔符,将可迭代对象中的字符串使用这个分隔符进行分隔
可迭代对象必须是一个字符串,返回一个新的字符串
示例:

'+++'.join('abc') 'a+++b+++c'
print(';'.join(range(5))) #可迭代对象必须是字符串,次数表示错误
print(';'.join(map(str,range(5))))
字符查找:find
find(sub,[,start[,end]]): 在指定的区间,从左到右[start,end],从左到右,查找子串,找到返回正索引,找不到返回-1,如超界则返回-1
rfind(sub,[,start[,end]]): 在指定的区间,从右到左[start,end],从右到左,查找子串,找到返回正索引,找不到返回-1,如超界则返回-1
示例:
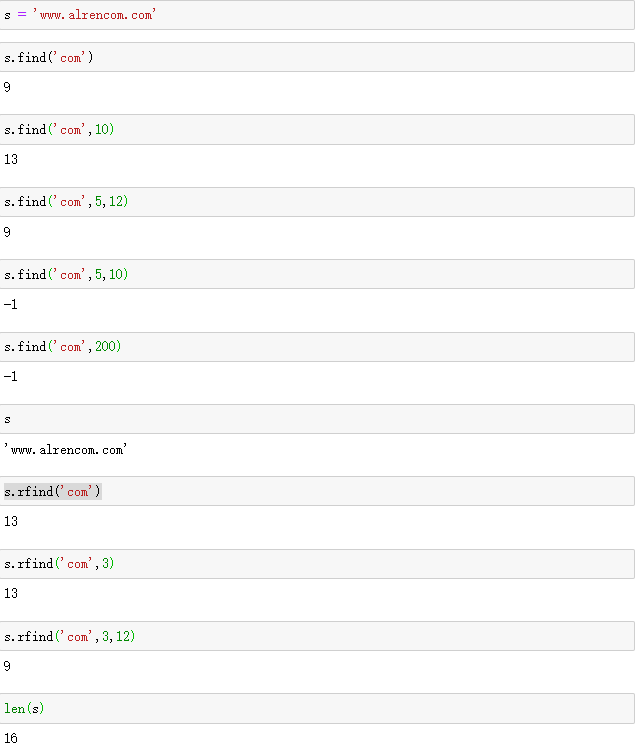
这两个方法只是找到字符串的方向不同,返回值是一样的,找到第一个满足要求的子串立刻返回,特别注意返回值,找不到返回值是负数 -1
两种方法的效率都不高,都是在字符串中遍历搜索,但是如果找子串的工作必不可少,那也不得不这做,但能少做就少做,
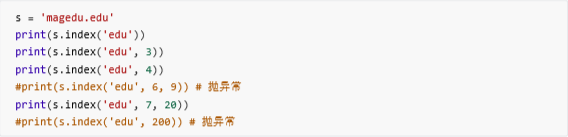
index()方法和find()方法类似,index不好的地方在于,找不到抛异常,推荐使用find方法。
