


翻阅相关文档,说 Elasitcsearch searchAfter 是一个轻量的分页工具,那么它是如何实现的呢,使用时有哪些需要注意?
如下给出了一个 searchAfter 的使用示例,在第一次搜索时,searchAfter 不需要设置,查询结果的最后一个文档排序的字段值,作为下一次查询的 searchAfter 参数值。
POST /index_name/_search { "query": { "match_all": {} }, "sort": [{"created_at": "asc"}], //或其他你选择的排序字段及顺序 "size": 3, "search_after": [1704412800000] //这里替换为上一次查询返回的最后一项的排序值,例如时间戳 }
假定索引中添加了 6 个文档,其排序字段分别为 [1,2,3,3,4,5],页大小设置为 3,使用 searchAfter 进行分页查询,则会漏掉数据:第一页 [1, 2, 3],第二页[4,5]。所以使用 searchAfter 时,排序字段需要有较好的唯一性,很多示例使用 _id 字段,但 indices.id_field_data.enabled 是默认关闭的,所以本文也不建议使用该字段。
其背后的原理是怎样的,相比于另一个 scroll api,它是实时的,这是为何?
// org.elasticsearch.search.query.QueryPhase#searchWithCollector private static boolean searchWithCollector( SearchContext searchContext, ContextIndexSearcher searcher, Query query, LinkedList<QueryCollectorContext> collectors, boolean hasFilterCollector, boolean timeoutSet ) throws IOException { // create the top docs collector last when the other collectors are known final TopDocsCollectorContext topDocsFactory = createTopDocsCollectorContext(searchContext, hasFilterCollector); // add the top docs collector, the first collector context in the chain collectors.addFirst(topDocsFactory); final Collector queryCollector; if (searchContext.getProfilers() != null) { InternalProfileCollector profileCollector = QueryCollectorContext.createQueryCollectorWithProfiler(collectors); searchContext.getProfilers().getCurrentQueryProfiler().setCollector(profileCollector); queryCollector = profileCollector; } else { queryCollector = QueryCollectorContext.createQueryCollector(collectors); } QuerySearchResult queryResult = searchContext.queryResult(); try { searcher.search(query, queryCollector); } catch (EarlyTerminatingCollector.EarlyTerminationException e) { queryResult.terminatedEarly(true); } catch (TimeExceededException e) { assert timeoutSet : "TimeExceededException thrown even though timeout wasn't set"; if (searchContext.request().allowPartialSearchResults() == false) { // Can't rethrow TimeExceededException because not serializable throw new QueryPhaseExecutionException(searchContext.shardTarget(), "Time exceeded"); } queryResult.searchTimedOut(true); } if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER && queryResult.terminatedEarly() == null) { queryResult.terminatedEarly(false); } for (QueryCollectorContext ctx : collectors) { ctx.postProcess(queryResult); } return topDocsFactory.shouldRescore(); }
在执行查询前创建 SimpleTopDocsCollectorContext 对象,该对象最终影响 lucene 收集搜索结果中的匹配文档。
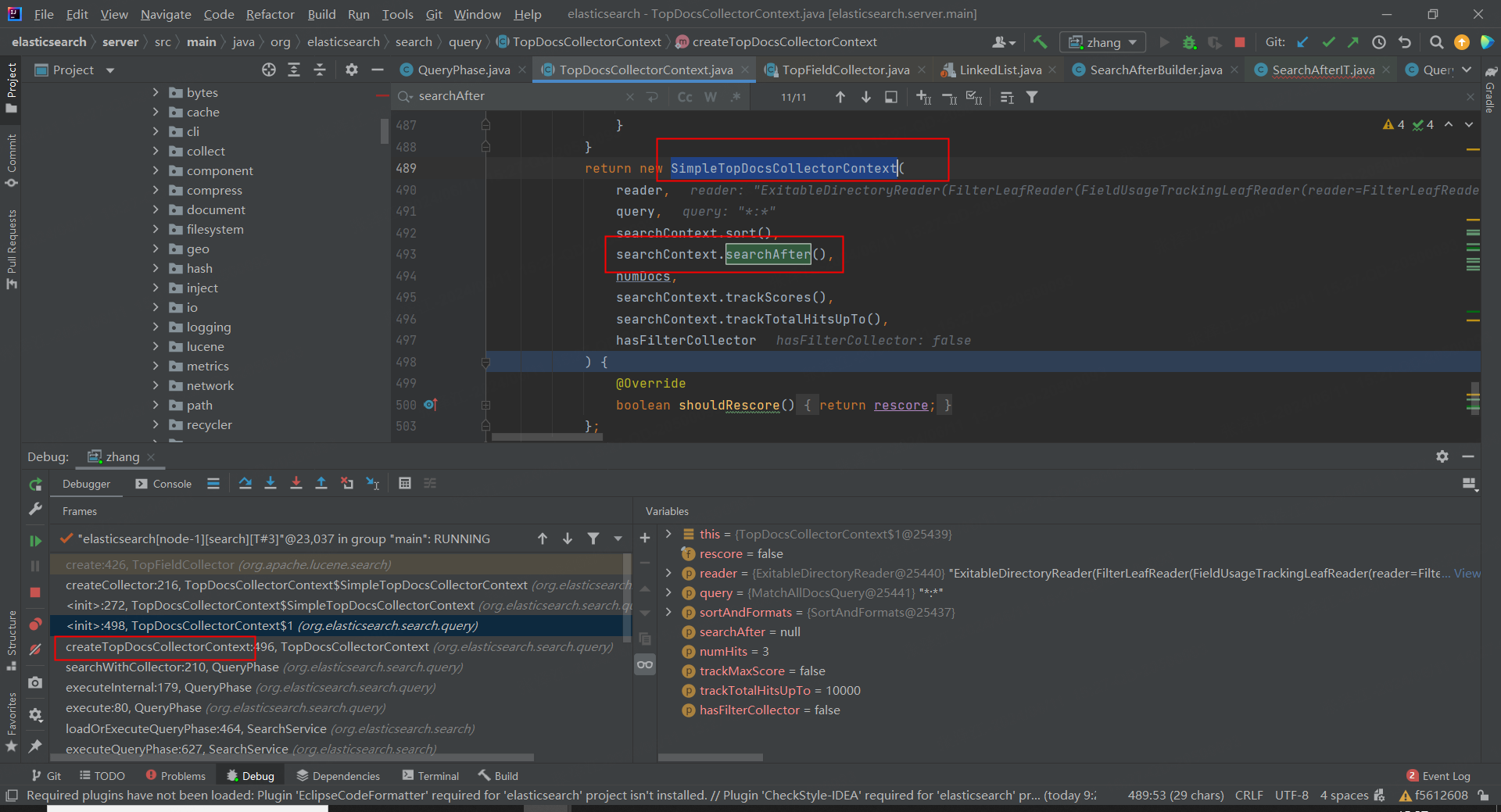
执行查询时,根据 after 参数进行过滤。
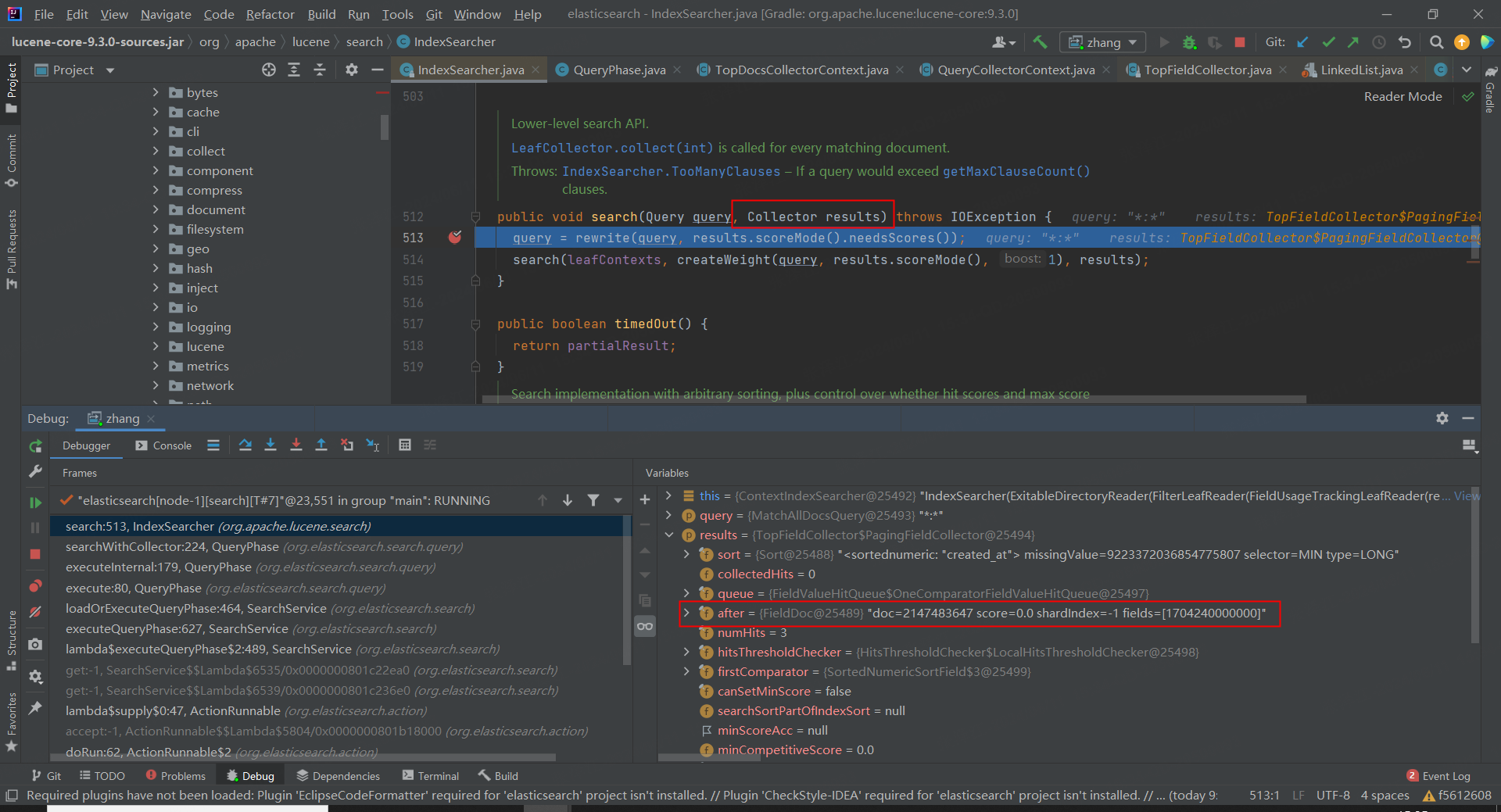
携带 searchAfter 参数的查询和普通的查询原理基本上是相同的,普通查询是近实时的,那么 searchAfter 也是近实时的,每次查询时创建新的 DirectoryReader 对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号