
Linux网络管理工具之mtr
参考资料:
mtr的man手册
简介
MTR的名称来源是My TraceRoute,原来源是Matt's TraceRoute。mtr是一个网络诊断工具,将ping和traceroute命令的功能合二为一。
命令ping着重查看到目标节点的延迟。
# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=2 ttl=106 time=245 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=106 time=245 ms ... ...
命令traceroute可以查看数据包经过的每一个节点(或者说每一跳(hop))的信息。
# traceroute -n 8.8.8.8 traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets 1 192.168.1.1 1.229 ms 1.143 ms 1.055 ms 2 117.30.114.1 133.626 ms 133.606 ms 134.264 ms ... ... 12 108.170.237.45 252.366 ms 209.85.252.245 282.760 ms 209.85.240.31 282.729 ms 13 8.8.8.8 241.518 ms 241.971 ms 250.866 ms
对于数据包从源到目的地所经过的每个节点,mtr都会记住。而后向这些节点发送ICMP数据包,通过ICMP响应数据包来获取这些节点的网络信息(如延迟、丢包率等)。大多数情况下mtr检测网络信息时使用的数据包是ICMP数据包,不过也可以是TCP或者UDP数据包。
我们可以键入以下命令尝试执行。
注意:我自己使用Vmware Workstation Pro 15.5构建虚拟机时,如果虚拟机的网络是NAT模式的话,那么mtr追踪百度,出来的结果就很少,只有短短一两行。切换成桥接模式才正常。有知道如何解决这个疑难杂症的朋友们,望不吝赐教!
# mtr -n www.baidu.com
得到的结果如下,全屏会被替换成mtr的输出结果,默认情况下每隔1秒mtr就会发送ICMP数据包去探测网络情况,因此界面每隔1秒就会刷新1次。
在这个界面下我们可以键入各种命令来与mtr结果进行交互,例如p是暂停,空格是继续等。像这种用户可以键入命令与之交互的模式/界面,一般是基于curses(一种终端控制库)的文本界面(TUI)。
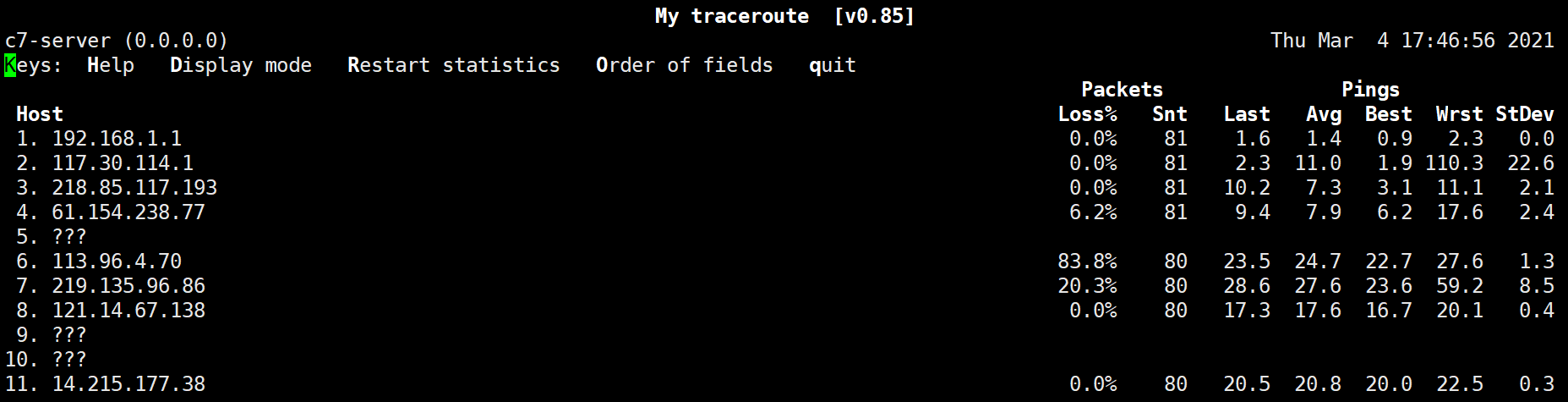
接下来我们将围绕命令的选项、与命令结果的交互命令以及如何解析mtr结果展开讨论。
命令的选项
操作系统和软件版本:
# lsb_release -d Description: CentOS Linux release 7.5.1804 (Core) # mtr --version mtr 0.85
man手册中的语法比较冗杂,因为它把短选项和长选项都列出来了。
mtr [-BfhvrctglxspQemniuTP46] [--help] [--version] [--report] [--report-wide] [--report-cycles COUNT] [--curses] [--split] [--raw] [ --xml] [--mpls] [--no-dns] [--show-ips] [--gtk] [--address IP.ADD.RE.SS] [--interval SECONDS] [--max- ttl NUM] [--first-ttl NUM] [--bitpattern NUM] [--tos NUM] [--psize BYTES | -s BYTES] [--tcp] [--udp] [--port PORT] [--timeout SECONDS] HOSTNAME [PACKETSIZE]
我们可以大致简化成这样,然后我们再对一个个选项进行逐一理解。
mtr [OPTIONS] HOSTNAME
-h, --help:显示命令语法的简要情况。
-v, --version:显示版本。这个还是有点重要的,不同版本的mtr输出的结果可能不同。
