阿里云ECS部署hadoop+MapReduce+Spark实践
host说明
Namenode:主机结点
Datanode1:数据节点1
Datanode2:数据节点2
私网ip(在阿里云查看)
172.xx.xxx.xx Namenode
172.xx.xx.xx Datanode1
172.xx.xxx.xxx Datanode2
阿里云操作
建立VPC对等连接(收费)
专有网络 VPC 控制台
需要一端发起一端接受
一端发起建立连接请求
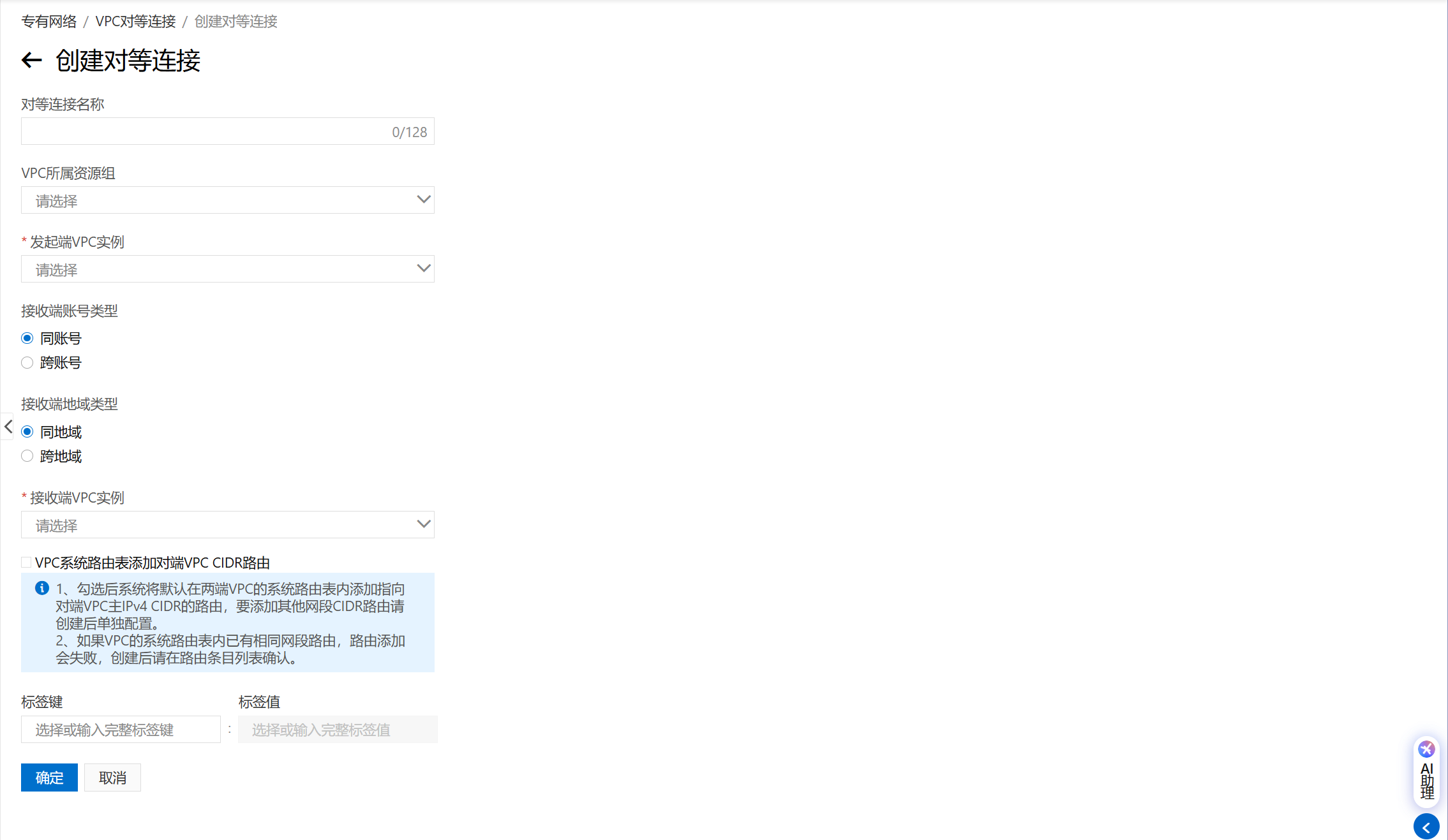
配置路由表
专有网络 VPC 控制台
注意不要添加路由表实例,而是进入唯一的实例添加条目
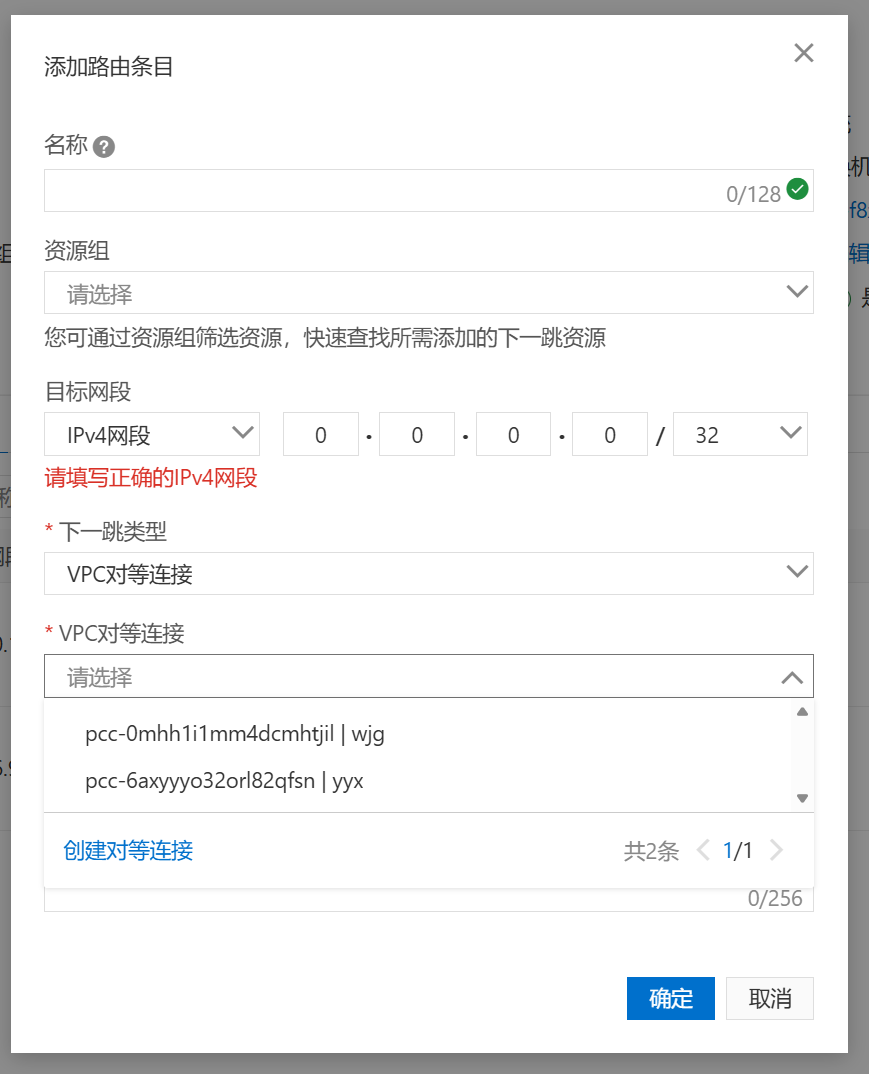
目标网段填写对方的ip,下一跳选择刚刚创建的对等连接
配置安全组
一台ECS可以使用多个安全组,这里专门创建一个用于实验的安全组:
云服务器管理控制台
在安全组中新建规则允许结点之间使用所有TCP和端口:
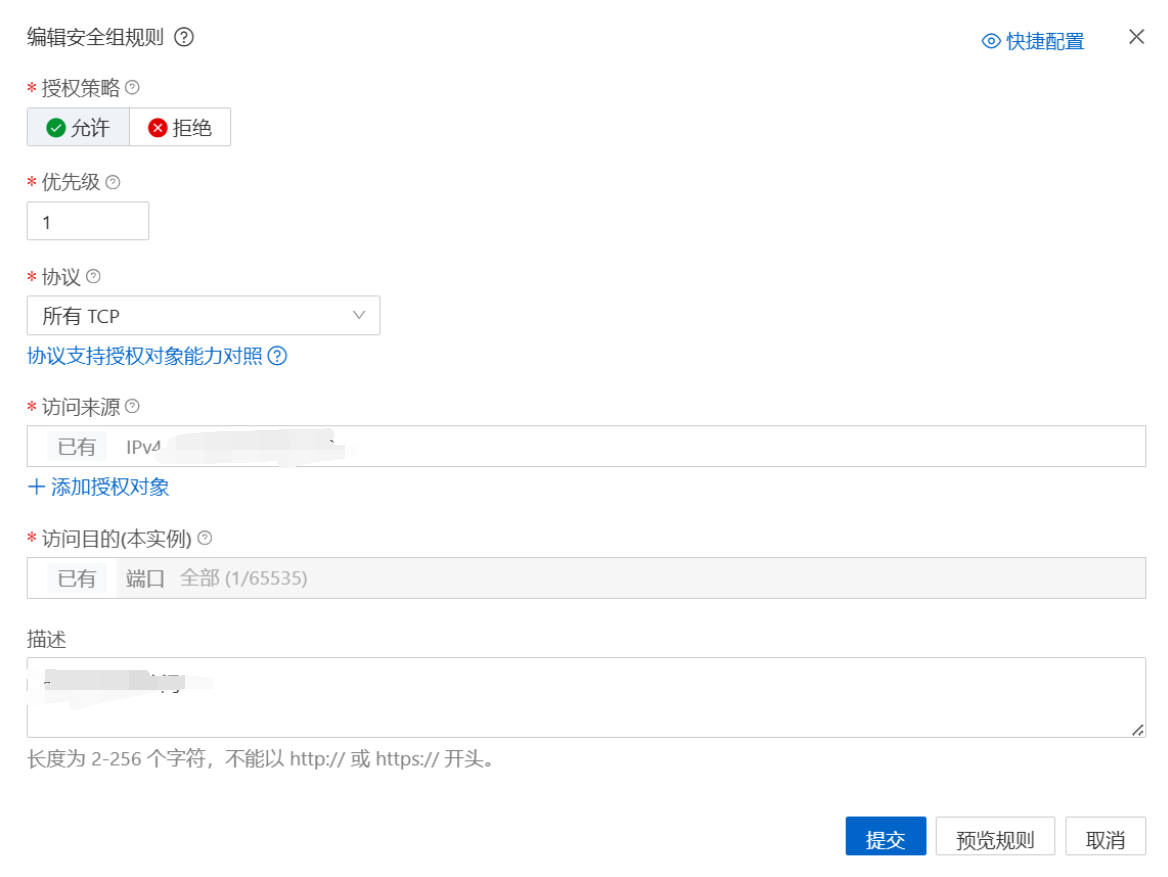
至此阿里云环境配置完成
服务器操作
权限管理
创建低权限用户(所有结点)
在所有实例上创建地权限账号
# 创建一个名为 hadoop 的用户
useradd -m hadoop
# 设置密码(可选,但推荐)
passwd hadoop
# 切换到 hadoop 用户
su - hadoop
创建连接密钥
ssh-keygen -t rsa
第一次登陆输入密码,之后免密(NameNode)
# 1. 复制公钥到新的 hadoop 账户
ssh-copy-id hadoop@Datanode1
# 2. 验证是否能免密登录
ssh hadoop@Datanode1
# 1. 复制公钥到新的 hadoop 账户
ssh-copy-id hadoop@Datanode2
# 2. 验证是否能免密登录
ssh hadoop@Datanode2
管理目录结构(NameNode)
sudo mkdir -p /home/hadoop/opt/hadoop
sudo mkdir -p /home/hadoop/opt/ant
sudo mkdir -p /home/hadoop/data/hdfs/namenode
sudo mkdir -p /home/hadoop/data/hdfs/datanode
sudo chown -R hadoop:hadoop /home/hadoop/opt /home/hadoop/data
或者直接使用Hadoop账号操作
mkdir -p /home/hadoop/opt/hadoop
mkdir -p /home/hadoop/opt/ant
mkdir -p /home/hadoop/data/hdfs/namenode
mkdir -p /home/hadoop/data/hdfs/datanode
修改网络解析(NameNode)
由于实验报告是随意的不考虑安全的,甚至全部要求使用root操作,实际生产环境不推荐直接在云服务器的直接修改
/etc/hostname,所以这里代替使用/etc/hosts
