数据结构笔记6
7 内部排序
7.1 概念
7.1.1 排序定义
-
设{R0,R1,R2,…,Rn-1}是由n个记录组成的文件,{K0,K1,K2,…,Kn-1}是排序码集合,所谓排序就是将文件中的全部记录按排序码不增(或不减)的次序重新排列
-
形式化定义如下,
输入:n个记录是r0,r1,…,rn-1,其相应的关键码分别是k0,k1,…,kn-1,经过排序后
输出:r0’,r1’,…,rn-1’,其中k0’k1’ … kn-1’(不减)
(或k0’k1’ … kn-1’)(不增),
即按关键码升序或降序排列
7.1.2 内部排序和外部排序
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序;
反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
7.1.3 内部排序的方法
内部排序的过程是一个逐步扩大记录的有序序列长度的过程
基于不同的“扩大”有序序列长度的方法,内部排序方法大致可分下列几种类型:
-
插入类
- 将无序子序列中的一个或几个记录“插入”到有序序列中,从而增加记录的有序子序列的长度。
-
交换类
- 通过“交换”无序序列中的记录从而得到其中关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
-
选择类
从记录的无序子序列中“选择”关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
-
归并类
通过“归并”两个或两个以上的记录有序子序列,逐步增加记录有序序列的长度。
-
其它方法
7.2 操作
7.2.1 线性表 结构体定义
待排记录的数据类型定义如下
#define MAXSIZE 1000 // 待排顺序表最大长度
typedef int KeyType; // 关键字类型为整数类型
typedef struct {
KeyType key; // 关键字项
DataType info; // 其它数据项
} RecordNode; // 记录类型
typedef struct {
RecordNode r[MAXSIZE+1]; // r[0]闲置
int n; // 顺序表长度
} SqList; // 顺序表类型
7.2.2 排序算法
-
C语言学习中的2种排序方法
-
冒泡排序(稳定排序)
#include <stdio.h> #define n 10 void main() { int a[n+1], i, j, t; printf("Input n numbers:\n"); for(i=1; i<=n; i++) scanf("%d",&a[i]); printf("\n"); for(j=1; j<=n-1; j++) for(i=1; i<=n-j; i++) if(a[i]>a[i+1]) {t=a[i]; a[i]=a[i+1]; a[i+1]=t;} printf("The sorted numbers:\n"); for(i=1; i<=n; i++) printf("%d ",a[i]); }
-
-
选择排序(不稳定排序)
#include <stdio.h> #define n 10 void main() { int a[n+1], i, j, k, t; printf("Input n numbers:\n"); for(i=1; i<=n; i++) scanf("%d",&a[i]); printf("\n"); for(i=1; i<=n-1; i++) { k=i; for( j=i+1; j<=n; j++)//选择 if(a[j]<a[k]) k=j; if(i!=k )//交换 { t=a[i]; a[i]=a[k]; a[k]=t;} } printf("The sorted numbers:\n"); for(i=1; i<=n; i++) printf("%d ",a[i]); }
-
直接插入排序(稳定)
-
算法思想:将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增1的有序表。
-
实现“一趟插入排序”可分三步进行
-
在\(element[0..i-1]\)中查找\(element[i]\)的插入位置,\(element[0..j] < element[i] < element[j+1..i-1]\)
-
将\(element[j+1..i-1]\)中的所有记录均后移一个位置;
-
将\(element[i]\) 插入(复制)到\(element[j+1]\)的位置上。
-
-
-
-