-r, --report:使用报告模式(report mode)。上面我们演示过了,默认情况下运行mtr会进入TUI界面,如果我们不希望mtr进入TUI而只是希望其像其他命令一样直接输出结果的话,我们可以使用报告模式。
# mtr -r 8.8.8.8 Start: Fri Mar 5 10:56:20 2021 HOST: c7-server Loss% Snt Last Avg Best Wrst StDev 1.|-- gateway 0.0% 10 1.4 1.8 1.1 3.4 0.7 2.|-- 1.114.30.117.broad.xm.fj. 0.0% 10 65.1 24.2 1.6 115.9 38.4 3.|-- 218.85.117.189 0.0% 10 2.5 2.9 2.1 5.1 0.7 4.|-- 61.154.238.65 0.0% 10 3.7 5.1 3.5 7.0 1.2 5.|-- 202.97.82.221 0.0% 10 25.5 22.0 18.7 26.1 2.9 6.|-- 202.97.94.237 20.0% 10 33.6 33.9 32.1 36.2 1.1 7.|-- 202.97.12.186 70.0% 10 19.3 19.6 19.3 20.1 0.0 8.|-- 202.97.50.38 0.0% 10 211.0 218.8 209.9 233.7 8.6 9.|-- 118.85.205.234 0.0% 10 217.1 213.9 205.1 222.2 6.2 10.|-- 72.14.217.174 0.0% 10 243.0 245.9 234.9 262.2 7.1 11.|-- 108.170.241.193 20.0% 10 255.2 256.3 255.2 259.4 1.3 12.|-- 142.250.224.131 0.0% 10 256.4 255.8 254.3 256.5 0.5 13.|-- dns.google 10.0% 10 244.6 244.7 243.8 245.5 0.4
这里我们对这个报告的每个字段进行一个浅析:
- 从1~13,是一个递增的序号,表示数据包经过的第几跳,通过最后一跳的序号我们也可以知道数据包一共经过了几跳。
- 所经过的路由节点的IP地址,如果支持反向解析的则反解为主机名。
- Loss%:丢包率。
- Snt:已发送的数据包。
- Last:最近一次数据包的延时,mtr所显示的延时相关的时间单位均是毫秒。
- Avg:平均延时。
- Best:最小延时。
- Wrst:最大延时。
- Stdev:标准差(Standard Deviation),延时的标准差,这个值越小则延时越稳定。
-c, --report-cycles COUNT:报告模式的默认情况下只会发送10个数据包,我们可以使用-c来指定需要发送的数据包的数量。字段Snt显示的是发送的数据包。
# mtr -c 5 -r 8.8.8.8
-w, --report-wide:宽(wide)报告模式,默认的报告模式,如果遇到主机名比较长的情况的话,会将其截断。
1.114.30.117.broad.xm.fj. # 未使用宽报告模式 mtr -w 8.8.8.8 1.114.30.117.broad.xm.fj.dynamic.163data.com.cn # 使用宽报告模式
-s, --psize BYTES:指定数据包的大小,单位是字节。也可以在命令行的尾部指定PACKETSIZE。
mtr -s 100 8.8.8.8 mtr 8.8.8.8 100 # 这种指定方式无结果,不知为何。
-t, --curses:强制mtr使用curses库的TUI界面,默认就是该选项。
-e, --mpls:应该是使mtr显示ICMP扩展中的MPLS信息。MPLS应该是一种多协议的封装技术,通过避免查询路由表来加速路由,这应该是一种高级的用法,我也不太了解。
-n, --no-dns:不进行主机名的解析。这样子IP地址就不会反解成主机名了,加快mtr的返回结果的速度。