# vi /etc/hosts (在所有节点上执行)
# ... (保留原有的 localhost 和系统配置)
# Hadoop 集群角色定义 (仅用于本次实验的解析)
# -----------------------------------------------
xxx.xx.xxx.xxx Namenode
xxx.xx.xxx.xxx Datanode1
xxx.xx.xxx.xxx Datanode2
安装环境(NameNode)
以下指令全部使用hadoop用户执行
安装hadoop
# 进入操作目录
cd ~/opt
# 从镜像安装hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 解压到/opt/hadoop目录下
tar -zxvf hadoop-3.3.6.tar.gz -C ~/opt/hadoop --strip-components=1
安装太慢可以使用镜像
# 进入操作目录
cd ~/opt
# 使用阿里云镜像下载 Hadoop 3.3.6 压缩包
# 這是您現代化流程中選擇的最新版本
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 把压缩包安装到 /opt/hadoop 目录中
tar -zxvf hadoop-3.3.6.tar.gz -C ~/opt/hadoop --strip-components=1
安装jdk
直接使用最现代的安装方式(如果没有java)
# 1. 確保系統軟體包清單是最新的
sudo apt update
# DN:sudo yum update -y
# 2. 安裝 OpenJDK 17 JDK
sudo apt install openjdk-8-jdk -y
# DN:sudo yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
三台主机的java位置
NN:/usr/lib/jvm/java-8-openjdk-amd64
DN1:/home/hadoop/java8/dragonwell-8.20.21
DN2:/usr/lib/jvm/java-1.8.0-openjdk
安装ant
# 进入操作目录
cd ~/opt
# 尝试下载 Ant 1.10.14
wget https://mirrors.aliyun.com/apache/ant/binaries/apache-ant-1.10.14-bin.tar.gz -O ant.tar.gz
# 解压
tar -zxvf ant.tar.gz -C ~/opt/ant --strip-components=1
# 清理下载文件
rm ant.tar.gz
配置终端属性 (NameNode)
不再使用 ~/.bash_profile 这种古老做法,改用:
~/.bashrc + /etc/profile.d
编辑终端环境
vim ~/.bashrc
加入:
########## Hadoop环境变量 ##########
export HADOOP_HOME=/home/hadoop/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 添加 Hadoop CLASSPATH 配置用于编译java
