EAST 口径文档自动化生成:破解 SQL 过滤条件解析难题,实现 20 倍效率提升
本文首发于 Aloudata 官方技术博客:《一表痛、EAST、1104 报表口径文档自动生成:解析 SQL 过滤条件,一键溯源与保鲜》https://ai.noetl.cn/knowledge-base/east-document-generation-sql-filter-condition 转载请注明出处。
摘要:EAST 等监管报送指标口径文档的自动生成,核心挑战在于对复杂 SQL 中过滤条件(WHERE、JOIN ON等)的精准识别与逻辑解析。传统表级或列级血缘工具无法穿透此逻辑,导致人工梳理耗时数月、口径易失效。本文探讨了如何通过算子级血缘与行级裁剪技术,实现 EAST 口径的自动化盘点与一键溯源,将盘点效率提升 20 倍,并构建主动元数据驱动的数据治理闭环。
在金融监管日益严格的背景下,EAST、1104 等监管报送已成为银行数据团队的核心工作。然而,指标口径文档的梳理却是一个公认的“效率黑洞”。传统依赖人工逐行扒代码的方式,不仅耗时数月,且难以保证口径的准确性与实时性。本文将深入剖析这一难题的技术核心——SQL 过滤条件的精准解析,并介绍如何通过算子级血缘技术实现 EAST 口径文档的自动化生成与持续保鲜。
一、监管报送的困境:传统口径梳理的真实成本
面对复杂的监管指标,银行数据团队普遍陷入“看不清、盘不动、保鲜难”的困境。监管指标的加工逻辑通常深藏在数百行、涉及多级嵌套和存储过程的 SQL 中。
这种传统人工模式的成本主要体现在三个维度:
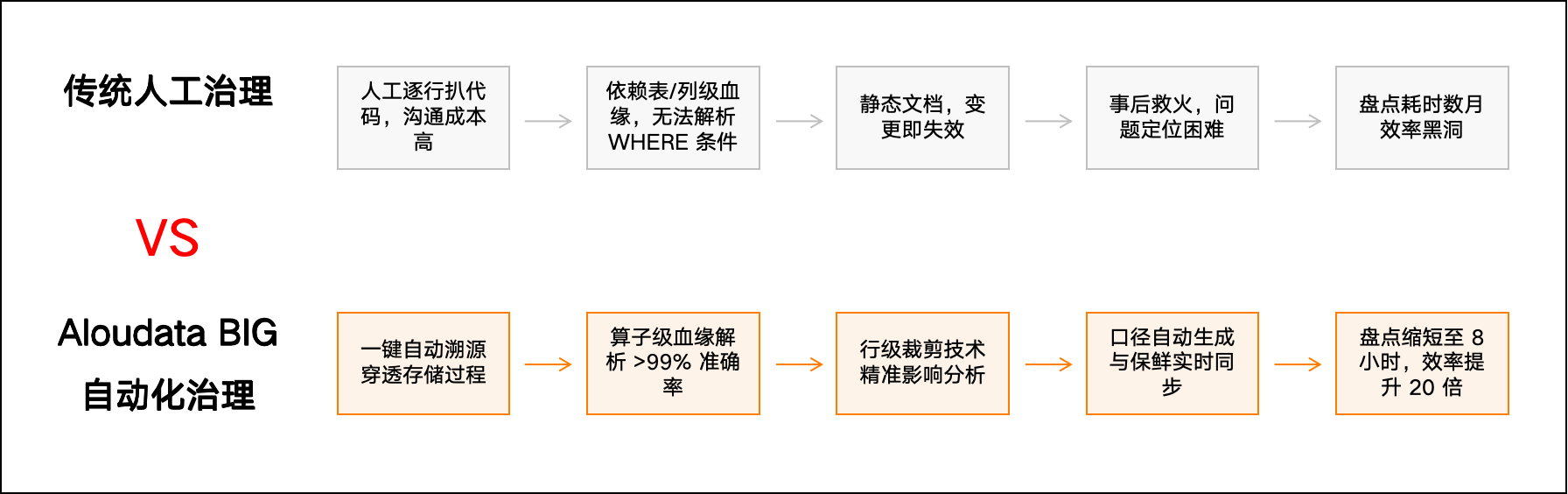
● 效率黑洞:一个 EAST 指标的口径梳理,需要数仓工程师反复沟通、逐层追溯,耗时数周甚至数月。相比之下,采用自动化手段的机构(如浙江农商联合银行)可将全盘盘点时间从数月缩短至 8 小时。
● 精度盲区:人工解读复杂 SQL(如嵌套子查询、存储过程)极易遗漏关键过滤条件。例如,“对公贷款余额”指标可能包含“贷款状态=正常”、“客户行业非房地产”等多个 WHERE 筛选,人工偏差会直接导致口径文档失真,埋下合规隐患。
● 保鲜难题:数据仓库持续演进,一旦上游 ETL 逻辑变更,静态的、人工维护的口径文档立即失效,导致文档与实际生产长期脱节。
二、技术破局关键:为何传统血缘工具无法解析 SQL 过滤条件?