mtr -n -r 8.8.8.8 gateway <==> 192.168.1.1 1.114.30.117.broad.xm.fj. <==> 117.30.114.1 dns.google <==> 8.8.8.8
-b, --show-ips:同时显示主机名和IP地址。在分隔(split)模式和报告模式中都可以使用。报告模式中如果被截断的话就使用宽报告模式。
-g, --gtk:使用基于GTK的GUI,一般用不到。
-p, --split:分隔模式,这种模式适用于split-user interface。我也没看懂什么意思。输出的结果类似于以空格为分隔符分隔每个字段。
# mtr -p -c 1 8.8.8.8
-l, --raw:将结果输出成原生(raw)模式,这种模式可以被其他程序所表达。一般用不到。
-x, --xml:输出成XML格式。
-a, --address IP.ADD.RE.SS:指定mtr探测时数据包从哪个IP地址出去。不过该选项不可用于DNS请求,否则结果可能会出乎意料。
-i, --interval SECONDS:指定每次发送ICMP ECHO请求数据包的间隔时间,单位是秒,默认1秒。这个数只要是正数就行,不一定非得是正整数。
mtr -i 1 8.8.8.8 mtr -i 0.5 8.8.8.8
-m, --max-ttl NUM:指定我们发送的数据包的TTL值。mtr就是通过这个值,来向路由路径中的每个节点发送数据包。例如在我们的示例中,总共有13个节点,因此如果要设置TTL的话,最小必须设定为13,否则数据包到不了8.8.8.8。
mtr -m 1 -r -c 1 8.8.8.8 # 1的结果会比较奇怪 mtr -m 2 -r -c 1 8.8.8.8 mtr -m 5 -r -c 1 8.8.8.8 mtr -m 12 -r -c 1 8.8.8.8
-f, --first-ttl NUM:指定我们从第几个节点开始进行探测,默认是从第一个节点(网关)开始。
mtr -f 5 -r -c 1 8.8.8.8
-B, --bitpattern NUM:指定有效负载中的位模式(bit pattern),值介于0~255。这里的bit pattern,我的理解是多位的二进制数据,可能是4位、8位、16位等,他们一同来表示某个东西,例如4个字节表示整型int。那么位模式就是4*8=32。
-Q, --tos NUM:指定IP头部中的服务类型的值,介于0~255。这里的服务类型指的是type of service,现在叫做DSCP,是IP头部的其中一个字段。DSCP一般用于一些实时的数据流,例如IP电话。
-u, --udp:使用UDP数据报文而不是ICMP ECHO。
-T, --tcp:使用TCP SYN数据包而不是ICMP ECHO。使用该选项的话会忽略修改数据包大小的-s、--psize或者PACKETSIZE,因为SYN数据包不包含数据。
-P, --port PORT:使用TCP追踪的时候指定目标端口。
--timeout SECONDS:TCP socket保持打开的超时时间(超时则断开连接)。这个只会影响最后1跳。如果这个值较大并且间隔时间(-i)较短的话,那么将会使用掉大量的文件描述符。
-4和-6:仅显示ipv4或者ipv6,一般用不到的选项,因为现在基本上都还是使用ipv4。
-o, --order fields order:指定要输出的字段信息。这个选项是一个比较重要的选项。
- L:lose ratio,丢包率。
- D:dropped packets,已丢弃的数据包。
- R:received packets,已接收的数据包。
- S:sent packets,已发送的数据包。
- N:newest RTT,最近的延迟,单位是毫秒。RTT指的是Round-Trip Time,表示数据包一去一回的时间。
- B:best/min RTT,最优的/最小的延迟。
- A:average RTT,平均延迟。
- W:worst/max RTT,最差的/最大的延迟。
- V:standard deviation,延时的标准差。表示每一次的延时和平均延时的差距。数值越小网络越稳定。
- G:getmetric mean,几何平均数。与算术平均数不同,理解它是个难点。
- J:current jitter,当前抖动。
