

Python线性数据结构-列表list
一、Python内置数据结构
1、分类:
数值型
int、float、complex、bool
int:Python3的int就是长整型、而且没有大小限制,受限于内存区域的大小,示例:1
float:由整数部分和小数部分组成,支持十进制和科学计数法的表示,示例:5.0
complex:有实数和虚数部分组成,实数和虚数部分都是浮点数,示例:3 + 5j
类型转换:
int(x):返回一个整数
float(x):返回一个浮点数
complex(x):返回一个复数
bool(x):返回布尔值
序列
字符串str、bytes、bytearray
列表list、元组tuple
键值对
集合set、字典dict
2、数字的处理函数
在使用之前需要导入math函数,主要有floor() 、ceil()、int()、round() //
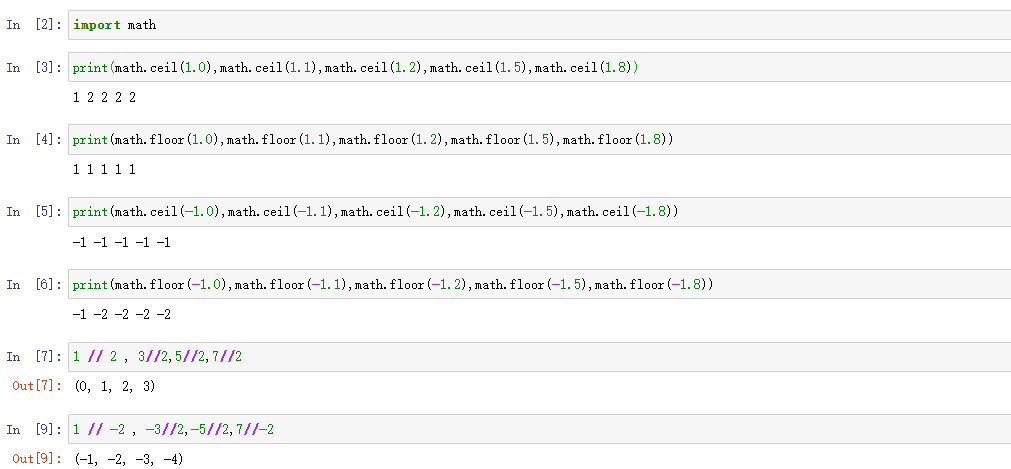
如上述示例,则能总结出:运算符 // 取整是向下取整,而floor()则是向下、celi()向上取整。
int则是取整数部分,不管小数部分的大小,round()模块则是4舍6入5取最近的偶数。
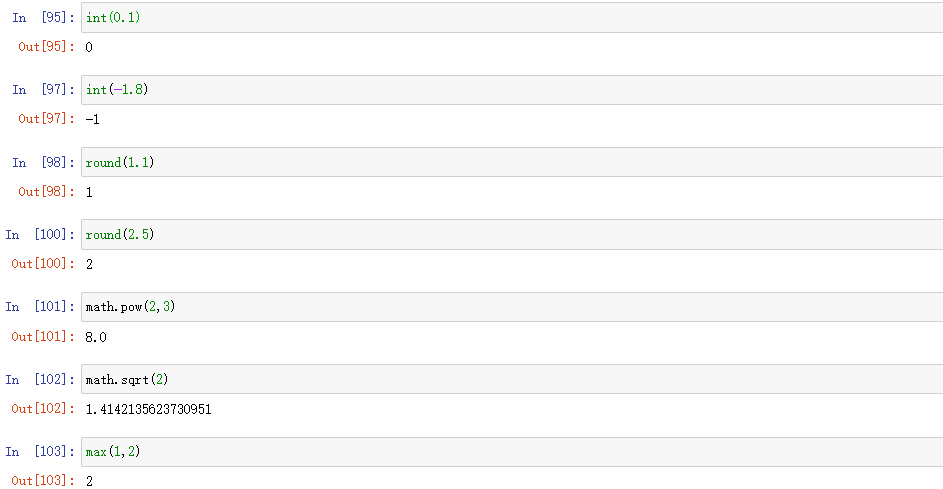
import math
有如下函数:math.pi 3.14 math.sqrt 开方等
3、类型的判断
type(obj),返回类型,而不是字符串
isinstance(obj,class or tuple)返回bool值
id 则是用来查看内存地址

4、列表
定义:一个队列,一个排列整齐的队列,列表内的个体称为元素,由诺干个元素组成列表,元素可以是任意对象(数字,字符串,列表,对象等)