count(sub,[start,[end]]): 在指定的区间内[start,end],从左到右 统计子串出现的次数,找到这返回出现几次,找不到则返回0
s.count('com')
#返回2
s.count('com.cn')
#返回0
时间复杂度问题:
find、index、count方法时间复杂度都是O(n),随着规模的增大效率下降。
len('string') : 返回字符串的长度,即字符的个数,转义字符算做一个字符长度,例如:\t \n

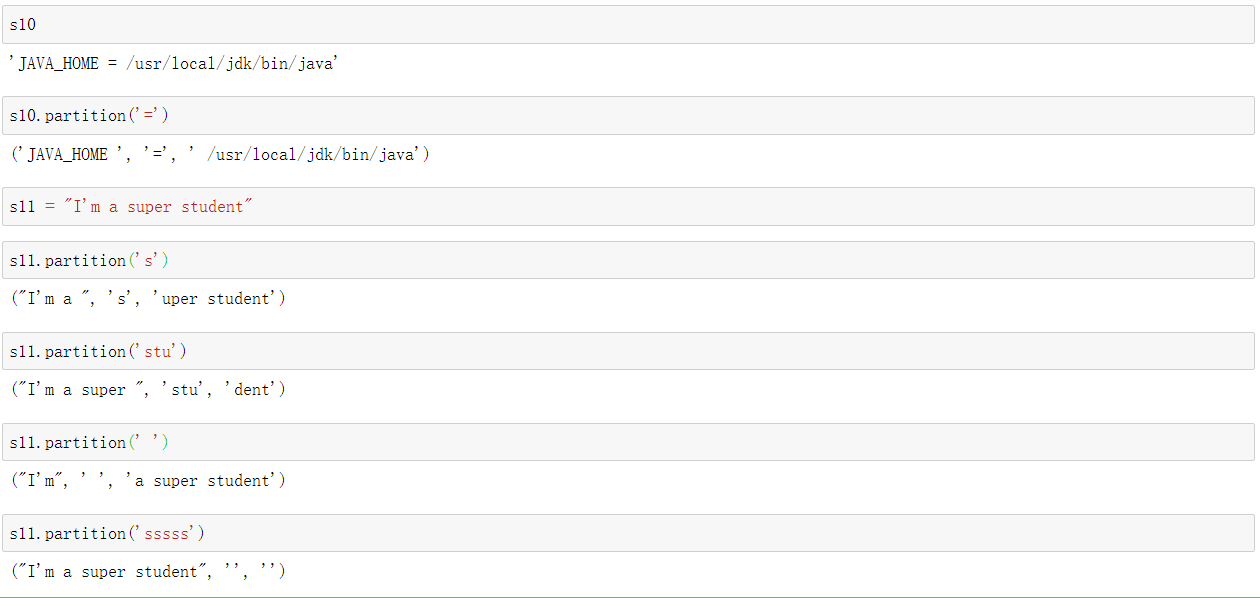
字符分割:split partition
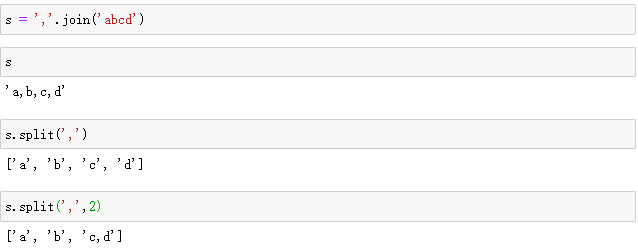
split:将字符串按照分隔符分隔成若干份个字符串,并返回列表
partition:将字符串按照分隔符分隔成两段,返回这两段和分隔符的元组
split(sep=None,maxsplit=-1) -> list of strings
从左到右切割
sep指定切割符,缺省的情况下使用空白字符作为分隔符
maxsplit指定分隔的次数,默认-1表示遍历整个字符串,立即返回列表
返回切割符和被切的字符串元组
rsplit(sep=None, maxsplit=-1) -> list of strings
从右到左,sep指定分隔符,缺省情况下为空白字符作为分隔符
maxsplit指定分隔的次数,-1表示遍历整个字符串
立即返回列表

