

冒泡排序是比较简单的一种排序算法,
基本原理是依次比较两个相邻的元素,如果两个元素的顺序错误,则交换两个元素的位置,
算法流程图如下:
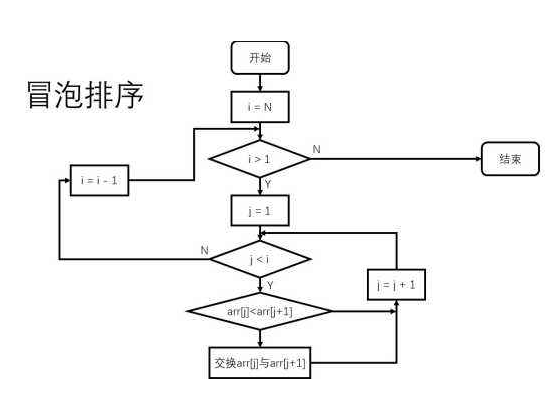
对照流程图,用erlang代码实现:
1 bubble([]) -> 2 []; 3 bubble([H]) -> 4 [H]; 5 bubble([H | T]) -> 6 bubble1(T, H, [], []). 7 8 bubble1([], H, [], R) -> 9 [H | R]; 10 bubble1([], H, TailList, R) ->%%一轮结束,把最终的元素放在结果中,开始下一轮 11 [NewH | T] = lists:reverse(TailList), 12 bubble1(T, NewH, [], [H | R]); 13 bubble1([H1 | T], H, TailList, R) -> 14 if 15 H1 >= H -> 16 bubble1(T, H, [H1 | TailList], R); 17 true -> 18 bubble1(T, H1, [H | TailList], R) 19 end.
%%第二种方式
bb([]) ->
[];
bb([H]) ->
[H];
bb(L) ->
Tuple = list_to_tuple(L),
Len = erlang:size(Tuple),
bb_(Tuple, Len, 1).
bb_(Tuple, 1, _) ->
Tuple;
bb_(Tuple, L1, L1) ->
bb_(Tuple, L1 - 1, 1);
bb_(Tuple, L1, L2) ->
E1 = element(L2, Tuple),
E2 = element(L2 + 1, Tuple),
if
E1 > E2 ->
Tup1 = erlang:setelement(L2, Tuple, E2),
Tup = erlang:setelement(L2 + 1, Tup1, E1),
bb_(Tup, L1, L2 + 1);
true ->
bb_(Tuple, L1, L2 + 1)
end.
观察上面的代码可以看到,每遍历一次元素(冒一次泡泡),就要对'尾巴(TailList)'做一次逆序,实际上是不需要的,这一点可以优化以节约开销
1 bubble([]) -> 2 []; 3 bubble([H]) -> 4 [H]; 5 bubble([H | T]) -> 6 bubble1(T, H, [], []). 7 8 9 bubble1([], H, [], R) -> 10 [H | R]; 11 bubble1([], H, [NewH | T], R) ->%%一轮结束,把最终的元素放在结果中,开始下一轮 12 bubble1(T, NewH, [], [H | R]); 13 bubble1([H1 | T], H, TailList, R) -> 14 if 15 H1 >= H -> 16 bubble1(T, H, [H1 | TailList], R); 17 true -> 18 bubble1(T, H1, [H | TailList], R) 19 end.
ps.网上还有一种通过增加标志位来降低时间复杂度的算法,回头有时间再来折腾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号