# 设置 Hadoop CLASSPATH 变量
# 递归查找所有必要的 Jar 包 (.jar) 并用冒号 ":" 连接起来
HADOOP_CLASSPATH=$(find $HADOOP_HOME/share/hadoop/common -name '*.jar' | tr '\n' ':')
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$(find $HADOOP_HOME/share/hadoop/hdfs -name '*.jar' | tr '\n' ':')
# 导出 CLASSPATH 变量,以便 javac 和 java 命令可以直接使用
export CLASSPATH=.:$HADOOP_CLASSPATH
# 注意:CLASSPATH 前的 '.' 代表当前目录,确保您的类文件可以被找到。
# 本地库
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
# 添加hadoop的bin&sbin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
########## 启动hadoop快捷键 ##########
alias hstart='start-dfs.sh && start-yarn.sh'
alias hstop='stop-yarn.sh && stop-dfs.sh'
########## Java/JDK环境变量 ##########
# 动态查找并设置 JAVA_HOME,使用系统已安装的兼容版本
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
立即生效:
source ~/.bashrc
配置Hadoop配置文件(NameNode)
如下文件全部在$HADOOP_CONF_DIR
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hdfs/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/data/hdfs/datanode</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/opt/hadoop</value>
</property>
</configuration>
workers
# 仅在NameNode修改文件
vim $HADOOP_HOME/workers
# 添加数据节点
Datanode1
Datanode2
hadoop-env.sh
hadoop3的环境配置不依赖用户的环境变量,而是hadoop-env.sh脚本
# 在 NameNode 上执行
vi $HADOOP_CONF_DIR/hadoop-env.sh
# 找到文件中 JAVA_HOME 所在行,并修正/新增以下内容:
# export JAVA_HOME=/home/hadoop/opt/jdk/
# 动态查找并设置 JAVA_HOME。如果 which java 成功,则动态设置
if type -p java > /dev/null; then