splitlines([keepends]) ---> list of string
按照行来切分字符串,keepends指的是是否保留行分隔符,行分隔符包括\n 、\r等

字符替换:replace
replace(old,new,[count])在 字符串中找到匹配的字符串替换成新的子串,返回新字符串,count代表替换的次数,不填则默认全替换

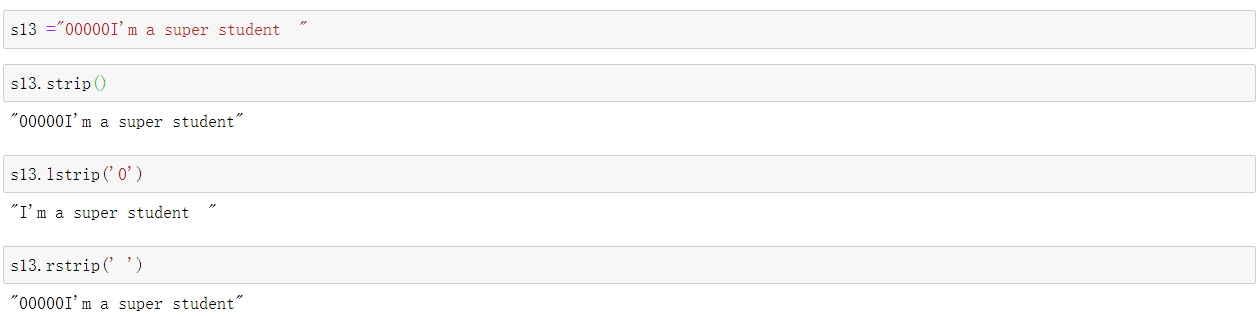
字符移除:strip
strip([chars]) --> str 从字符串的两端去除指定的字符集chars中的所有字符,如果没有指定字符,则去除两端的空白字符
lstrip([chars]) 从左到右
rstrip([chars]) 从右到左
字符串判断:
S.endswith(suffix[, start[, end]]) -> bool :
在指定的区间[start,end],字符串是否是suffix结尾
S.startswith(preffix[, start[, end]]) -> bool :
在指定的区间[start,end],字符串是否是preffix开头

其他函数:
isalnum() --> bool :是否是字母和数字
isalpha():是否是字母
isdecimal():是否只包含了十进制数字
isdigit():是否全是数字
isidentifier():是否是字母和下划线开头、其他都是字母、数字、下划线
islower():是否都是小写
