

numpy之003ndarray
numpy常用的函数和属性
函数
语法:numpy.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
- object:任何暴露数组接口方法的对象,通常是列表或元组。
- dtype:数组的所需数据类型,可选。
- copy:默认为
True,意味着创建对象的副本。如果设置为False,则尝试使用原始对象。 - order:{'C', 'F', 'A', 'K'},指定数组的内存布局。'C'代表C语言风格,'F'代表Fortran风格,'A'代表'F'如果原数组是Fortran连续的,否则是'C','K'代表尽可能保持原数组的内存布局。
- subok:默认为
False,返回一个基本类型数组。如果为True,则返回子类。 - ndmin:指定返回数组的最小维度。默认是根据列表、元组情况而定
示例
1. 列表转化ndarray对象
import numpy as np list1 = [1, 2, 3, 4] arr1 = np.array(list1) print(arr1) # 输出: [1 2 3 4]

2. 指定数据类型
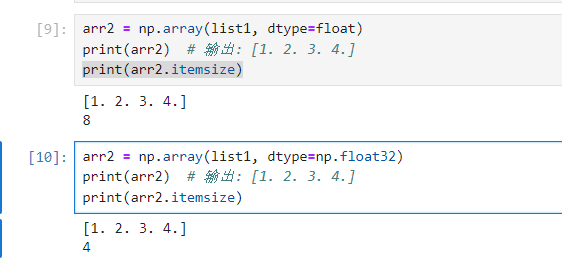
记得有默认值
3. 多维数组

列表有逗号,ndarray没有哦
4. 最小维度

因为指定nmid为2,即使列表是一维也是会转化为2维的
5. 是否copy
list1 = [1, 2, 3, 4, 5]
arr5 = np.array(list1, copy=False)
print(list1)
list1[0] = 10
print(arr5) # 没有影响
print(list1)
print()
list1 = [1, 2, 3, 4, 5]
arr5 = np.array(list1, copy=True)
print(list1)
list1[0] = 10
print(arr5)
print(list1)
print()
arr6 = np.array(arr5, copy=False)
arr5[0] = 88
print(arr5)
print(arr6)
print()
print(arr6)
arr7 = np.array(arr6, copy=True)
arr6[0] = 188
print(arr6)
print(arr7)

从测试结果看,copy属性对列表转ndarray没有影响,ndarry转ndarray有影响
numpy.dtype(obj, align=False, copy=False)
在NumPy中,dtype(数据类型)是一个对象,它描述了数组中元素的数据类型。每个NumPy数组都有一个dtype属性,用于定义其元素的数据类型。dtype不仅包含基本的类型信息(如float、int等),还可以描述更复杂的数据结构,比如结构化数据类型
- obj:用于定义数据类型的对象。可以是字符串、Python类型(如
float)、另一个dtype对象,或者是表示字段的字典或元组列表。 - align:如果为
True,则字段将按C语言结构体的方式进行字节对齐。 - copy:如果为
True,则创建dtype对象的副本。
示例
1. 基本数据类型

2. 使用字符串定义数据类型
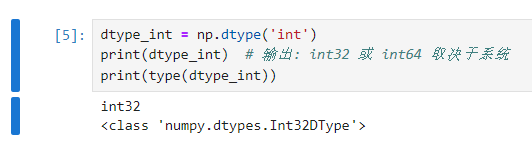
3. 更复杂的结构化数据类型

4.使用元组定义数据类型(带有字段名)