void InsertSort (SortObject *pvector) //操作结果:记录record数组元素直接插入递增排序 { RecordNode *data=pvector->record; for ( i = 1; i < pvector->n; ++i) { //依次插入R1,R2,…Rn-1 temp=data[i]; for (j = i - 1; temp.key<data[j].key && j >=0; j--) { //由后向前找插入位置,排序码大于ki的记录后移 data[ j + 1 ] = data[ j ]; //后移 } if (j!=i-1) data[j+1]=temp; //j==i-1时不用复制 }
-
-
-
void InsertSort_1 (SortObject *pvector) //操作结果:记录record数组元素直接插入递增排序 { RecordNode *data=pvector->record; for ( i = 2; i <= pvector->n; ++i ) { //依次插入R2,R3,…Rn data[0] = data[i]; //暂存data[i] for (j = i - 1; data[0].key<data[j].key ; j--) { //由后向前找插入位置,排序码大于ki的记录后移 data[ j + 1 ] = data[ j ]; //后移 } data[ j+1]=data[0]; } }
直接插入排序算法简单、容易实现,适用于待排序记录基本有序或待排序记录较少时
当待排序的记录个数较多时,大量的比较和移动操作使直接插入排序算法的效率降低
-
7.2.3 插入排序算法
-
直接插入
-
折半插入
-
表插入
-
希尔排序
-
折半插入排序
因为 \(R[1..i-1]\) 是一个按关键字有序的有序序列,则可以利用折半查找实现“在\(R[1..i-1]\)中查找\(R[i]\)的插入位置”,如此实现的插入排序为折半插入排序。
void BiInsertionSort ( SqList &L ) { for ( i=2; i<=L.length; ++i ) { L.r[0] = L.r[i]; //将 L.r[i] 暂存到 L.r[0] for ( j=i-1; j>=high+1; --j ) L.r[j+1] = L.r[j]; //记录后移 L.r[high+1] = L.r[0]; //插入 } // for // BInsertSort low = 1; high = i-1; while (low<=high) { m = (low+high)/2; //折半 if (L.r[0].key < L.r[m].key) high = m-1; //插入点在低半区 else low = m+1; //插入点在高半区 } } -
表插入排序
为了减少在排序过程中进行的“移动”记录的操作,必须改变排序过程中采用的存储结构。利用静态链表进行排序,并在排序完成之后,一次性地调整各个记录相互之间的位置,即将每个记录都调整到它们所应该在的位置上。
void LInsertionSort (Elem SL[ ], int n){ //对记录序列SL[1..n]作表插入排序 SL[0].key = MAXINT ; SL[0].next = 1; SL[1].next = 0; for ( i=2; i<=n; ++i ) for ( j=0, k = SL[0].next;SL[k].key<= SL[i].key ; j=k, k=SL[k].next ) { SL[j].next = i; SL[i].next = k; } //结点i插入在结点j和结点k之间 } //LinsertionSort void Arrange ( Elem SL[ ], int n ) { p = SL[0].next; //p指示第一个记录的当前位置 for ( i=1; i<n; ++i ) { while (p<i) p = SL[p].next; q = SL[p].next; //q指示尚未调整的表尾 if ( p!= i ) { SL[p]←→SL[i]; //交换记录,使第i个记录到位 SL[i].next = p; //指向被移走的记录 } p = q; //p指示尚未调整的表尾, //为找第i+1个记录作准备 } } //Arrange -
希尔排序
基本思想:对待排记录序列先作“宏观”调整,再作“微观”调整。
所谓“宏观”调整,指的是,“跳跃式”的插入排序。具体做法为将记录序列分成若干子序列,分别对每个子序列进行插入排序
-
例如 将 n 个记录分成 d 个子序列
...