- M:mean/average jitter,平均抖动。
- X:worst jitter,最大抖动。
- I:interarrival jitter。
报告解析
参考资料:
如果没有明确说明,那么【结果解析】中的mtr输出来自Linode。
% mtr --no-dns --report google.com HOST: deleuze Loss% Snt Last Avg Best Wrst StDev 1. 192.168.1.1 0.0% 10 2.2 2.2 2.0 2.7 0.2 2. 68.85.118.13 0.0% 10 8.6 11.0 8.4 17.8 3.0 3. 68.86.210.126 0.0% 10 9.1 12.1 8.5 24.3 5.2 4. 68.86.208.22 0.0% 10 12.2 15.1 11.7 23.4 4.4 5. 68.85.192.86 0.0% 10 17.2 14.8 13.2 17.2 1.3 6. 68.86.90.25 0.0% 10 14.2 16.4 14.2 20.3 1.9 7. 68.86.86.194 0.0% 10 17.6 16.8 15.5 18.1 0.9 8. 75.149.230.194 0.0% 10 15.0 20.1 15.0 33.8 5.6 9. 72.14.238.232 0.0% 10 15.6 18.7 14.1 32.8 5.9 10. 209.85.241.148 0.0% 10 16.3 16.9 14.7 21.2 2.2 11. 66.249.91.104 0.0% 10 22.2 18.6 14.2 36.0 6.5
以数字开头的每一行数据表示数据包所经过的每个路由节点,也称之为跳(hop)。我们主要关心的数据是延迟和丢包。延迟主要通过平均延迟Avg来判断。标准差用来表示平均延迟的信息是否更接近真实情况,标准差的值越大,那么平均延迟的可信度越低。
大体上我们可以把所有的路由节点划分为三段:
- 前2~3个节点一般是本地ISP段,假设我们是在用户的PC上键入mtr进行测试的话,那么就是客户本地的ISP段,例如家庭/小区的宽带/光纤。如果是这段节点异常,我们应该联系本地的电信/移动等ISP。
- 后2~3个节点一般是目标ISP段,目标一般是一些服务的提供商。比如我们购物的淘宝网,或者玩游戏时游戏运营商的游戏服务器所处的网络。如果是这段节点异常,我们应该联系淘宝网/游戏的客服联系技术人员处理。
- 中间节点。中间节点可能很多,一般会经过一些骨干网,跨越城市、省份、国家或者大洲的广域网络。如果是中间节点有问题的话,一般我们本地ISP和目标ISP都没什么办法。
丢包
一般来说,一旦我们看mtr输出中的某个节点的丢包突然很高,那么我们可能会认为那个节点出问题了。不过,对于大多数路由节点,它们会降低响应ICMP echo request数据包,甚至不相应。因为此类数据包一般用于网络探测,而不作为真实的网络流量数据存在。因此单纯的丢包不能代表真实的丢包情况,可能mtr命令发送的ICMP数据包被100%丢弃,但是真实流量的数据包就不丢弃了。如果我们想判断到底是ICMP流量限制还是真实丢包情况的话,可以看丢包节点的后续节点是否出现丢包。如果像下面这样后续节点都不丢包的话,那么可以理解为该丢包应该是由于ICMP流量限制。
HOST: example Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 50.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 0.0% 10 7.2 8.3 7.1 16.4 2.9 6. 209.85.254.247 0.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 0.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 0.0% 10 39.6 40.5 39.5 46.7 2.2
如果后续多个节点也出现丢包的话,那么可能真的是有丢包的情况产生。要记住,ICMP流量限制和丢包可能同时发生!
