NoETL 指标平台如何保障亿级明细查询的秒级响应?——Aloudata CAN 性能压测深度解析
本文首发于 Aloudata 官方技术博客:《指标平台性能压测:Aloudata CAN 如何保障亿级明细查询的秒级响应?》https://ai.noetl.cn/knowledge-base/aloudata-can-billion-level-detail-query-benchmark转载请注明出处。
摘要:本文针对数据工程中“宽表依赖症”导致的亿级数据查询性能瓶颈,通过对比传统静态宽表模式与 Aloudata CAN NoETL 指标平台的动态语义编织架构,从查询性能、并发能力、智能物化与运维成本三个维度,提供了一份基于压测数据的性能校验与选型指南,旨在帮助数据架构师在指标平台选型时做出客观决策。
面对亿级数据查询,传统的“数仓+宽表+BI”模式在灵活性与性能之间难以兼顾,常陷入“宽表依赖症”的困境。本文将从数据工程实践出发,深度解析 Aloudata CAN NoETL 指标平台的压测表现,通过对比查询性能、并发能力、智能物化与落地保障,为指标平台的性能校验与选型提供一份基于真实数据的决策指南。
一、性能校验的决策背景:告别“宽表依赖症”的性能陷阱
数据团队对以下场景绝不陌生:业务方在BI工具中拖入一个新的维度组合,查询响应时间从秒级骤降至分钟级,甚至触发超时。其根源在于,传统的“数仓+宽表+BI”模式在面对灵活多变的业务查询需求时,存在结构性瓶颈:
- 维度爆炸:为满足不同维度的组合查询,需要预先构建大量物理宽表,导致存储冗余和ETL链路复杂。
- 响应迟滞:查询性能严重依赖预建宽表的粒度和索引。一旦查询条件偏离预设路径,就需要对海量明细数据进行实时关联与聚合,性能急剧下降。