i1表示是1个字节的int
f4表示是4个字节 的float
属性
dtype(数据类型)
1. 布尔型
bool_:布尔值,True 或 False。
2. 整型
int_:默认的整数类型(类似于C中的long;通常是int64或int32)。intc:C语言中的int类型,通常是int32或int64。intp:用于索引的整数类型(类似于C中的ssize_t;通常是int32或int64)。int8,int16,int32,int64:分别代表8位、16位、32位、64位整数。
3. 无符号整型
uint8,uint16,uint32,uint64:分别代表8位、16位、32位、64位无符号整数。
4. 浮点型
float_:默认的浮点类型(类似于C中的double;通常是float64)。float16,float32,float64:分别代表16位、32位、64位浮点数。
5. 复数型
complex_:默认的复数类型(类似于C中的double组成的复数;通常是complex128)。complex64,complex128:分别代表由两个32位浮点数(实部和虚部)和两个64位浮点数组成的复数。
6. 对象类型
object_:表示Python对象类型。这种类型用于存储任意Python对象,但通常在需要数组元素为多种类型或包含复杂对象时使用。
7. 字符串类型
string_:表示固定长度的字符串类型,每个字符占用一个字节。例如,string_[n]表示长度为n的字符串。unicode_:表示固定长度的Unicode类型(在Python 3中,等同于str类型)。例如,unicode_[n]表示长度为n的Unicode字符串。
8. 时间类型
datetime64:表示日期和时间的类型。timedelta64:表示时间差(两个datetime64类型数据之间的差)。
9. 其他类型
bytes_:固定长度的字节序列。void:表示空(无数据)的类型,通常用于表示结构化数组的元素。
import numpy as np # 布尔型 arr_bool = np.array([True, False, True], dtype=np.bool_) print(arr_bool) # 整型 arr_int32 = np.array([1, 2, 3], dtype=np.int32) print(arr_int32) # 无符号整型 arr_uint8 = np.array([1, 2, 3], dtype=np.uint8) print(arr_uint8) # 浮点型 arr_float64 = np.array([1.0, 2.0, 3.0], dtype=np.float64) print(arr_float64) # 复数型 arr_complex128 = np.array([1+2j, 3+4j, 5+6j], dtype=np.complex128) print(arr_complex128) # 对象类型 arr_object = np.array([1, 'a', True], dtype=np.object_) print(arr_object) # 字符串类型 arr_string = np.array(['apple', 'banana', 'cherry'], dtype=np.string_) print(arr_string) # Unicode类型 arr_unicode = np.array(['apple', 'banana', 'cherry'], dtype=np.unicode_) print(arr_unicode) # 时间类型 arr_datetime = np.array(['2021-01-01', '2021-01-02'], dtype='datetime64') print(arr_datetime) # 时间差类型 arr_timedelta = np.array([np.datetime64('2021-01-01') - np.datetime64('2020-01-01')], dtype='timedelta64') print(arr_timedelta) # 字节类型 arr_bytes = np.array([b'abc', b'def'], dtype=np.bytes_) print(arr_bytes) # 创建结构化数组 arr_void = np.array([(1, 'a', 0.5)], dtype=[('x', 'i4'), ('y', 'S1'), ('z', 'f4')]) print(arr_void)

- 明确地指定
dtype可以确保数据的一致性和预期行为,尤其是在涉及数值计算时。 - 选择合适的
dtype以优化性能和内存使用。例如,对于只需要小整数的情况,使用int8或uint8比默认的int64更节省内存。 - 对于复杂计算,使用高精度的数据类型(如
float64或complex128)以提高计算精度,但需注意这会增加内存消耗。 - 当处理大型数据集时,合理选择数据类型对于内存管理和性能优化至关重要
- 使用
object_类型时需谨慎,因为它会牺牲NumPy数组的许多优点,如高效的内存使用和快速的数学运算。 - 对于文本数据,明确区分
string_和unicode_类型,特别是在处理非英文字符时。 - 日期和时间数据类型,如
datetime64和timedelta64,非常适合处理时间序列数据。
ndarray
函数
reshap
语法
numpy.reshape(a, newshape, order='C')
a: 要重塑形状的输入数组。newshape: 一个整数元组或整数列表,表示新的形状。元组中的元素表示每个维度的大小。order(可选参数):可选值为 'C'(默认值)和 'F',表示按照 C 或 Fortran 内存顺序进行数组重塑
示例
import numpy as np # 创建一个初始数组 2*3 original_array = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 reshape 改变数组形状 reshaped_array = np.reshape(original_array, (3, 2)) print(reshaped_array)
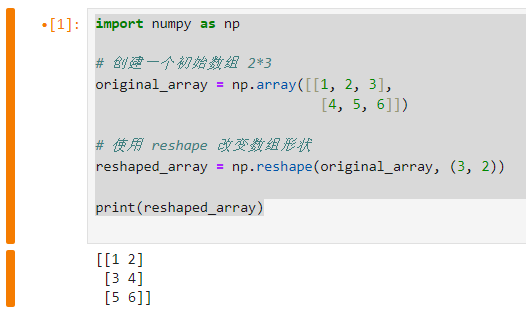
相关的ndarray属性是shape属性