{ R[d],R[2d],R[3d],…,R[kd],R[(k+1)d] }
其中,d 称为增量,它的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为1
-
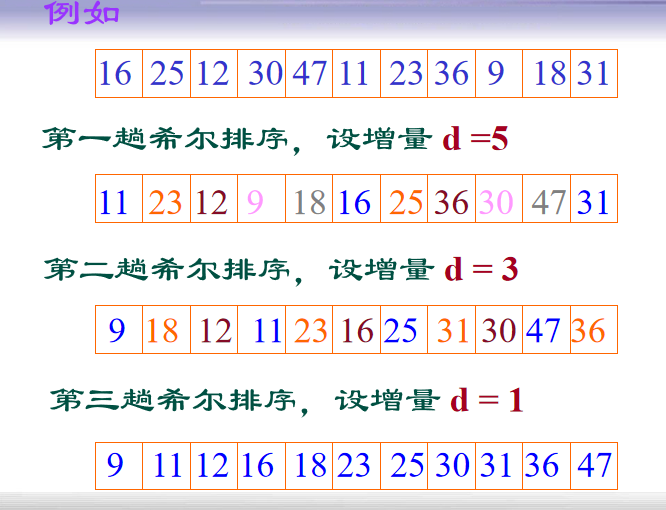
void ShellInsert ( SqList &L, int dk ) {
for ( i=dk+1; i<=n; ++i )
if ( L.r[i].key< L.r[i-dk].key) {
L.r[0] = L.r[i]; //暂存在R[0]
for (j=i-dk; j>0&&(L.r[0].key<L.r[j].key);
j-=dk)
L.r[j+dk] = L.r[j]; //记录后移,查找插入位置
L.r[j+dk] = L.r[0]; //插入
} // if
} // ShellInsert
void ShellSort (SqList &L, int dlta[], int t)
{ //增量为dlta[]的希尔排序
for (k=0; k<t; ++k)
ShellInsert(L, dlta[k]);
//一趟增量为dlta[k]的插入排序
} //ShellSort
7.2.4 快速排序
-
冒泡排序优缺点分析与改进
起(冒)泡排序:相邻两个关键字进行比较,并进行必要的数据交换,实现数据排序
效率不高。一次只确定一个数据的顺序,每次待比较的数据个数只减少1
- 改进方案
快速排序,改进方法是通过一趟排序,尽量让更多的待排序记录被放到可能的合适位置
- 改进方案
-
快速排序算法思想
通过一趟排序,将待排序记录分割成独立的两部分,其中
-
一部分记录的关键字比另一部分记录的关键字小,中间用第一个记录划分
-
然后对两部分继续快速排序,直到达到整个序列有序
-
-
快速排序算法(!!!!!!!!)
void quickSort(SortObject *pvector, int l, int r){ //l=0, r=n-1 int i, j; RecordNode temp, *data=pvector->record; if (l>=r) return ; //只有一个记录或无记录,无需排序 i=l; j=r; temp=data[i]; //令第l个元素为枢轴记录 while (i!=j) { while (i<j && data[j].key>=temp.key) j- -; //从右找交换key if (i<j) data[ i++ ] = data[ j ]; //小记录交换到前面 while ( i<j && data[i].key<=temp.key) i++; //从左找交换key if (i<j) data[j--] = data[i]; //大记录交换到前面 } data[i[=temp; //将Rl存入其最终位置 quickSort(pvector, l, i-1); //递归处理左区间 quickSort(pvector, i+1, r); //递归处理右区间 }//quickSort
7.2.5 分治思想
-
分治基本思想
分治法求解问题的过程是,将整个问题分解成若干个小问题后分而治之。如果分解得到的子问题相对来说还太大,则可反复使用分治策略将这些子问题分成更小的同类型子问题,直至产生出方便求解的子问题,必要时逐步合并这些子问题的解,从而得到问题的解。
-
适合用分治的问题具有以下几个特征
-
该问题的规模缩小到一定的程度就可以很容易解决;
-
该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质;
-
该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题;
-
利用该问题分解出子问题解可以合并为该问题解。
-
-
分治思想基本框架
divide-and-conquer(P)
{
if ( | P | <= n0)
adhoc(P); //解决小规模的问题
else
divide P into smaller subinstances P1,P2,...,Pk;
//分解问题
for (i=1, i<=k, i++)