列表内的元素是有顺序的,可以使用索引,线性数据结构,使用[]表示空列表,列表是可变的。
列表list 、链表 linked、队列queue、 stack栈的差异:
列表:连续的内存空间,有序的,可索引的,追加(O(1)),查询都很快(通过索引值,偏移量),但是删除、增加元素,比较慢,需要遍历元素
链表:非连续的内存空间,但是也是有序的,可以索引(在内存空间中是散落的,但是内存地址不是连续的),查询比较慢,都得从开头找,插队,删除都比较快,只需要找前后的内存地址就可以。
队列:先进先出,基于地址指正遍历数据可以从进的一端或者出的一端 ,但是不能同时访问,不需要开辟新的空间
栈:后进先出,遍历数据只能从入口端遍历,如果查找一个最先放进去的数据,需要遍历所有的数据,同时遍历数据需要开辟新的内存空间
列表的声明方式有两种:[] list(可迭代对象) 表示。示例: list(range(10))
列表是容器,可容纳其他的元素:
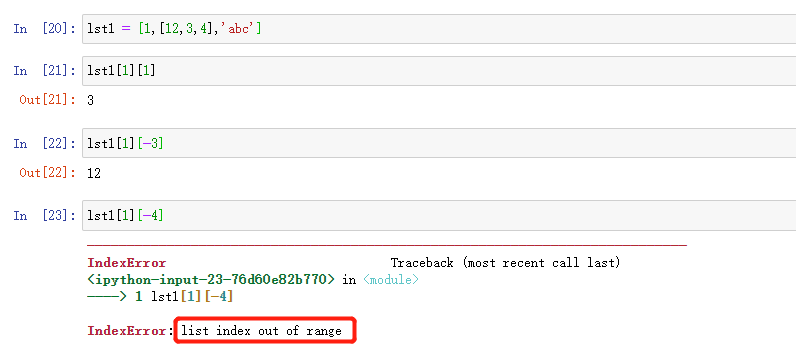
列表的索引访问:
索引,也叫下标,从0开始,到长度减去一;分为正索引和负索引,负索引从-1开始,正负索引不可超界,否则发生异常,indexError .
列表查询:
L.index(value, [start, [stop]]),通过value,从指定的区间查找列表内的元素是否匹配,匹配到第一个就立刻返回索引位置
匹配不到抛出异常
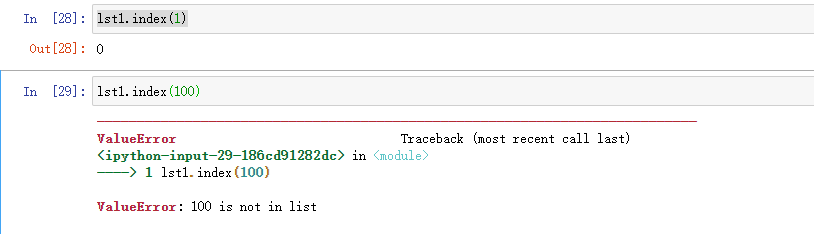
L.count(value):返回列表中匹配的value的次数
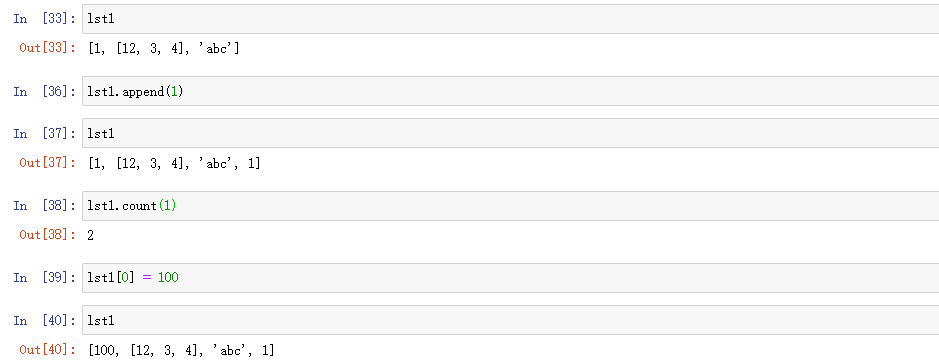
index和count的时间复杂度都为O(n),会随着规模的增大效率下降,建议少用。