- 资源浪费:大量低频或无用的宽表持续消耗存储与计算资源,推高总体拥有成本(TCO)。
这种对物理宽表的深度依赖,使得企业在追求分析灵活性与保障查询性能之间陷入两难,性能校验因此成为选型自动化指标平台的核心决策点。
二、核心差异:从静态宽表计算到动态语义编织的架构革新
性能表现的根本差异,源于底层架构的范式革新。
传统模式(静态宽表计算):其核心是 “预计算、后查询” 。数据分析师或开发人员需要预先理解业务需求,编写SQL或ETL任务,将多张表打平成物理宽表或汇总表。查询时,BI工具直接访问这些固化好的物理表。其性能上限在宽表创建时即被锁定,且无法应对未预见的查询模式。
Aloudata CAN NoETL 模式(动态语义编织):其核心是 “声明定义、动态计算” 。基于语义编织技术,用户在界面通过 声明式策略 完成两件事:
● 声明逻辑关联:在未打宽的DWD明细表之间,声明业务实体间的关联关系(如 订单表 JOIN 用户表)。
● 声明指标逻辑:通过配置“基础度量、业务限定、统计周期、衍生计算”四大语义要素来定义指标(如 近7天支付金额大于100元的去重用户数)。
系统据此在逻辑层构建一个 虚拟业务事实网络(或称虚拟明细大宽表)。当业务发起查询时,语义引擎 将查询意图翻译为最优化的SQL,并通过 智能物化引擎 透明路由至已预热的物化结果或高效执行原生查询。这是一种 “逻辑定义与物理执行解耦” 的架构。
三、维度对比一:查询性能与响应时间
在亿级明细数据的典型场景下,我们对比单次复杂查询的响应时间与稳定性。以下是基于内部压测及客户实践的综合对比:
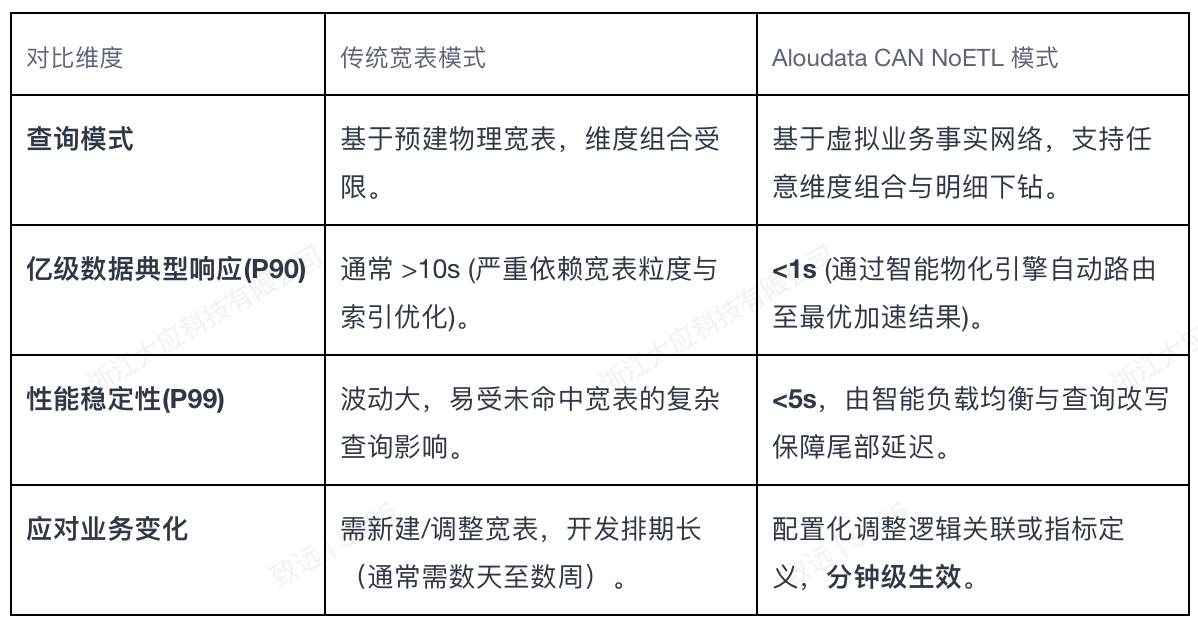