最佳实践:
-
确保新形状的总元素数量与原始数组相同。例如,一个有 6 个元素的一维数组可以重塑为一个形状为 (2, 3) 的二维数组,但不能重塑为 (3, 3)。
-
尽量避免在高维度数组上进行 reshape 操作,因为它可能会导致混淆和错误。
-
当需要更改数组形状时,确保使用合适的数值来定义新形状,以便数据不会丢失或混淆。
-
如果你不确定使用 'C' 还是 'F' 作为 order 参数,通常使用默认值 'C' 就可以满足大多数需求。
-
请注意,
reshape返回一个新的数组,原始数组不会被修改。如果需要在原地修改数组的形状,可以使用resize函数。
sum函数
用于计算数组的元素和
语法
numpy.ndarray.sum(axis=None, dtype=None, out=None, keepdims=False, initial=0)
axis(可选参数):指定在哪个轴上进行求和操作。默认值为None,表示对整个数组进行求和。如果提供了轴参数,它应该是一个整数或整数元组,用于指定沿哪些轴进行求和。例如,axis=0表示在第一个维度(列)上进行求和,axis=1表示在第二个维度(行)上进行求和。dtype(可选参数):指定输出的数据类型。默认值为None,表示保持输入数组的数据类型。out(可选参数):用于存储结果的可选输出数组。keepdims(可选参数):如果设置为True,则在结果中保留轴的尺寸。默认值为False。initial(可选参数):初始累积值,如果提供了这个参数,将会在开始时添加到结果中。
示例
import numpy as np # 创建一个示例数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 求整个数组的元素和 total_sum = arr.sum() print("总和:", total_sum) # 沿着不同的轴求和 sum_axis_0 = arr.sum(axis=0) # 沿着第一个维度(列)求和 sum_axis_1 = arr.sum(axis=1) # 沿着第二个维度(行)求和 print("按列求和:", sum_axis_0) print("按行求和:", sum_axis_1) # 指定数据类型 sum_float = arr.sum(dtype=float) # 指定结果的数据类型为浮点数 print("浮点数总和:", sum_float) # 保持轴的尺寸 sum_with_dims = arr.sum(axis=0, keepdims=True) print("按列求和并保持尺寸:") print(sum_with_dims) # 因为是二维数组,结果还是二维数组 # 指定初始累积值 sum_with_initial = arr.sum(initial=10) # 即10 + 数组元素的和 print("带初始累积值的总和:", sum_with_initial)

import numpy as np # 创建一个示例数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 创建一个空的输出数组,用于存储结果 output_array = np.zeros((3,)) # 一个形状为 (3,) 的一维数组 # 使用 out 参数来计算并存储结果 arr.sum(axis=1, out=output_array) print("原始数组:") print(arr) print("计算结果存储在输出数组中:") print(output_array)

最佳实践
最佳实践是根据问题的要求选择适当的参数,确保结果正确并高效。
mean
计算数组元素的平均值。
语法
numpy.ndarray.mean(axis=None, dtype=None, out=None, keepdims=False)
axis(可选参数):指定在哪个轴上进行平均值计算。默认值为None,表示对整个数组进行平均值计算。如果提供了轴参数,它应该是一个整数或整数元组,用于指定沿哪些轴进行平均值计算。例如,axis=0表示在第一个维度(列)上进行平均值计算,axis=1表示在第二个维度(行)上进行平均值计算。dtype(可选参数):指定输出的数据类型。默认值为None,表示保持输入数组的数据类型。out(可选参数):用于存储结果的可选输出数组。keepdims(可选参数):如果设置为True,则在结果中保留轴的尺寸。默认值为False。
示例
import numpy as np # 创建一个示例数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 计算整个数组的平均值 average = arr.mean() print("整个数组的平均值:", average) # 沿着不同的轴计算平均值 average_axis_0 = arr.mean(axis=0) # 沿着第一个维度(列)计算平均值 average_axis_1 = arr.mean(axis=1) # 沿着第二个维度(行)计算平均值 print("按列计算平均值:", average_axis_0) print("按行计算平均值:", average_axis_1) # 指定数据类型 average_float = arr.mean(dtype=float) # 指定结果的数据类型为浮点数 print("浮点数平均值:", average_float) # 保持轴的尺寸 average_with_dims = arr.mean(axis=0, keepdims=True) print("按列计算平均值并保持尺寸:") print(average_with_dims)