自动化生成口径文档的构想之所以难以落地,根本在于传统血缘工具的解析粒度不足。它们无法理解 SQL 中最关键的“行级数据筛选逻辑”。
真正的难点不是回答“数据来自哪个表的哪个字段”,而是回答“这个指标具体是由哪一部分数据(符合什么条件)计算出来的”。这正是 WHERE、JOIN ON 等过滤条件的价值所在。
传统工具在此存在代际差距:
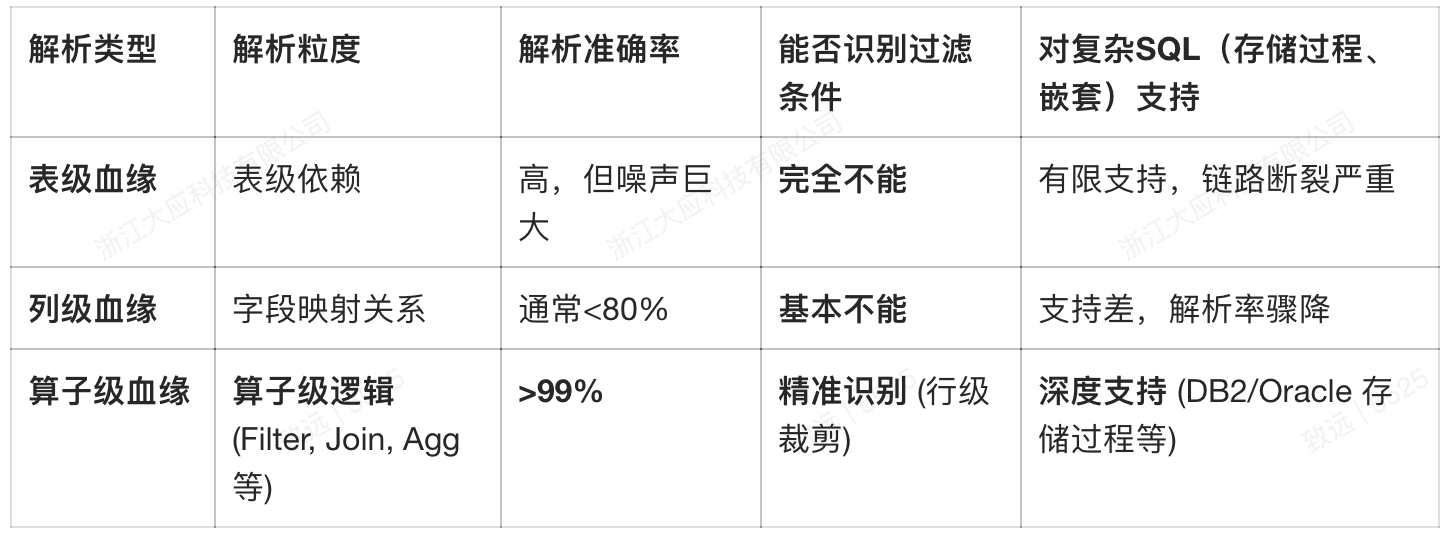
● 表级血缘的“狼来了”效应:仅能告知数据来源表,当非相关字段变更时,会产生大量无效下游影响告警,消耗信任。
● 列级血缘的“半盲状态”:能追踪字段传递,但无法解析 CASE WHEN 条件分支、复杂表达式,尤其无法穿透 WHERE 子句的过滤逻辑。它无法告知“某分行存款总额”是否限定了“客户等级=A 类”。
因此,要实现口径的自动化、准确化提取,必须突破列级血缘,深入到 SQL 执行的算子层面,即算子级血缘(Operator-level Lineage)。
三、核心解法:算子级血缘与行级裁剪技术
以 Aloudata BIG 为代表的主动元数据平台,通过深入解析 SQL 的抽象语法树(AST),实现了算子级血缘,从而将黑盒化的数据加工链白盒化。其核心能力包括:
- 白盒化口径提取:自动穿透临时表、多层嵌套子查询以及 DB2、Oracle 等存储过程(PL/SQL),将分散在多段 SQL 中的业务逻辑,压缩合并成一段清晰、可读的“加工口径描述”,直接输出文档文本。
- 行级裁剪 (Row-level Pruning):精准识别 WHERE、JOIN ON、HAVING 等子句中的过滤条件。在进行上游变更影响分析时,能智能判断变更是否真的会影响当前指标。例如,上游表“客户信息表”中“所属支行”枚举值变更,只会影响筛选条件中包含该支行的下游指标。此项技术能将不必要的评估分支减少 80% 以上,实现精准影响分析。
- 可视化逐层下钻:提供从报表指标反推至源系统的完整可视化血缘图谱,可点击任意节点查看具体加工 SQL、字段映射及关键过滤条件,便于复核、审计与问题定位。
四、实践验证:银行如何将 EAST 盘点效率提升 20 倍?