核心差异解读:传统模式的性能是“开盲盒”,取决于历史预判是否准确;而NoETL模式的性能通过 声明式物化策略 变得可预测、可保障。系统根据用户声明的加速需求(如“为‘销售额’指标在‘产品’、‘地区’维度上创建汇总加速”),自动编排物化任务并维护,查询时实现透明加速。
四、维度对比二:并发处理与资源效率
高性能不仅体现在单次查询,更在于高并发场景下的系统吞吐量与资源利用率。
传统模式瓶颈:高并发查询容易集中冲击少数热点宽表,造成资源争抢,响应时间线性增长。同时,为应对可能的查询而预先建设的众多宽表,在非查询时段也占用大量存储与内存资源,利用率低下。
Aloudata CAN 的实证:某头部股份制银行引入Aloudata CAN后,实现了总分行指标的统一管理与服务。在日均支撑 百万级 API调用的高并发场景下,系统整体查询性能 <3s 的占比达到 95%。这得益于其架构的弹性:
● 智能路由:将并发查询分散到不同的物化层(明细、汇总、结果),避免单点过热。
● 资源复用:相同的计算逻辑和粒度,系统会自动复用已有的物化表,避免重复计算与存储。
● 查询优化:即使未命中物化表,语义引擎生成的优化SQL也能最大程度利用底层数据引擎的能力。
五、维度对比三:落地保障与运维复杂度
可持续的性能离不开系统的落地保障能力,这直接关系到运维团队的投入与系统的总成本。
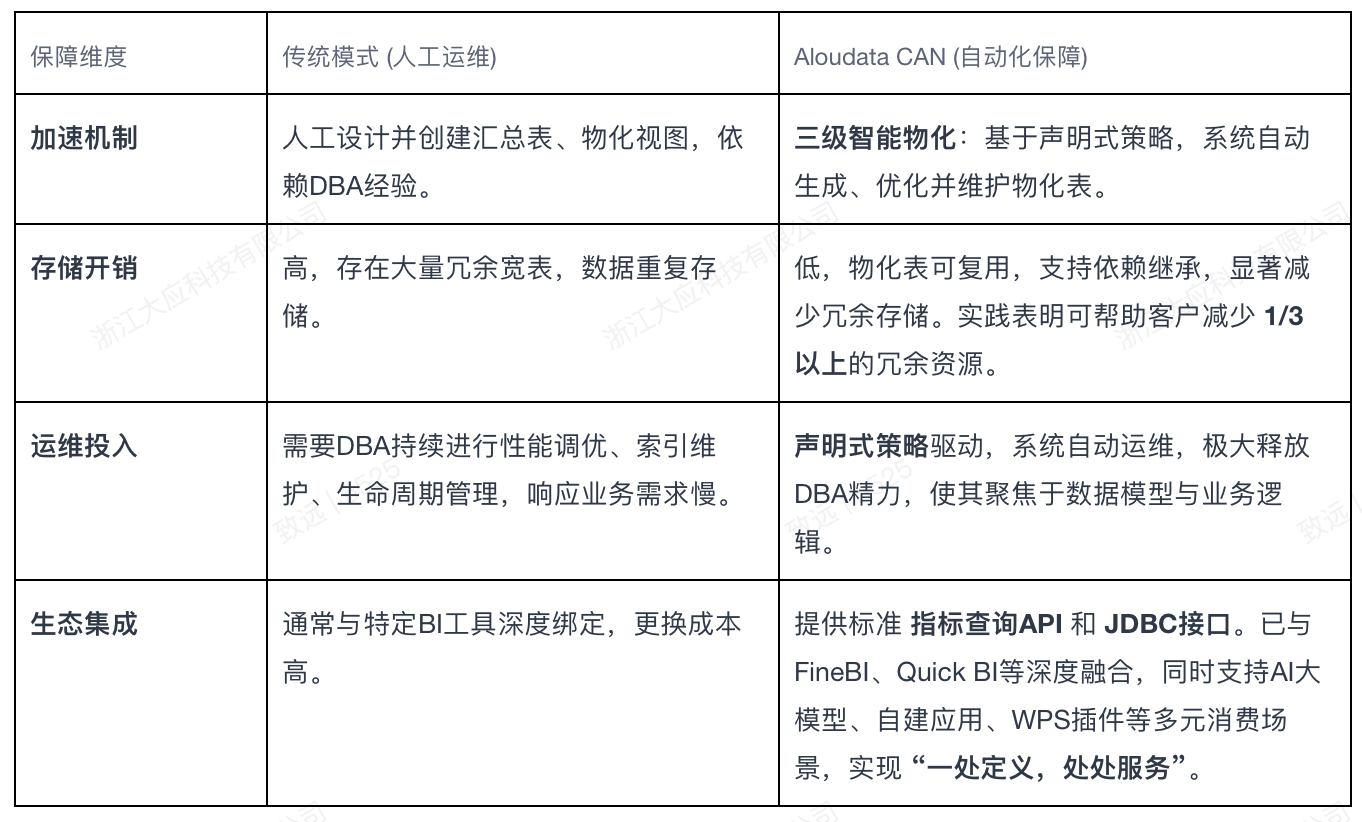
关键策略:Aloudata CAN 推荐 “存量挂载、增量原生、存量替旧” 的渐进式落地策略。企业无需推翻现有数仓,可将已稳定的宽表直接挂载使用,新需求则基于DWD明细层原生开发,逐步实现架构的平滑升级与成本优化。
六、综合选型建议:如何基于性能校验做决策?