yi=divide-and-conquer(Pi); //递归的解各子问题
return merge(y1,...,yk);
//将各子问题的解合并为原问题的解
}
7.2.6 堆排序
-
堆的定义
n个元素的序列(k0,k1,…,kn-1),当且仅当满足下列关系时,称之为堆
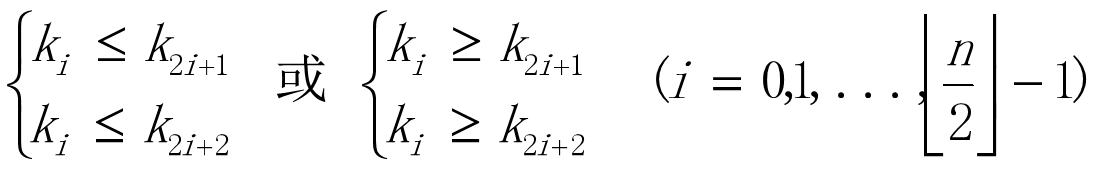
-
堆的特点
一组数据{96, 83, 27, 38, 11, 9}看成是一棵完全二叉树,则堆的含义是:完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值
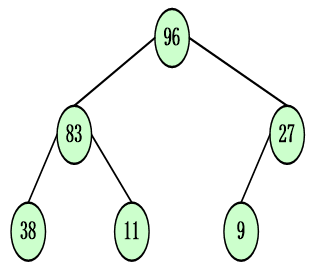
-
堆排序
-
输出堆顶元素
-
使剩余n-1个元素序列重又建成一个堆,则得到次大值
-
重复(1)(2),得到一个排序序列
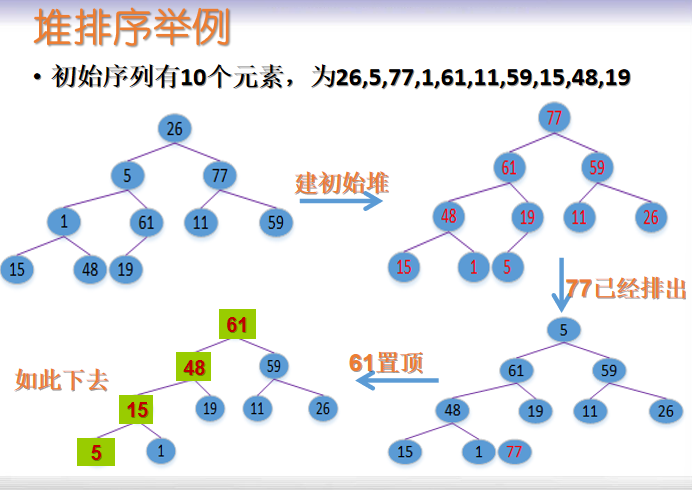
-
-
堆的存储:
从堆的定义看,可以用顺序存储来保存堆,顺序存储的一组数据,其元素之间的关系看成是二叉关系
-
堆排序算法(O(nlog2n))
void heapSort(SortObject *pvector){
int i, n; RecordNode temp;
n=pvector->n;
for (i=n/2-1; i>=0; i--)
sift(pvector, n, i); //建初始堆
for (i=n-1; i>0; i--) { //进行n-1趟堆排序
temp=pvector->record[0]; //堆顶与最后记录交换
pvector->record[0]=pvector->record[i];
pvector->record[i]=temp;
sift(pvector, i, 0); //重新调整建堆
}
}
- Sift函数,重新调整堆
void sift(SortObject *pvector, int size, int p){
RecordNode temp=pvector->record[p];
int child=2*p+1;
while (child<size) {
if ((child<size-1) && (pvector->record[child].key
<pvector->record[child+1].key))
child++; //选择值比较大的子结点
if (temp.key < pvector->record[child].key) {
pvector->record[p]=pvector->record[child]; //大值点上移
p=child; child=2*p+1;
}
else break; //调整结束 }
pvector->record[p]=temp; //将temp放入正确位置
}
-
堆的建立
-
如果堆为空,则数值放在根结点
-
如果堆不为空,则数值放在顺序存储的末尾,再顺着父结点搜索该数值的合理存储位置,相应的交换数据,直到搜索到根结点为止
-
-
堆结点的删除
-
如果被删除结点在顺序存储位置的末端,则直接删除该结点
-
如果被删除结点不在顺序存储位置的末端,则拿最末端的数值与删除结点交换,再删除最末端结点
-
从交换结点开始调整堆,以保证其性质不变
-
7.2.7 归并排序
归并排序的过程基于下列基本思想进行:
将两个或两个以上的有序子序列“归并” 为一个有序序列
-
归并
在内部排序中,通常采用的是2-路归并排序,即将两个位置相邻的记录有序子序列归并为一个记录的有序序列
void Merge (RcdType SR[], RcdType &TR[], int i, int m, int n) { //将有序的记录序列 SR[i..m] 和 SR[m+1..n] //归并为有序的记录序列 TR[i..n] for (j=m+1, k=i; i<=m && j<=n; ++k) { //将SR中记录由小到大地并入TR if (SR[i].key<=SR[j].key) TR[k] = SR[i++]; else TR[k] = SR[j++]; } } //Merge

 浙公网安备 33010602011771号
浙公网安备 33010602011771号