# 通过 which java -> readlink -f -> dirname/dirname 获取绝对根目录
JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))
else
# 动态查找失败时的 NameNode 本地兼容路径,作为回退
# 确保这里的路径是 NameNode 上实际工作的 Java 17 路径
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
fi
export JAVA_HOME
# ------------------------------
配置好后的软件发送给DataNode
scp ~/.bashrc Datanode1:~
scp ~/.bashrc Datanode2:~
scp -r ~/opt/hadoop datanode1:~/opt
scp -r ~/opt/hadoop datanode2:~/opt
启动 Hadoop(NameNode)
# 1. 格式化 NameNode (第一次启动的时候才运行)
hdfs namenode -format
# 2. 使用配置好的快捷指令
hstart
验证集群状态
# 3. 檢查 NameNode 上的進程
jps
# 预期结果: NameNode, ResourceManager, SecondaryNameNode, Jps
# 4. 檢查 DataNode 上的進程
ssh Datanode1 /home/hadoop/opt/jdk/bin/jps
ssh Datanode2 /home/hadoop/opt/jdk/bin/jps
# 预期结果: DataNode, NodeManager, Jps
# 5. 檢查 HDFS 健康報告 (核心驗證)
hdfs dfsadmin -report
運行 HDFS 測試
# 1. 创建测试文件
echo "wjg~" > aaa.txt
# 2. 查看 HDFS 根目录
hadoop fs -ls /
# 3. 上传测试文件
hadoop fs -put aaa.txt /aaa.txt
# 4. 验证文件是否存在
hadoop fs -ls /
终止
# 完成實驗後停止集群
hstop
实验指导书步骤
cd $HADOOP_HOME
cd etc/hadoop
hdfs namenode -format
start-all.sh
hdfs dfsadmin -report
jps
hadoop fs -ls /
hadoop fs -put aaa.txt /aaa.txt
在VScode开始编码
为了在VScode编写java需要先对VScode做一些配置:
安装依赖
配置工作区
由于本次实验的java代码使用到了hadoop的jar包依赖,直接在VScode中编码会有大量冒红,所以需要先在
/.vscode/settings.json中配置路径。
同时为了让VScode的开发更接近IDEA,可以配置包的目录在src/main/java下。
{
// 配置 Java 项目的模块路径
"java.project.sourcePaths": [
"src/main/java" // 假设您的源代码在 src 目录下,如果直接在根目录则留空或使用 "."