如何返回列表表示元素的个数?则用到了len()函数,其时间复杂度为O(1) 默认不需要遍历,会在列表最后有记录
列表元素修改:
索引访问修改:
list [ index ] = value 注:index不能越界,抛出 IndexError异常,效率高
列表的增加和插入:
append():列表尾部追加元素,返回None,就地修改,一次只能插一个元素,时间复杂度为O(1)
insert():在指定的索引处插队,就地修改,但如果插队的位置除了队尾其余任何地方都会导致列表元素额挪动,若规模庞大,效率不高,不建议使用。时间复杂度为O(n)
insert超界:
超过上界限,尾部追加
超过下界,头部追加
插队一定是插在别人的前面

列表增加多个元素:
extend(iteratable):可迭代对象,就地修改。
+ ->list :连接操作,将两个列表连接起来,产生新的列表,原来的列表不变,调用了__add__()魔术方法
* ->list :重复操作,将本列表元素重复n次,返回新的列表
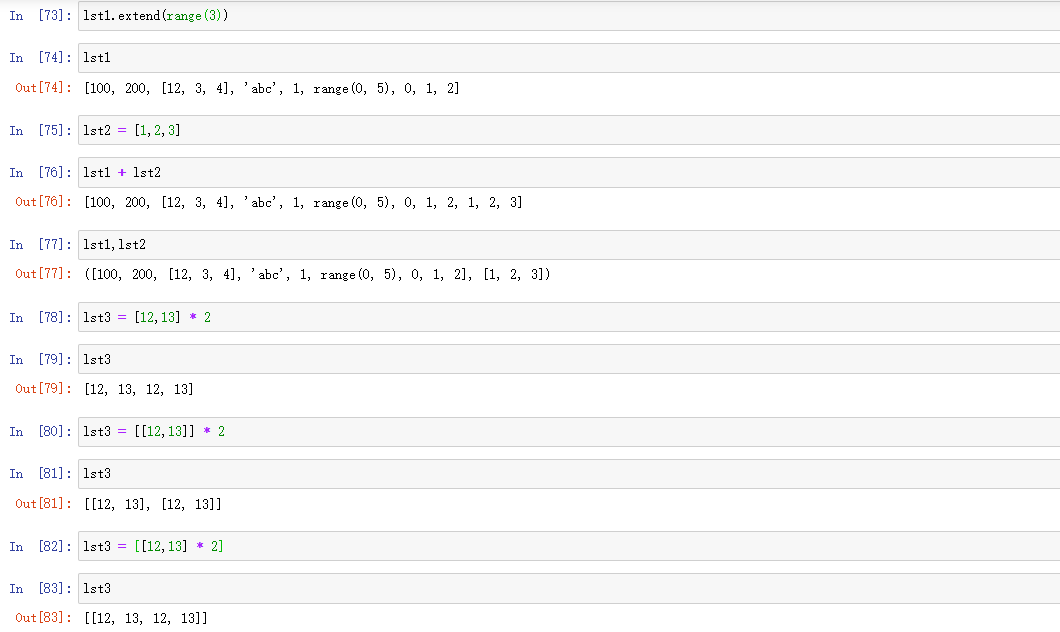
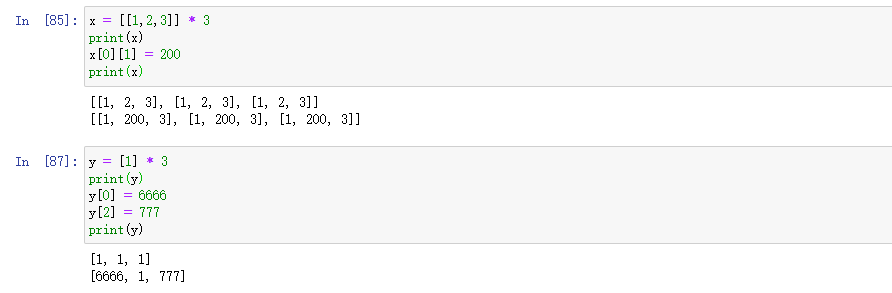
列表复制的坑:深浅复制问题
x = [[1,2,3]] * 3 print(x) x[0][1] = 200 print(x) print('----------------') y = [1] * 3 print(y) y[0] = 6666 y[2] = 777 print(y)
列表的删除元素:
remove(value):从左边往右查找第一个匹配的元素的值,找到就移除该元素,并且返回None,就地修改,效率不高。