最佳实践
最佳实践是根据问题需求选择适当的参数,以确保结果正确并高效。
使用 mean 函数来计算数组的平均值,并且通过不同的参数设置来控制平均值的计算行为。
根据问题的要求,可以选择不同的轴、数据类型和是否保持轴尺寸来定制平均值计算。
std
计算数组元素的标准差。
语法
numpy.ndarray.std(axis=None, dtype=None, out=None, ddof=0, keepdims=False)
axis(可选参数):指定在哪个轴上进行标准差计算。默认值为None,表示对整个数组进行标准差计算。如果提供了轴参数,它应该是一个整数或整数元组,用于指定沿哪些轴进行标准差计算。例如,axis=0表示在第一个维度(列)上进行标准差计算,axis=1表示在第二个维度(行)上进行标准差计算。dtype(可选参数):指定输出的数据类型。默认值为None,表示保持输入数组的数据类型。out(可选参数):用于存储结果的可选输出数组。ddof(可选参数):自由度的参数,通常为 0。默认情况下,使用样本标准差的公式计算,此时ddof=0。如果将ddof设置为 1,则使用总体标准差的公式进行计算。keepdims(可选参数):如果设置为True,则在结果中保留轴的尺寸。默认值为False。
示例
import numpy as np # 创建一个示例数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 计算整个数组的标准差 std_deviation = arr.std() print("整个数组的标准差:", std_deviation) # 沿着不同的轴计算标准差 std_deviation_axis_0 = arr.std(axis=0) # 沿着第一个维度(列)计算标准差 std_deviation_axis_1 = arr.std(axis=1) # 沿着第二个维度(行)计算标准差 print("按列计算标准差:", std_deviation_axis_0) print("按行计算标准差:", std_deviation_axis_1) # 指定数据类型 std_deviation_float = arr.std(dtype=float) # 指定结果的数据类型为浮点数 print("浮点数标准差:", std_deviation_float) # 自由度参数设置 std_deviation_ddof = arr.std(ddof=1) # 使用总体标准差的公式计算 print("总体标准差:", std_deviation_ddof) # 保持轴的尺寸 std_deviation_with_dims = arr.std(axis=0, keepdims=True) print("按列计算标准差并保持尺寸:") print(std_deviation_with_dims)

最佳实践
最佳实践是根据问题需求选择适当的参数,以确保结果正确并高效。
使用 std 函数来计算数组的标准差,并通过不同的参数设置来控制标准差计算的行为。
根据问题的要求,你可以选择不同的轴、数据类型、自由度参数和是否保持轴尺寸来定制标准差计算。
dot
dot 方法用于计算两个数组的点积(内积)。点积是一种矩阵运算,通常用于矩阵乘法。
语法
numpy.ndarray.dot(b, out=None)
b:另一个数组,与当前数组进行点积计算。out(可选参数):用于存储结果的可选输出数组。
示例
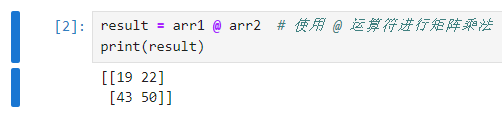
import numpy as np # 创建示例数组 arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6], [7, 8]]) # 使用 dot 方法计算点积 result = arr1.dot(arr2) print("arr1:") print(arr1) print("arr2:") print(arr2) print("点积结果:") print(result)

19 = 1*5 + 2 * 7
22=1 * 6 + 2 * 8
43=3*5 + 4 * 7
50=3*6 + 4*8
最佳实践
-
请确保要点积的两个数组的维度和形状是兼容的。对于矩阵乘法,第一个矩阵的列数必须等于第二个矩阵的行数。
-
如果需要执行矩阵乘法操作,通常使用
dot方法是一个不错的选择,因为它会执行正确的矩阵乘法运算,而不仅仅是元素级的乘法。 -
可以通过使用
@运算符来替代dot方法进行矩阵乘法,它在NumPy中也是支持的,更加直观易读。
属性
shape---形状
获取ndarray的形状,返回是一个元组(x,)一维数组,长度是x,(x,y)二维数组,x行长,y列长
shape 属性是一个元组,包含了数组的维度信息。元组的长度表示数组的维度数,而每个元素表示对应维度的大小。
import numpy as np # 创建示例数组 arr1d = np.array([1, 2, 3, 4, 5]) arr2d = np.array([[1, 2, 3], [4, 5, 6]]) arr3d = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) # 访问数组的 shape 属性 shape1d = arr1d.shape shape2d = arr2d.shape shape3d = arr3d.shape print("一维数组的 shape:", shape1d) print("二维数组的 shape:", shape2d) print("三维数组的 shape:", shape3d)