],
// 配置 Java 依赖(将您的Hadoop路径替换到下面)
"java.project.referencedLibraries": [
// 核心Hadoop common 库
"/home/hadoop/opt/hadoop/share/hadoop/common/*.jar",
"/home/hadoop/opt/hadoop/share/hadoop/common/lib/*.jar",
// HDFS 库
"/home/hadoop/opt/hadoop/share/hadoop/hdfs/*.jar",
"/home/hadoop/opt/hadoop/share/hadoop/hdfs/lib/*.jar",
// MapReduce 库 (实验三需要)
"/home/hadoop/opt/hadoop/share/hadoop/mapreduce/*.jar",
"/home/hadoop/opt/hadoop/share/hadoop/mapreduce/lib/*.jar",
// YARN 库 (可选, 但推荐)
"/home/hadoop/opt/hadoop/share/hadoop/yarn/*.jar",
"/home/hadoop/opt/hadoop/share/hadoop/yarn/lib/*.jar"
],
"java.compile.nullAnalysis.mode": "automatic"
}
最终的项目结构为:
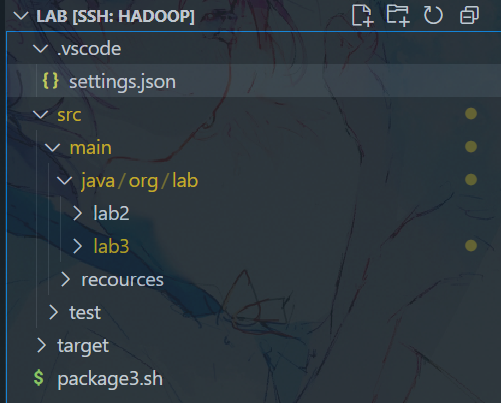
java简单调用hadoop api
在org.lab.lab2包中编写实验二的代码:
HDFSFileReader
package org.lab.lab2;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSFileReader {
public static void main(String[] args) {
// !!! 确保这里的 UzRI 与您的 NameNode 地址一致 !!!
String uri = "hdfs://Namenode:9000/lab2/lab2.txt";
Configuration conf = new Configuration();
FileSystem fs = null;
InputStream in = null;
try {
// 1. 获取 FileSystem 实例
fs = FileSystem.get(URI.create(uri), conf);
// 2. 打开 HDFS 文件
in = fs.open(new Path(uri));
// 3. 将内容复制到标准输出 (System.out)
IOUtils.copyBytes(in, System.out, 4096, false);
System.out.println();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 关闭流和文件系统资源
IOUtils.closeStream(in);
IOUtils.closeStream(fs);
}
}
}
HDFSFileWriter
package org.lab.lab2;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileWriter {
public static void main(String[] args) {
// 目标写入路径:例如 /lab/output.txt
String uri = "hdfs://Namenode:9000/lab2/lab2.txt";
Configuration conf = new Configuration();
FileSystem fs = null;
FSDataOutputStream out = null;
// 要写入 HDFS 的内容
String content = "ciallo~";
try {
// 1. 获取 FileSystem 实例
fs = FileSystem.get(URI.create(uri), conf);
// 2. 创建文件并获取输出流 (false 表示如果文件已存在则抛出异常)
// true 表示允许覆盖,这里为了安全,建议使用 fs.create(new Path(uri));
out = fs.create(new Path(uri));
// 3. 写入内容
out.write(content.getBytes("UTF-8"));
System.out.println("成功创建并写入 HDFS: " + uri);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 关闭输出流和文件系统资源
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
直接在VScode中运行java代码就可以出现结果。
使用MapReduce分析数据
注意,实验报告中使用了
Job job = new Job(conf, "word count");,这在高版本中是废弃的API,这里修改使用类工厂创建Jod类
// 新的、推荐的静态工厂方法Job job = Job.getInstance(conf, "word count");`
使用wget获取数据
# 假设您当前位于项目根目录 ~/lab
cd ~/lab
# 1. 创建本地数据存放目录
mkdir -p data
# 2. 使用 wget 命令下载 LiveJournal.txt 文件到 data 目录
wget -P data http://denglab.org/cloudcomputing/download/LiveJournal.txt
# 3. 检查文件是否下载成功
ls -l data/LiveJournal.txt
把下载的数据放到hadoop上
# 1. 创建 HDFS 输入目录 (如果尚未创建)
hdfs dfs -mkdir -p /exp3/friends/input
# 2. 将本地文件上传到 HDFS 目录
# HDFS 输入目录通常是一个目录,而不是具体文件名
hdfs dfs -put data/LiveJournal.txt /exp3/friends/input/
打包并提交
把实验报告中的两个代码创建到org.lab.lab3中后,使用如下脚本打包项目:
#!/bin/bash
# ----------------------------------------------------------------------
# MapReduce 实验三 打包脚本 (package3.sh)
# 作用:编译 WordCount.java 和 deg2friendTwice.java,并生成可提交的 JAR 包。
# ----------------------------------------------------------------------
# 1. 定义环境变量 (确保路径正确)
HADOOP_HOME="/home/hadoop/opt/hadoop"
# 构造完整的 Classpath
HADOOP_CLASSPATH="$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:\
$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:\
$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:\
$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/yarn/lib/*:."
