金融监管报表口径自动化盘点:从 30 人天到 1.5 天的技术实践
本文首发于 Aloudata 官方技术博客:《1104 报表口径梳理:从 30 人天到 1.5 天的自动化实践》https://ai.noetl.cn/knowledge-base/1104-report-caliber-automation-practice转载请注明出处。
摘要:本文深入探讨了金融监管报表(如1104报表)口径梳理的自动化实践。针对传统人工方式耗时数月、文档易过时的痛点,介绍了基于算子级血缘和行级裁剪技术的解决方案。通过主动元数据平台实现口径的自动化盘点、一键溯源与持续保鲜,可将盘点效率提升20倍,并支撑更广泛的数据治理与DataOps场景。
对于银行数据团队而言,1104、EAST等监管报表的口径梳理是典型的“效率黑洞”。传统人工扒代码的方式,一个复杂指标动辄耗费30人天,且文档与代码极易脱节。本文将解析如何通过算子级血缘技术,实现监管指标口径的自动化盘点与一键溯源,将效率提升20倍。
一、监管口径梳理的三大核心痛点
监管指标口径梳理的复杂性主要源于三个层面:
- 政策频繁变动:以2025/2026年1104制度升级为例,围绕“五篇大文章”等主题新增大量报表,数据团队需追溯新旧口径差异,工作量指数级增长。
- SQL逻辑深藏:加工逻辑常封装在数百行、多级嵌套的SQL或存储过程中。例如,“正常类贷款余额”的核心逻辑 WHERE 贷款状态 = ‘正常’ 深藏代码深处,必须人工逐行解读。
- 传统工具能力不足:市面报表自动化工具侧重于数据映射与生成,但对最底层的 “口径白盒化梳理”——即自动回答“指标由哪部分数据、经何条件计算得出”——无能为力,仍需大量人工介入。
真实成本:一个复杂指标从定位、理解到形成文档,常需数周甚至数月(约30人天)。成本高昂且易出错,一旦代码变更,手工文档立即失效,陷入“运动式治理”循环。
二、技术破局:为何传统血缘工具“看不清”过滤条件?
自动化口径梳理的核心挑战,在于精准解析 “指标具体由哪部分数据(符合什么条件)计算得出”。这要求工具必须能理解SQL中的WHERE、JOIN ON等过滤条件,而这正是传统血缘工具的“代际盲区”。
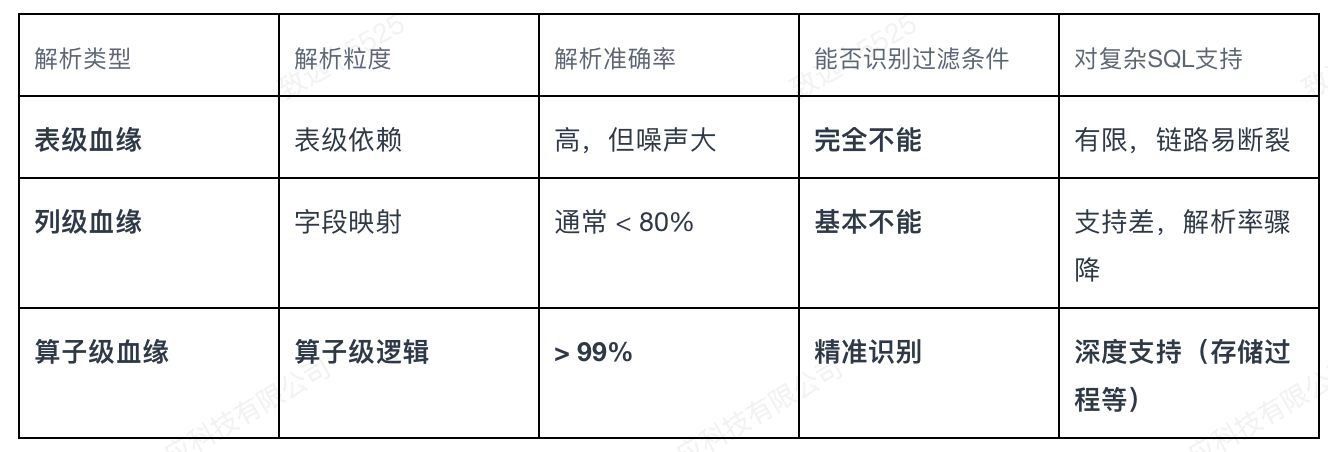
代际差距的本质:
● 表级血缘:仅能回答“数据来自A表、B表”,无法知晓具体参与计算的数据部分,噪声巨大。
● 列级血缘:能追踪字段映射,但无法理解 WHERE 贷款状态=‘正常’ 等关键筛选逻辑,面对复杂SQL和存储过程束手无策。
● 算子级血缘:深入SQL执行的算子(Operator)层面,精准解析过滤(Filter)、连接(Join)、聚合(Aggregation)等具体操作。其伴生的 行级裁剪 能力,能自动剔除不满足条件的数据分支,是自动化、准确化提取口径的技术基石。
三、新模式:从“人工扒代码”到“一键溯源”
基于算子级血缘的主动元数据平台,可将监管口径管理从“事后人工补救”升级为“事中自动保鲜”。
- 自动化盘点流程平台连接各类数据源(如Hive, Spark, Oracle, DB2, GaussDB等)后,核心解析引擎主动扫描并深度解析所有数据加工任务(包括复杂的PL/SQL存储过程、动态SQL),自动构建覆盖全链路的 算子级血缘图谱,全程无需人工解读代码。
- 一键生成口径文档针对任意报表单元格,用户只需点击“溯源”。平台自动回溯完整加工路径,将多层嵌套的SQL逻辑“翻译”成清晰、可读的业务口径描述,并可直接导出为标准化文档。
- 核心能力支撑
● 行级裁剪:评估上游变更影响时,平台自动识别下游指标依赖的过滤条件,仅对真正受影响的数据范围(如特定分行)进行预警,减少不必要评估范围 80% 以上。
● 复杂逻辑全覆盖:深度适配DB2、Oracle等存储过程,解析准确率超 99%。
● 持续保鲜机制:持续监控代码与调度日志。当逻辑变更时,血缘图谱自动更新并通知责任人,确保口径文档与生产代码实时同步,告别静态文档。
四、标杆实践:银行如何实现20倍效率提升?