像这个示例中,我们认为丢包节点的后续节点中的最低丢包率为真实的丢包率,即40%。
HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 60.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 60.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 50.0% 10 7.2 8.3 7.1 16.4 2.9 6. 209.85.254.247 40.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 40.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 40.0% 10 39.6 40.5 39.5 46.7 2.2
第3节点产生丢包,由0%升至60%,并且后续的节点均没有出现无丢包情况,因此可以判断从该节点开始应该是真的丢包了。第3第4节点丢包60%,后续节点逐渐下降至40%直至末节点,此类情况我们一般选择靠后的最低的丢包率作为真实丢包率。因此从结果来看真实丢包率应该在40%左右,其中中间节点可能有10%~20%左右的由于ICMP流量限制出现丢包。这个10%和20%是取节点丢包率与真实丢包率的差。
有的时候,数据包发送过去没问题,但是在回来的途中可能有问题。这个时候一般是建议进行双向mtr来结合判断网络情况。
由于网络协议在设计之初对于一些网络降级(degrade)的情况具备一些弹性,并且路由可能因为各种各样的问题多多少少会有一些波动的情况。因此不用强迫自己去深究每一处丢包,10%左右的丢包并不是我们主要关心的问题,可能应用层就可以补偿掉这些丢包带来的损失了。
延迟
一般来说,随着距离的增长和节点的增加,延迟都是越来越高的。不过在同一个网络/地区下,一般是稳步地线性地增加。延迟非常依赖于测试时的线路质量,因此在查看延迟数据的时候,最好是有一个正常情况下的延迟数据记录来做对比会比较好。这里的正常情况下应该指的是软件/应用可以在当下的延迟下提供完整的功能等。
线路质量也会受到物理层的影响,例如拨号上网(dial-up)的线路的延迟一定是大于我们现在所广泛使用的双绞线、光纤的。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 388.0 360.4 342.1 396.7 0.2 5. 72.14.233.56 0.0% 10 390.6 360.4 342.1 396.7 0.2 6. 209.85.254.247 0.0% 10 391.6 360.4 342.1 396.7 0.4 7. 64.233.174.46 0.0% 10 391.8 360.4 342.1 396.7 2.1 8. gw-in-f147.1e100.net 0.0% 10 392.0 360.4 342.1 396.7 1.2
像该示例中从第4节点开始,延迟暴增并且维持到了末节点。那么我们就可以判断真的是有延迟问题发生了。即便常见的原因可能是饱和的对等会话(saturated peering session)、路由器配置不良或者堵塞的链路,但是我们基本不可能找出真实的原因。
不过有时候延迟可能也不是个问题,比如上面示例中即便出现了高延迟,但是数据包依然抵达了目标节点。延迟也可能受到返回路由的影响。但是数据包返回的路线可能与当时去的路线完全不同。
译者注:到这里有一个疑问点,如果双向mtr测试的路径不同的话,那么其参考价值会有多大?