# 定义项目目录和输出目录
LAB_HOME="/home/hadoop/lab"
CLASSES_DIR="$LAB_HOME/target/classes"
JAR_FILE="$LAB_HOME/target/exp3.jar"
# 源代码路径 (WordCount 和 deg2friendTwice 都在 lab3 目录下)
WC_SOURCE="$LAB_HOME/src/main/java/org/lab/lab3/WordCount.java"
FRIEND_SOURCE="$LAB_HOME/src/main/java/org/lab/lab3/deg2friendTwice.java"
echo "--- 1. 清理旧的编译和打包文件 ---"
rm -rf "$CLASSES_DIR"
rm -f "$JAR_FILE"
mkdir -p "$CLASSES_DIR"
echo "--- 2. 编译 MapReduce 源文件 ---"
# 使用构造的 Classpath 编译两个文件,输出到 CLASSES_DIR
javac -classpath "$HADOOP_CLASSPATH" "$WC_SOURCE" "$FRIEND_SOURCE" -d "$CLASSES_DIR"
if [ $? -ne 0 ]; then
echo "❌ 编译失败,请检查 Java 代码和依赖!"
exit 1
fi
echo "✅ 编译成功!"
echo "--- 3. 创建可运行的 JAR 包 ---"
# 进入编译目录,打包 org/ 目录下的所有内容
cd "$CLASSES_DIR"
jar -cvf "$JAR_FILE" org/
if [ $? -ne 0 ]; then
echo "❌ JAR 打包失败!"
exit 1
fi
# 返回项目根目录
cd "$LAB_HOME"
echo "--- 4. 打包完成报告 ---"
echo "✅ 实验三 JAR 包创建成功,文件位置: $JAR_FILE"
echo "接下来你可以提交 WordCount 和 deg2friendTwice 作业。"
# ----------------------------------------------------------------------
运行打包后的jar包,输出结果如下
hadoop@ip-172-25-215-57:~/lab$ jar -tf target/exp3.jar
META-INF/
META-INF/MANIFEST.MF
org/
org/lab/
org/lab/lab3/
org/lab/lab3/WordCount$IntSumReducer.class
org/lab/lab3/WordCount$TokenizerMapper.class
org/lab/lab3/WordCount.class
org/lab/lab3/deg2friendTwice$job1Mapper.class
org/lab/lab3/deg2friendTwice$job1Reducer.class
org/lab/lab3/deg2friendTwice$job2Mapper.class
org/lab/lab3/deg2friendTwice$job2Reducer$1.class
org/lab/lab3/deg2friendTwice$job2Reducer$2.class
org/lab/lab3/deg2friendTwice$job2Reducer.class
org/lab/lab3/deg2friendTwice.class
提交链式作业
# 1. 确保最终输出目录不存在 (必须操作)
hdfs dfs -rm -r /exp3/friends/final_output
# 2. 提交 MapReduce 链式作业
yarn jar target/exp3.jar org.lab.lab3.deg2friendTwice /exp3/friends/input /exp3/friends/final_output
最终运行结果:
hadoop@ip-172-25-215-57:~/lab$ hdfs dfs -ls /exp3/friends/final_output
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2025-12-14 15:23 /exp3/friends/final_output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 3107471 2025-12-14 15:23 /exp3/friends/final_output/part-r-00000
hadoop@ip-172-25-215-57:~/lab$ hdfs dfs -cat /exp3/friends/final_output/part-r-00000 | head
0 10001,1001,10014,10018,10020,10023,10025,10038,10041,10042
1 10,1001,10035,10099,1012,1020,10208,10253,10292,10301
10 1,10041,1080,1085,11377,11381,11387,11401,11419,120
100 101,102,103,104,105,106,10613,107,108,109
1000 1001,1002,1003,1004,1005,1006,1007,1008,1009,1010
10000 10003,10005,10007,10011,10013,10020,10023,10027,10031,10034
10001 0,10003,10005,10006,10007,10010,10011,10015,10017,10019
10002 10003,10005,10010,10011,10017,10023,10024,10027,10031,10036
10003 10000,10001,10002,10004,10005,10006,10007,10008,10009,1001
10004 10003,10005,10006,10007,10011,10015,10017,10019,10020,10021
cat: Unable to write to output stream.
