人工智能概述之05机器学习算法分类
算法分类
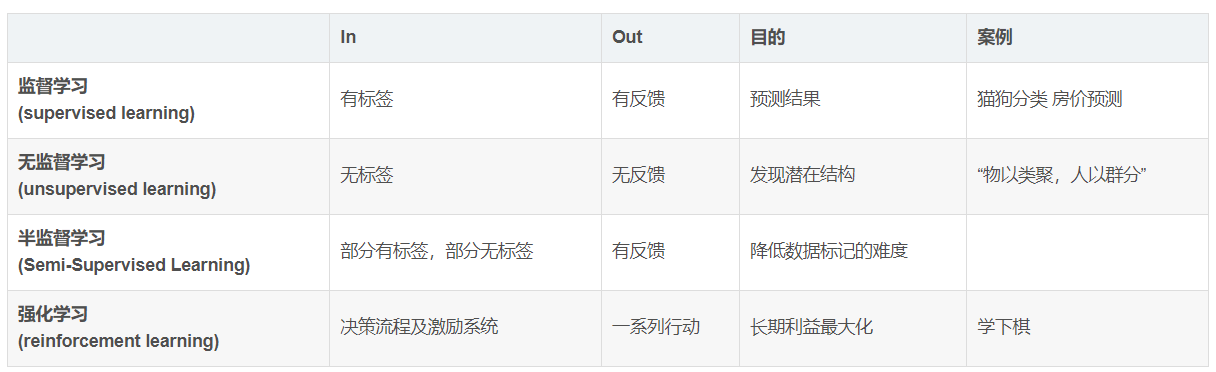
根据数据集组成不同,可以把机器学习算法分为:
-
监督学习(Supervised Learning):
- 定义: 算法从标记好的训练数据中学习,其中每个训练样本都包含输入和相应的输出标签。
- 应用: 用于分类和回归问题,例如图像分类、语音识别、房价预测等。
- 示例:
- 分类问题:手写数字识别,垃圾邮件分类。
- 回归问题:房价预测,销售预测。
- 最佳实践:
- 确保训练集和测试集的标签都是正确的。
- 选择适当的性能指标,如准确性、精确度、召回率等。
-
无监督学习(Unsupervised Learning):
- 定义: 算法从未标记的数据中学习,没有明确的输出标签。其目标通常是发现数据的结构或模式。
- 应用: 用于聚类、降维、关联规则挖掘等,例如聚类相似文档、降低数据维度、发现关联规律等。
- 示例:
- 聚类:客户分群,新闻主题聚类。
- 降维:图像压缩,特征提取。
- 最佳实践:
- 选择合适的聚类算法或降维技术。
- 调查和理解无监督学习模型输出的结果
-
半监督学习(Semi-supervised Learning):
- 定义: 这是监督学习和无监督学习的结合,其中模型使用标记和未标记的数据进行训练。
- 应用: 适用于标记数据不充分的情况,通过结合未标记数据来提高模型性能。
- 示例:
- 文本分类,其中只有一小部分文档进行了标记
- 最佳实践:
- 确保未标记数据的质量。
- 使用标记数据来引导模型的学习。
-
强化学习(Reinforcement Learning):
- 定义: 算法通过与环境的交互学习,根据其行动的反馈获得奖励或惩罚。
- 应用: 用于决策问题,例如游戏玩家的训练、机器人控制等。
- 最佳实践:
- 设定适当的奖励和惩罚机制。
- 平衡探索(exploration)和利用(exploitation)的权衡。
- 示例:
- 游戏玩家(例如AlphaGo)。
- 机器人控制,自动驾驶车辆
-
自监督学习(Self-supervised Learning):
- 定义: 模型从输入数据中学习,而不需要显式的标签。通常,模型通过自己生成标签或任务来学习。
- 应用: 用于图像、文本等领域,例如图像生成、文本补全等。
这些类型并不是孤立的,有时候算法可以同时使用多种学习方式。例如,半监督学习可以结合监督和无监督学习,提高模型的泛化能力
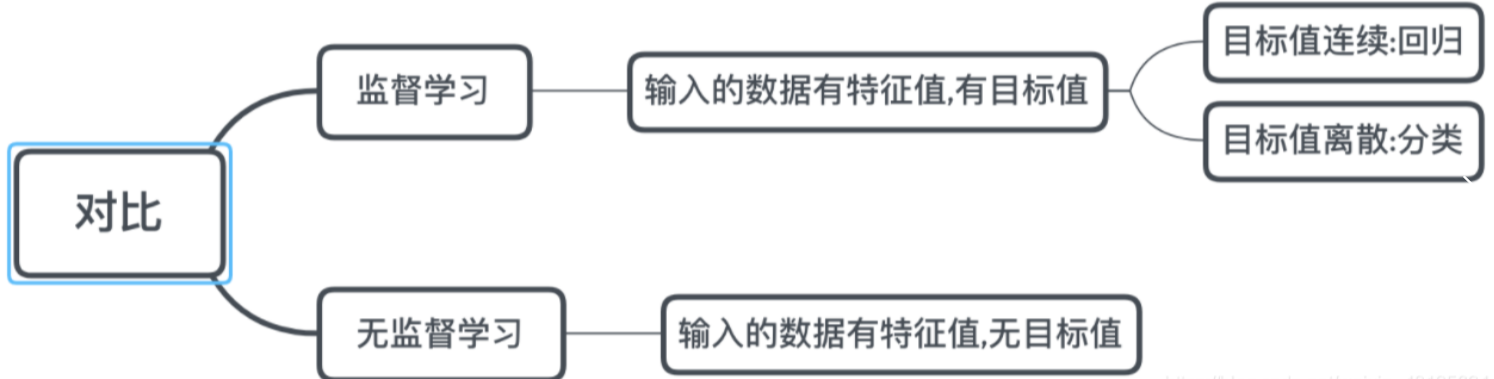
监督学习:
- 输入数据是由输入特征值和目标值所组成。