头部金融机构的实践已验证,基于算子级血缘的自动化口径管理能带来可量化回报。
1、浙江农商联合银行:监管指标溯源与DB2存储过程解析。监管指标盘点从 数月缩短至8小时,人效提升 20倍;DB2存储过程血缘解析准确率达 99%。
2、杭州银行:构建全链路算子血缘,实现监管报送指标自动化盘点与保鲜。基于精准血缘,问题根因分析效率提升 40%。
案例启示:基于算子级血缘的自动化口径管理,是实现监管“指标溯源、血缘分析、线上化管理”的核心技术基石。它不仅应对当前1104、EAST等报表盘点难题,也为未来“一表通”穿透式数据底座等监管新要求提供底层能力支撑。
五、实施建议:从试点到全行推广
金融机构可采用“由点及面、价值驱动”策略,稳步构建企业级主动元数据能力。
1、试点场景选择:从痛点集中、价值易显化的场景入手,如:
● 涉及“五篇大文章”的复杂1104专项报表。
● EAST报送中加工链路长、人工成本高的重点指标。
2、价值验证指标:明确衡量标准,快速验证:
● 效率提升:口径梳理耗时减少百分比(目标:70%-90%)。
● 准确性:自动化口径文档与代码逻辑一致性(目标:>99%)。
● 保鲜度:代码变更后,文档自动更新的时效性。
3、长期演进路径:
● 横向扩展:从1104扩展到EAST、客户风险、反洗钱等全体系监管报送。
● 纵向深化:从口径溯源,扩展到全链路变更影响分析、主动模型治理、DataOps协同,最终形成以主动元数据为核心的数据治理闭环。
常见问题 (FAQ)
Q1: 算子级血缘和列级血缘在1104报表场景下具体有什么区别?
算子级血缘能精准解析SQL中的WHERE过滤、JOIN条件等操作逻辑,自动回答“指标是基于哪部分数据(如‘贷款状态=正常’)计算的”,从而生成准确口径文档。列级血缘只能追踪字段映射关系,无法理解数据筛选逻辑,仍需大量人工解读代码。
Q2: 我们的1104报表加工逻辑大量使用DB2存储过程,能准确解析吗?
可以。该方案的核心优势之一就是对DB2、Oracle、GaussDB等数据库的存储过程(PL/SQL)进行了深度适配,解析准确率超过99%。无论是动态SQL、临时表还是多层嵌套逻辑,都能实现穿透解析。
Q3: 自动生成的口径文档,如何跟上监管政策变化和内部代码的频繁变更?
作为主动元数据平台,其血缘关系通过主动解析代码、日志等方式实时或准实时更新。当加工逻辑变更时,平台能自动重新解析并通知责任人。生成的口径文档是“活”的、与代码逻辑实时同步的视图,解决了传统静态文档“一发布即过时”的难题。
Q4: 除了1104报表,这套方案还能应用于其他监管报送场景吗?
完全可以。算子级血缘能力是通用的,目前已广泛应用于EAST报送、客户风险统计、人行大集中、反洗钱以及“一表通”穿透式数据底座建设等场景,实现“一份投入,多报送体系复用”。
核心要点
- 痛点本质:1104报表口径梳理的“效率黑洞”,根源在于传统工具无法穿透SQL中的行级筛选逻辑(过滤条件)。
- 技术代差:算子级血缘是突破该瓶颈的关键,其解析粒度(算子级)和准确率(>99%)远超表级、列级血缘,并能实现行级裁剪。
- 模式升级:基于主动元数据平台,实现了从“人工扒代码”到“一键溯源”的转变,并能确保口径文档随代码变更而持续保鲜。
- 已验证价值:标杆实践表明,该技术能将监管指标盘点效率提升 20倍(从数月到8小时),并支撑更广泛的DataOps与数据治理场景。
- 实施路径:建议从高价值监管报表试点入手,验证价值后,逐步构建企业级主动元数据能力中心。
本文详细技术原理、高清架构图及更多案例,请访问 Aloudata 官方技术博客原文:https://ai.noetl.cn/knowledge-base/1104-report-caliber-automation-practice

 浙公网安备 33010602011771号
浙公网安备 33010602011771号