从上面的示例来看,从第4节点开始延时暴增并且后续节点的延迟没有出现较大程度的上下波动,因此我们可以认为导致该延迟的原因出在第4节点。
ICMP流量限制除了会造成丢包的表象之外,也会造成延迟的表象。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 0.0% 10 254.2 250.3 230.1 263.4 2.9 6. 209.85.254.247 0.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 0.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 0.0% 10 39.6 40.5 39.5 46.7 2.2
第一眼我们会认为第5节点出问题了,因此延迟从10ms以内瞬间激增至250ms左右。此时应该和判断丢包类似,我们要看后面的延迟情况。随后节点的延迟一直保持在40ms左右,因此真实的延迟应该就只是在40ms左右。而第5节点的250ms很可能是由于该节点对ICMP数据包有做了流量的限制。如果随后节点的延迟维持在250ms,那么可能延迟真的就是250ms;如果随后节点的延迟降低到了0ms,那么第5节点的250ms的延迟很可能全部都是由于ICMP流量限制导致的。
常见报告
目标主机网络配置不当
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 0.0% 10 7.2 8.3 7.1 16.4 2.9 6. 209.85.254.247 0.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 0.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 100.0 10 0.0 0.0 0.0 0.0 0.0
第一眼看这个报告的时候,我们主要会关注到到末节点的数据包100%丢失。末节点的话,就是目标网络ISP段的数据,且是最后一个节点。由于是最后一个节点,我们就无法判断后续的节点的丢包情况了。ICMP的流量限制一般是发生在中间的节点,而且一般要结合后续节点来判断是否是流量的限制。
因此像这种情况就一般不会是中间路由节点的ICMP流量限制了。比较可能的情况是末节点的服务器(可能)的网络配置问题。如果真实的数据包也无法抵达的话,那么可能是防火墙配置错误了。当然也可能是服务器直接配置了拒绝响应ICMP数据包。
住宅(residential)或者商业(business)路由器
% mtr --no-dns --report google.com HOST: deleuze Loss% Snt Last Avg Best Wrst StDev 1. 192.168.1.1 0.0% 10 2.2 2.2 2.0 2.7 0.2 2. ??? 100.0 10 8.6 11.0 8.4 17.8 3.0 3. 68.86.210.126 0.0% 10 9.1 12.1 8.5 24.3 5.2 4. 68.86.208.22 0.0% 10 12.2 15.1 11.7 23.4 4.4 5. 68.85.192.86 0.0% 10 17.2 14.8 13.2 17.2 1.3 6. 68.86.90.25 0.0% 10 14.2 16.4 14.2 20.3 1.9 7. 68.86.86.194 0.0% 10 17.6 16.8 15.5 18.1 0.9 8. 75.149.230.194 0.0% 10 15.0 20.1 15.0 33.8 5.6 9. 72.14.238.232 0.0% 10 15.6 18.7 14.1 32.8 5.9 10. 209.85.241.148 0.0% 10 16.3 16.9 14.7 21.2 2.2 11. 66.249.91.104 0.0% 10 22.2 18.6 14.2 36.0 6.5
现象:第2节点(前几个)全丢包且没有IP地址。这种可能是本地ISP的配置的问题,问号的节点可能是本地的住宅网关。从丢包节点后续来看也都没有丢包。因此这个节点丢包应该只是不响应ICMP数据包而已。并且我认为之所以没显示节点IP可能也是因为节点拒绝响应ICMP的某些信息。
ISP路由器配置不当
如果目标主机无法正常访问,并且mtr报告中在某节点后的节点均是???的话,那么可能是最后一个有效节点或者其之后的某个路由配置有问题导致的。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 6. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 7. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 8. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 9. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 10. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0