Spark 3.x on YARN
注意spark需要在所有结点上安装
可以使用scp传输,或者分别安装
安装Spark
# 进入安装目录
cd ~/opt
# 下载安装包
wget https://archive.apache.org/dist/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
# 解压
tar -zxvf spark-3.5.1-bin-hadoop3.tgz
# 移动到目标文件夹
mv spark-3.5.1-bin-hadoop3 spark
安装太慢可以使用镜像
# 1. 切换到目标安装目录
cd ~/opt
# 2. 从阿里云镜像下载 Spark 3.5.1 (预编译支持 Hadoop 3.3)
# 注意:阿里云镜像通常位于 mirrors.aliyun.com/apache/
wget https://mirrors.aliyun.com/apache/spark/spark-3.5.7/spark-3.5.7-bin-hadoop3.tgz
# 3. 解压
tar -zxvf spark-3.5.7-bin-hadoop3.tgz
# 4. 移动到目标文件夹
mv spark-3.5.7-bin-hadoop3 spark
配置文件
本次实验采用的 Spark on YARN 模式
因此无需像实验报告一样设置太多配置文件,只需要spark-defaults.conf定义了spark.master=yarn和 Executor 的资源参数,告诉 Spark 如何向 YARN 请求资源
在~/.bashrc中配置环境变量
########## spark环境变量 ##########
# Spark 路径
export SPARK_HOME=~/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
创建配置文件
spark-env.sh
cd ~/opt/spark/conf/
# 确认文件已存在,如果不存在请创建
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加如下配置
# 请替换为您系统中 Java 8 的实际安装路径!
# 示例:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 指向 Hadoop 配置目录(冗余设置,但推荐保留)
export HADOOP_CONF_DIR=~/opt/hadoop/etc/hadoop
spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
添加如下配置
spark.master yarn
spark.submit.deployMode client
spark.driver.memory 1g
spark.executor.memory 2g
spark.executor.cores 1
运行
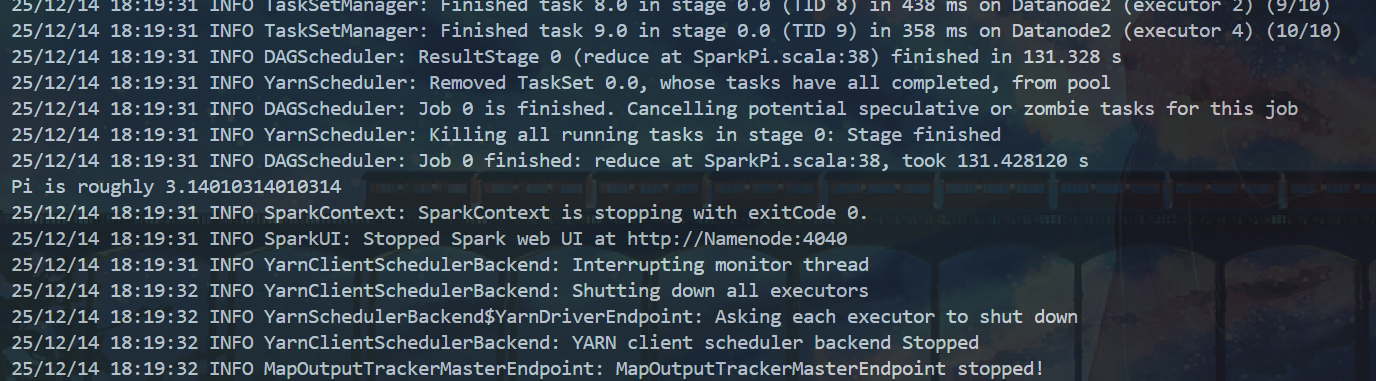
运行 SparkPi 示例到 YARN 集群:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
$SPARK_HOME/examples/jars/spark-examples_*.jar \
10
计算出pi的近似值说明环境配置成功:
scala编程
由于本次实验安装了 Spark 3.5.7,它内置了运行所需的 Scala 库,所以无需和实验报告一样单独安装 Scala 运行时环境。直接进入 编程实现 阶段。
为了完成本次实验现在hadoop上创建必要的文件夹
# 任务一
hdfs dfs -mkdir -p /user/hadoop/wordcount_input/
#任务二
hdfs dfs -mkdir -p /user/hadoop/pagerank_input/
任务一:WordCount 程序实现 (Scala in spark-shell)
目标: 读取 HDFS 文件,计算其中每个单词的出现次数。
准备测试文件
# 1. 在本地创建一个测试文件
echo "spark is fast and spark is scalable" > local_test.txt
echo "hadoop is big data framework" >> local_test.txt
# 2. 将文件上传到 HDFS
hdfs dfs -put local_test.txt /user/hadoop/wordcount_input/
编写scala代码:
// 步骤 1: 读取 HDFS 文件
val lines = sc.textFile("hdfs://namenode:9000/user/hadoop/wordcount_input/local_test.txt")
// 步骤 2: 完整的 WordCount 核心逻辑(注意链式调用)
val wordCounts = lines.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
// 步骤 3: 打印结果(用于调试)
println("--- Word Count Results ---")