pop():不指定索引就从尾部弹出一个元素,指定索引就从索引处弹出一个元素,索引不可超界,尾部弹出效率还可以,如果在中间,则效率不高。
clear():清除列表所有元素,剩余一个空列表,效率OK,但是慎用
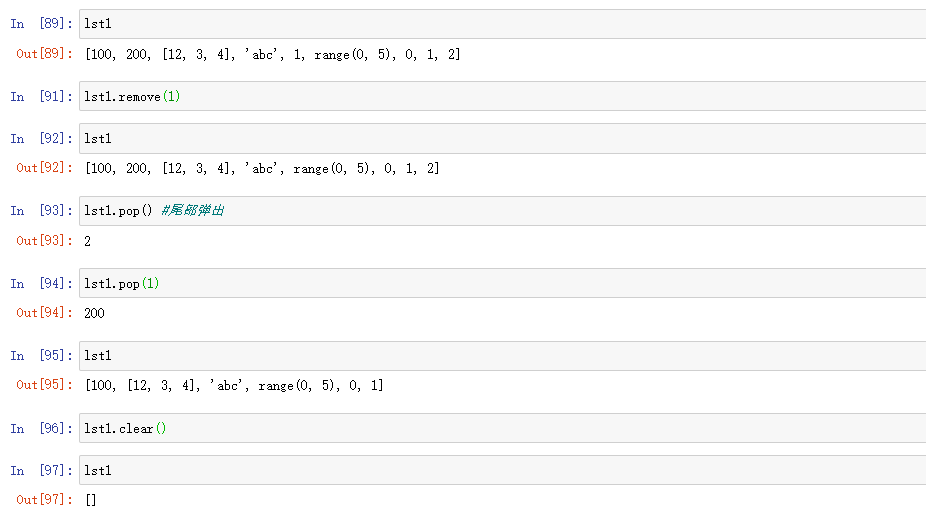
列表的其他操作:
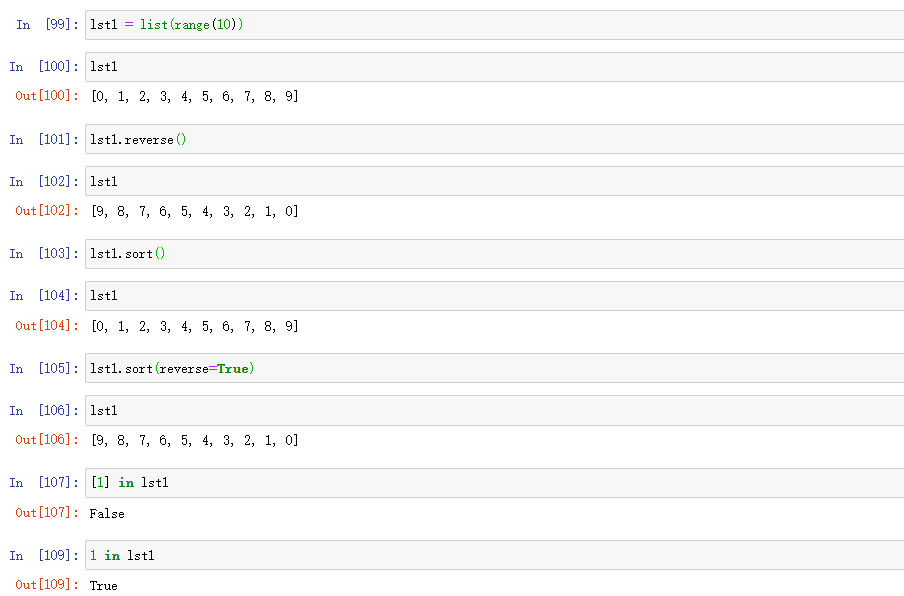
reverse():列表反转,返回None,就地修改
sort():对列表进行排序,就地修改,默认为升序,lst1.sort(reverse = True) 则为降序
in :判断列表是否在列表中
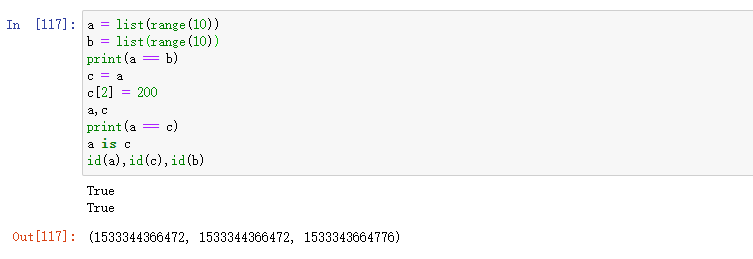
a = list(range(10))
b = list(range(10))
print(a == b)
c = a
c[2] = 200
print(a, c)
print(a == c)
print(a is c)
print(id(a), id(c), id(b))

列表复制:
shadow copy返回一个新的列表,如列表里面嵌套列表,copy一个新列表后内存地址未发生改变,修改则会将两列表值修改。
a = list(range(10)) b = a.copy() print(a == b) b[2] = 200 print(a == b) a,b


deepcopy(),深拷贝:
import copy a = [1,2,[12,13,14],4,5] b = copy.deepcopy(a) b[2][2] = 1400 print(a,b) print(a == b)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号