头部金融机构的实践已验证,基于算子级血缘的自动化口径管理能带来显著业务回报:
● 浙江农商联合银行:解决了 DB2 存储过程血缘解析的行业难题。通过部署相关技术,实现了监管指标溯源人效提升 20 倍,EAST 等指标的全盘盘点周期从数月缩短至 8 小时内完成,对 DB2 存储过程的解析准确率达 99%。
这些案例证明,自动化口径管理是实现 “指标溯源、血缘分析、线上化管理” 的核心技术基石。
五、实施路径:从试点到全行推广
建议金融机构采用“由点及面、价值驱动”的策略,构建主动元数据能力:
- 场景试点,验证价值:选取 1-2 个逻辑复杂的 EAST 报表模块(如“大额风险暴露”)试点,重点验证算子级血缘解析准确率与自动化生成口径的可用性。
- 流程嵌入,形成闭环:将自动化口径与现有报送流程、DataOps 研发流程融合。实现 SQL 变更的事前影响评估(风险防控)和故障的分钟级根因定位。
- 体系推广,构建基座:将能力扩展至 1104、一表通等体系,并应用于数仓模型治理、敏感数据管控等场景,最终构建企业级 DataOps 体系。
六、常见问题 (FAQ)
Q1: 算子级血缘和列级血缘主要区别是什么?对 EAST 报送具体有何帮助?
算子级血缘深入 SQL 执行计划,能精准解析 WHERE 过滤、JOIN 条件、聚合分组等具体操作逻辑;列级血缘只追踪字段映射关系,无法理解数据筛选逻辑。对于 EAST 报送,算子级血缘能自动回答“指标是基于哪部分数据(如‘贷款状态=正常’)计算的”,从而生成准确口径文档,而列级血缘只能给出字段列表,仍需大量人工解读。
Q2: 我们的 SQL 非常复杂,包含大量存储过程和嵌套查询,能准确解析吗?
可以。以 Aloudata BIG 为例,其核心技术优势之一就是覆盖复杂场景,特别对 DB2、Oracle、GaussDB 等的存储过程(PL/SQL)进行了深度适配,解析准确率超过 99%。无论是动态 SQL、临时表还是多层嵌套,都能实现穿透解析。
Q3: 自动生成的口径文档,如何保证其持续“保鲜”,跟上代码的变更?
主动元数据平台的血缘关系通过主动解析代码、日志等方式实时或准实时更新。当上游代码变更时,平台能自动重新解析并通知责任人。基于此生成的口径文档是“活”的、与代码逻辑实时同步的视图,解决了传统文档“一发布即过时”的难题。
核心要点总结
- 核心难点:EAST 口径自动化生成的最大技术障碍在于对 SQL 中行级过滤条件(WHERE 等)的精准解析。
- 技术代差:算子级血缘(Operator-level Lineage) 通过解析 SQL 执行算子,实现了 >99% 的解析准确率与行级裁剪能力,是破局关键。
- 核心价值:能够自动穿透复杂逻辑(如存储过程),一键生成可读口径,并将监管指标盘点效率提升 20 倍,实现口径实时保鲜。
- 演进路径:从痛点场景试点出发,将自动化能力嵌入 DataOps 流程,最终构建覆盖全链路的主动元数据基座。
再次提醒:本文更详细的图表与案例细节,请访问 Aloudata 官方技术博客阅读原文:https://ai.noetl.cn/knowledge-base/east-document-generation-sql-filter-condition

 浙公网安备 33010602011771号
浙公网安备 33010602011771号