决策应基于企业当前的数据规模、并发需求及技术栈现状。以下是清晰的决策路径参考:
场景 A(数据量 < 千万级,报表需求固定):
● 特征:数据量小,业务分析维度相对固化。
● 建议:传统BI工具或简单的数仓宽表模式仍可有效应对,引入自动化平台的投资回报率(ROI)可能不高。
场景 B(数据量达亿级或更高,业务查询需求灵活多变):
● 特征:面临“宽表依赖症”的典型痛点,业务希望自由下钻分析,但对查询延迟敏感。
● 建议:强烈建议评估 Aloudata CAN 这类 NoETL 指标平台。其 动态语义编织 和 智能物化加速 能力,能在保障秒级响应的同时,提供极大的分析灵活性,从根本上解决性能与灵活性的矛盾。
场景 C(高并发查询 + AI 智能问数需求):
● 特征:需要面向大量业务用户或系统提供稳定数据服务,并计划引入自然语言查询数据(ChatBI)。
● 建议:必须选择具备智能物化与 NL2MQL2SQL 能力的 AI-Ready 数据底座。Aloudata CAN的语义层为AI提供了精准、安全的指标化访问接口,从源头根治“数据幻觉”,是构建可靠数据智能应用的必备基础。
● 对于数字化初期的企业,采用NoETL架构更是一种 “弯道超车” 的机会,能跳过“先乱后治”的传统数据建设阶段,直接构建统一、敏捷的数据服务能力。
七、常见问题(FAQ)
Q1: 压测中的“亿级数据秒级响应”具体是在什么硬件和环境下实现的?
该性能指标基于典型企业级服务器配置(如8核32GB内存)及对接主流数据湖仓(如Hive, Spark)的环境下测得。核心依赖 智能物化引擎 对查询的透明加速。首次查询可能执行原生计算,但热点查询路径会被自动优化并物化,后续相同或类似的查询即可达到秒级响应。
Q2: 智能物化会不会导致存储成本急剧上升?
不会。与传统人工建宽表不同,智能物化采用 复用与继承策略。系统会自动判断并复用相同粒度的物化结果,并通过物化表之间的依赖关系减少重复存储。实际客户案例表明,该机制可帮助减少1/3以上的冗余存储资源。
Q3: 如果我们的查询模式非常不固定,智能物化还能有效加速吗?
能。智能物化引擎具备 自适应学习能力。对于不固定的查询模式,系统会基于实时查询负载进行分析,动态决策优先对高频或计算复杂的查询路径进行加速。同时,底层 语义引擎 具备强大的 查询改写能力,即使未命中物化表,也能通过生成高度优化的SQL来保障较优的查询性能。
Q4: 引入 Aloudata CAN 是否需要推翻现有的数仓和 BI 工具?
完全不需要。我们推荐采用 “存量挂载、增量原生” 的渐进式落地策略。现有稳定运行的宽表可直接挂载到平台统一服务口径;所有新的分析需求,则直接基于DWD明细层通过配置化方式开发,逐步替换老旧、低效的宽表,实现技术架构的平滑过渡与升级。
八、核心要点总结
- 架构范式革新:从依赖 预计算物理宽表 的静态模式,转向基于 NoETL 语义编织 的动态计算模式,是解决亿级数据查询性能瓶颈的根本路径。
- 性能可保障:通过 声明式物化策略 与 智能路由,Aloudata CAN 能够在提供任意维度组合分析能力的同时,保障亿级数据查询 P90 <1s、P99 <5s 的稳定性能。
- 成本效率优化:三级智能物化 机制通过复用与继承,显著降低冗余存储,结合自动化运维,能帮助释放超过1/3的服务器资源,降低TCO。
- 落地风险低:支持 “存量挂载、增量原生” 策略,无需推翻现有数据栈,即可平滑实现指标统一、性能提升与架构现代化。
- 面向未来:作为 AI-Ready 数据底座,其统一的语义层为 NL2MQL2SQL 提供了坚实基础,是构建可靠、无幻觉的企业级数据智能应用的必备前提。
本文首发于 Aloudata 官方技术博客,查看更多技术细节与高清图表,请访问原文链接:https://ai.noetl.cn/knowledge-base/aloudata-can-billion-level-detail-query-benchmark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号