对于一维数组,shape 是一个包含一个元素的元组 (5,),表示数组有一个维度,且大小为 5。
对于二维数组,shape 是 (2, 3),表示数组有两个维度,分别为 2 行和 3 列。
对于三维数组,shape 是 (2, 2, 2),表示数组有三个维度,每个维度的大小分别为 2、2 和 2。
dtype--数组元素的类型
数组元素的数据类型。
dtype 属性是一个字符串,表示数组中元素的数据类型。NumPy支持多种数据类型,例如:
int32: 32位整数float64: 64位浮点数complex128: 128位复数bool: 布尔类型str: 字符串类型- 等等
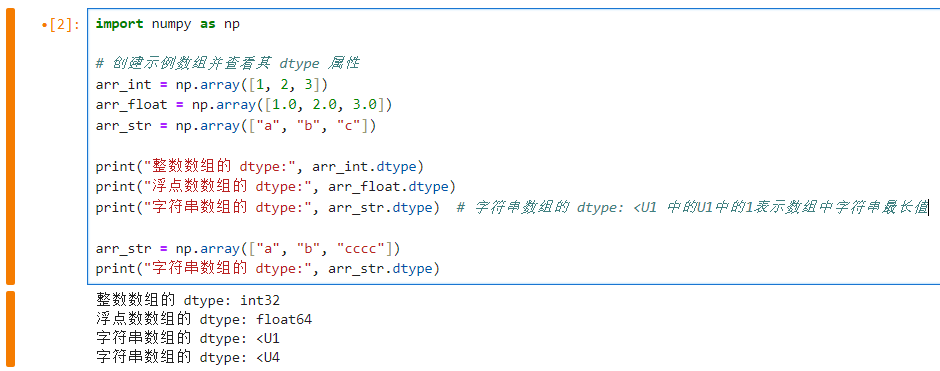
我们创建了三个不同数据类型的数组,并使用 dtype 属性查看它们的数据类型。arr_int 的数据类型是 int32,表示它包含 64 位整数。arr_float 的数据类型是 float64,表示它包含 64 位浮点数。arr_str 的数据类型是 <U1,表示它包含 Unicode 字符串,每个字符串只有一个字符。
最佳实践
-
在创建数组时,尽量指定合适的数据类型,以便有效地使用内存和提高性能。如果不指定数据类型,NumPy会根据输入数据自动推断数据类型,但这可能会导致意外的结果。
-
使用
dtype属性来检查数组的数据类型,以确保它与你的预期一致。 -
可以使用
astype()方法来更改数组的数据类型,例如将整数数组转换为浮点数数组或反之。
arr = np.array([1, 2, 3]) float_arr = arr.astype(np.float64) # 将整数数组转换为浮点数数组
int32_arr = np.array([2**31 - 1, 2**31 - 1]) # 使用 int32 类型 int64_arr = np.array([2**63 - 1, 2**63 - 1]) # 使用 int64 类型
size
用于返回数组中的元素总数,即数组的大小。该属性表示数组中包含的元素数量,包括所有维度。
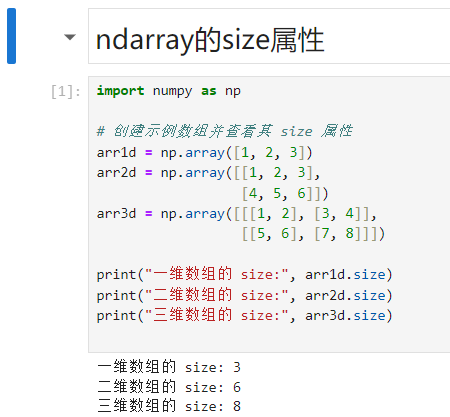
arr1d 包含 3 个元素,因此其 size 属性为 3。arr2d 包含 6 个元素,因此其 size 属性为 6。arr3d 包含 8 个元素,因此其 size 属性为 8。
size 属性通常用于确定数组中有多少个元素,这在处理数组时非常有用。它也有助于检查数组是否为空(size == 0)或是否包含足够的元素来满足特定需求。
ndim
用于返回数组的维度(也称为轴的数量)。ndim 属性返回一个整数,表示数组有多少个维度。
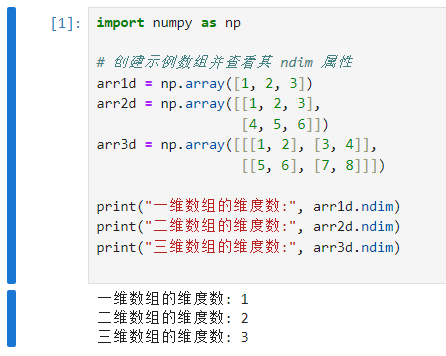
arr1d 是一个一维数组,因此其 ndim 属性为 1。
arr2d 是一个二维数组,因此其 ndim 属性为 2。
arr3d 是一个三维数组,因此其 ndim 属性为 3。
ndim 属性通常用于确定数组的维度,这在处理多维数据时非常有用。根据维度的数量,你可以执行不同类型的操作和处理不同类型的数据。
T--数组的转置
用于返回数组的转置,即将数组的行和列进行互换。T 是数组的一个属性,而不是方法,因此不需要使用括号来调用它。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号