这边的???我觉得和上个例子的不太一样。上面住宅网关的???只是某个节点而已,并且存在丢包的情况。而这里的情况是从某个节点之后连续到末尾的所有节点,并且丢包和延迟的结果都一样都是0。应该是到第4节点就停止了(mtr都不知道后续节点是什么),而不是说其之后的节点不响应mtr的数据包。
也有一些比较明显的可以看出来的,例如路由器配置不当导致的路由死循环。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. 12.34.56.79 0.0% 10 0.0 0.0 0.0 0.0 0.0 6. 12.34.56.78 0.0% 10 0.0 0.0 0.0 0.0 0.0 7. 12.34.56.79 0.0% 10 0.0 0.0 0.0 0.0 0.0 8. 12.34.56.78 0.0% 10 0.0 0.0 0.0 0.0 0.0 9. 12.34.56.79 0.0% 10 0.0 0.0 0.0 0.0 0.0 10. 12.34.56.78 0.0% 10 0.0 0.0 0.0 0.0 0.0 11. 12.34.56.79 0.0% 10 0.0 0.0 0.0 0.0 0.0 12. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 13. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0 14. ??? 0.0% 10 0.0 0.0 0.0 0.0 0.0
路由配置错误可能出现在第4或者第5节点,解决的办法只能尝试去判断错误节点的归属ISP,然后去联系处理。
ICMP比例限制
也就是我说的流量限制。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 60.0% 10 27.2 25.3 23.1 26.4 2.9 6. 209.85.254.247 0.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 0.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 0.0% 10 39.6 40.5 39.5 46.7 2.2
比例限制此前已经说过了,会导致中间某个或者某几个路由节点出现丢包或者延迟的情况,但是不会影响后续的节点。ICMP比例限制是ICMP协议仅仅是一个支撑/协助的协议,用来对网络进行探测的,而不是真实的数据流量。为了将有限的带宽更多地让给真实有效的数据,因此路由节点(尤其是骨干网)会针对ICMP做流量限制。
超时
超时的原因可能有很多。比如节点直接丢弃了ICMP数据包或者ICMP响应数据包返回失败了,那么在报告中就会呈现出“???”。
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 0.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 0.0% 10 6.7 6.8 6.7 6.9 0.1 5. ??? 0.0% 10 7.2 8.3 7.1 16.4 2.9 6. ??? 0.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 0.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 0.0% 10 39.6 40.5 39.5 46.7 2.2
超时不是丢包的必要现象,即出现丢包不一定必须有超时的情况。超时可能是为了QoS使得路由器丢弃数据包或者ICMP响应数据包返回失败。
高级
较新版本的mtr工具支持使用TCP数据包来探测,但是大多数情况下都不应该使用这类数据包。因为基于tcp的mtr使用SYN数据包来探测而大多数路由节点并不会响应这类数据包。
不过在一些特定的场景下,还是可以使用TCP数据包的。当我们需要判断某些防火墙规则的时候,我们可以使用TCP数据包来针对那些协议或者端口进行判断,也许可能是端口转发配置不当。
sudo mtr --tcp --port 80 --report --report-cycles 10 speedtest.dallas.linode.com sudo mtr --tcp --port 22 --report --report-cycles 10 50.116.25.154
小结
这篇文章大概阐述了mtr命令的用法,重点和难点在于对于mtr报告的理解。但是即便正确理解了报告,对于一些网络问题我们可能也无能为力。一个数据包从我们源头抵达目标主机所经过的网络段会有很多,包含本地ISP、中间ISP和目标ISP。中间ISP更可能涉及到不同的国家,所以一旦是中间ISP出现问题,那么基本上是只能听天由命了。
我们可以做的就是尽可能正确理解mtr的报告,并且做好报告提供给ISP。
高级功能中我们可以使用TCP/UDP协议针对特定的协议和端口进行探测是我们运维人员可能比较需要的功能。
但是所有的这些网络相关的工具,想要使用好就必须要求我们具备一定的网络知识基础,比如TCP/IP协议基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号