- 函数的输出可以是一个连续的值(称为回归),
- 或是输出是有限个离散值(称作分类)。
无监督学习
-
输入数据是由输入特征值组成,没有目标值
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知;
- 需要根据样本间的相似性对样本集进行类别划分
半监督学习
- 训练集同时包含有标记样本数据和未标记样本数据。
强化学习
- 实质是make decisions 问题,即自动进行决策,并且可以做连续决策。
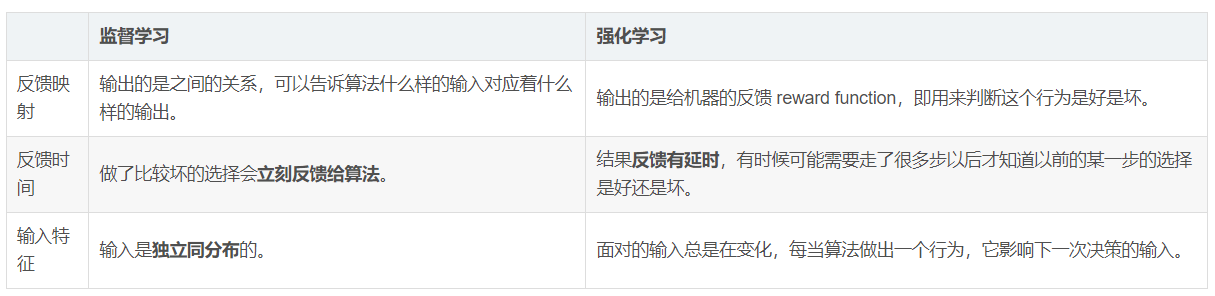
监督学习和强化学习的对比:
什么是独立同分布:https://blog.csdn.net/weixin_48135624/article/details/114907388
常见的算法简介
-
线性回归(Linear Regression):
- 描述: 用于建立输入特征与输出目标之间的线性关系。
- 示例: 预测房价,基于房屋面积、卧室数量等特征。
-
逻辑回归(Logistic Regression):
- 描述: 用于处理二分类问题,通过 S 形曲线将输入映射到 0 到 1 之间的概率。
- 示例: 预测邮件是垃圾邮件(1)还是非垃圾邮件(0)。
-
决策树(Decision Trees):
- 描述: 基于特征的条件进行决策,树形结构。
- 示例: 根据天气条件(阳光、多云、雨)预测是否会下雨。
-
支持向量机(Support Vector Machines,SVM):
- 描述: 用于分类和回归任务,通过找到将数据划分为两个类别的最优超平面。
- 示例: 图像分类,将图像分为不同的类别。
-
聚类算法 - K均值聚类(K-Means Clustering):
- 描述: 将数据集分为 k 个簇,使得每个数据点属于离其最近的簇。
- 示例: 客户分群,根据购买行为将客户分为不同的群体。
-
朴素贝叶斯(Naive Bayes):
- 描述: 基于贝叶斯定理,处理分类问题,特征之间假设独立。
- 示例: 垃圾邮件过滤,根据词汇判断邮件是否为垃圾邮件。
-
神经网络(Neural Networks):
- 描述: 模拟人脑神经元的网络结构,通过层次化学习来建立模型。
- 示例: 图像识别,语音识别,自然语言处理等。
-
随机森林(Random Forest):
- 描述: 由多个决策树组成的集成学习模型,通过投票来进行预测。
- 示例: 随机森林可以用于预测疾病风险,根据多个决策树的结果进行综合评估。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号