isupper():是否都是大小
isspace():是否只包含了空白字符
swapcase():大小写交换
title():标题每个单词都大写
capitalize():首个单词大写
字符串格式化:
join拼接只能使用分隔符,且要求被拼接的是可迭代对象且元素是字符串。
+ 号拼接字符串需要先转换为字符串才能拼接
格式要求:
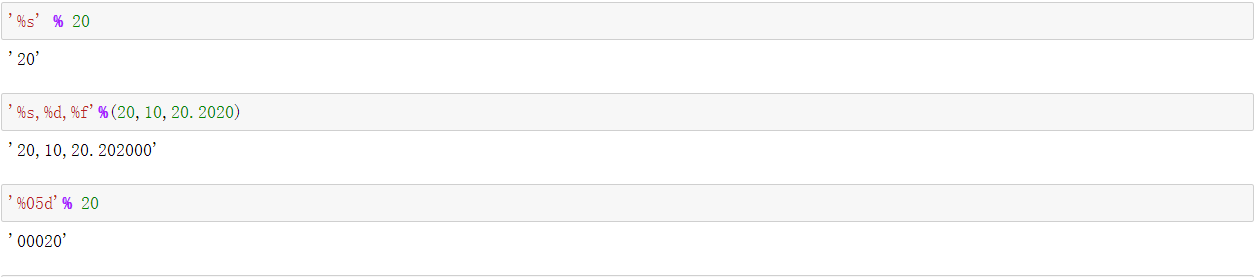
占位符:使用%和格式字符组成,例如:%s %d %f等
占位符中还可以插入修饰字符,例如%03表示打印3个位置,不够前面补零
format % values,格式字符串和被格式的值之间使用%分隔
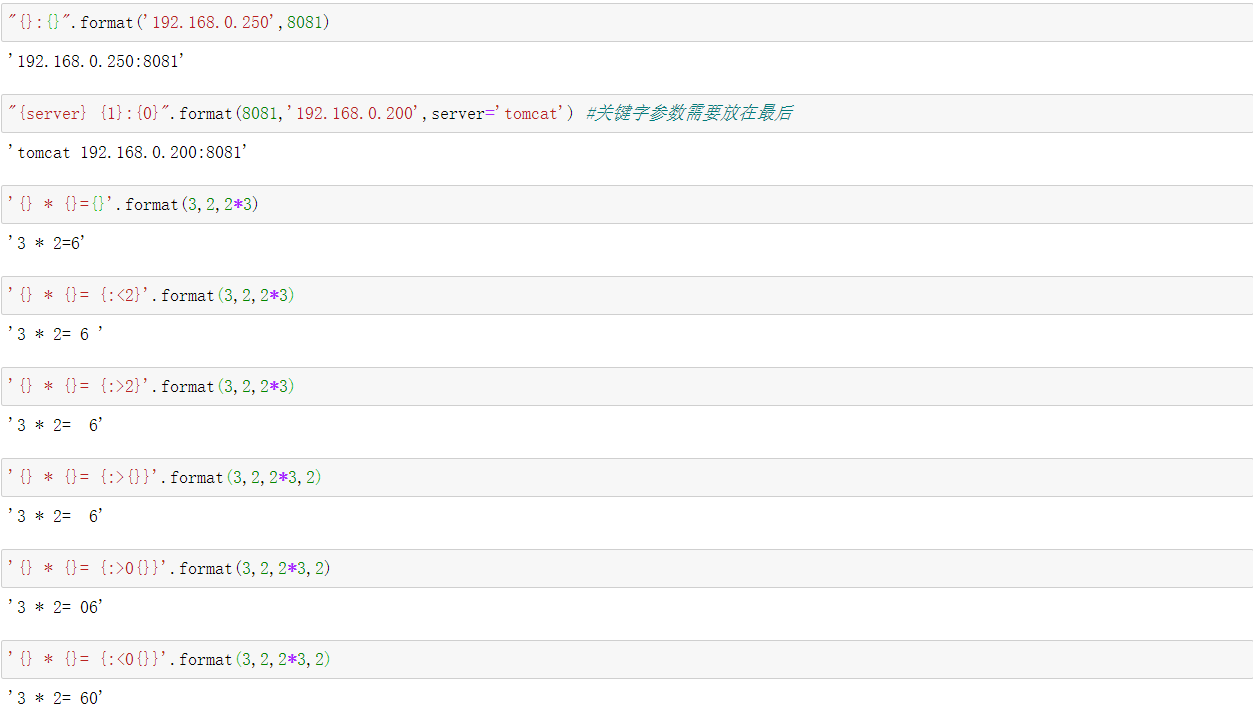
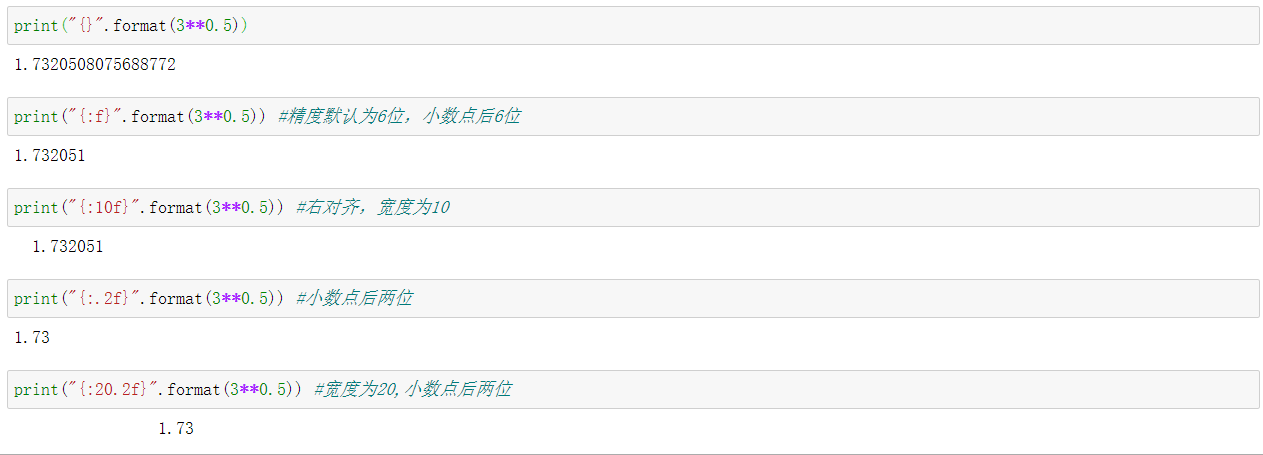
format函数格式化字符串语法--Python鼓励使用:
"{} {XXX}".format(*args,**kwargs) --> str
args 是可变位置参数 ,是一个元组
kwargs 是可变关键字参数,是一个字典
花括号表示占位符
{} 表示按照顺序匹配位置参数,{n} 表示取位置参数索引为n 的值
{xxx} 表示在关键字参数中搜索名称一致的
{{}},表示打印花括号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号