wordCounts.collect().foreach(println)
// 预期输出应该是 (spark, 2), (is, 3), (hadoop, 1) 等
// 步骤 4: 将结果保存到 HDFS
// 注意:如果上一个 '/user/hadoop/wordcount_output' 目录已创建,您需要先删除它
// 在 spark-shell 外执行: hdfs dfs -rm -r /user/hadoop/wordcount_output
wordCounts.saveAsTextFile("hdfs://namenode:9000/user/hadoop/wordcount_output_final")
在NN结点上启动spark:
spark-shell --master yarn --deploy-mode client
加载scala文件
:load /home/hadoop/lab/bash/lab4/task1.scala
任务二:PageRank 程序实现 (Scala in spark-shell)
目标: 实现 PageRank 的迭代计算公式。
1. 准备 PageRank 输入数据格式
PageRank 的输入数据格式通常是 (PageID, ListOfOutLinks)。
所以我们先准备task2文件:
A B D
B A C E
C B
D A
E B
A 链接到 B 和 D;B 链接到 A, C, E,以此类推。
然后再把文件直接上传到hadoop文件系统上
hdfs dfs -put /home/hadoop/lab/bash/lab4/task2.txt /user/hadoop/pagerank_input/
2. 运行 PageRank 代码
在 Master 节点启动 spark-shell:
spark-shell --master yarn --deploy-mode client
编写代码task2.scala
// 步骤 1: 设置迭代次数和阻尼系数
val ITERATIONS = 10
val DAMPING_FACTOR = 0.85
val N = 5
val initialRank = 1.0 / N
// 步骤 2: 修正后的加载逻辑(确保点号在行尾或表达式连贯)
val links = sc.textFile("hdfs://namenode:9000/user/hadoop/pagerank_input/task2.txt").map(s => {
val parts = s.split(" ")
(parts(0), parts.drop(1))
}).persist()
// 步骤 3: 初始化 PageRank
// 现在 links 是 RDD[(String, Array[String])],可以使用 mapValues 了
var ranks = links.mapValues(v => initialRank)
println("--- Starting PageRank Iterations ---")
// 步骤 4: 迭代计算
for (i <- 1 to ITERATIONS) {
// 显式指定类型确保编译器识别 outLinks 为 Array[String]
val contribs = links.join(ranks).flatMap { case (url, (outLinks: Array[String], rank: Double)) =>
val size = outLinks.size
outLinks.map(dest => (dest, rank / size))
}
ranks = contribs.reduceByKey(_ + _).apValues(sum => (1.0 - DAMPING_FACTOR) + DAMPING_FACTOR * sum)
}
// 步骤 5: 将最终结果保存到 HDFS
// 注意:运行前请确保 HDFS 上的 pagerank_output 目录不存在
// hdfs dfs -rm -r /user/hadoop/pagerank_output
ranks.saveAsTextFile("hdfs://namenode:9000/user/hadoop/pagerank_output")
println("--- PageRank Calculation Finished. Results saved to HDFS. ---")
与任务一同理加载代码文件
:load /home/hadoop/lab/bash/lab4/task2.scala
完成后,退出 shell: :quit
至此,分布式云计算实验完成 ( O V O ) !
外传:综合实例计算每种图书平均销量
编写代码
val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
rdd.mapValues(x => (x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
终端执行:
:load /home/hadoop/lab/bash/lab4/extra.scala

 浙公网安备 33010602011771号
浙公网安备 33010602011771号