
我们都知道 elastic search 是近实时的搜索系统,这里面的原因究竟是什么呢?es 是近实时,是因为 lucene 是近实时的。我们看一段 lucene 的示例代码:
使用的 lucene 版本如下:
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>8.9.0</version> </dependency>
1 Analyzer analyzer = new StandardAnalyzer(); 2 3 Path indexPath = new File("tmp_index").toPath(); 4 IOUtils.rm(indexPath); 5 Directory directory = FSDirectory.open(indexPath); 6 IndexWriterConfig config = new IndexWriterConfig(analyzer); 7 // 使用 compound file 8 config.setUseCompoundFile(true); 9 // config.setInfoStream(System.out); 10 IndexWriter iw = new IndexWriter(directory, config); 11 // Now search the index: 12 StandardDirectoryReader oldReader = (StandardDirectoryReader) DirectoryReader.open(iw); 13 14 // 添加文档 1 15 Document doc = new Document(); 16 doc.add(new Field("name", "Pride and Prejudice", TextField.TYPE_STORED)); 17 doc.add(new Field("line", "It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.", TextField.TYPE_STORED)); 18 doc.add(new Field("chapters", "1", TextField.TYPE_STORED)); 19 iw.addDocument(doc); 20 21 IndexSearcher searcher = new IndexSearcher(oldReader); 22 // Parse a simple query that searches for "text": 23 QueryParser parser = new QueryParser("name", analyzer); 24 Query query = parser.parse("prejudice"); 25 ScoreDoc[] hits = searcher.search(query, 10).scoreDocs; 26 // Iterate through the results: 27 System.out.println("第一次查询:"); 28 System.out.printf("version=%d, segmentInfos=%s\n", oldReader.getVersion(), 29 oldReader.getSegmentInfos()); 30 for (int i = 0; i < hits.length; i++) { 31 System.out.println(hits[i]); 32 } 33 34 StandardDirectoryReader newReader = (StandardDirectoryReader) DirectoryReader.openIfChanged(oldReader); 35 oldReader.close(); 36 37 searcher = new IndexSearcher(newReader); 38 hits = searcher.search(query, 10).scoreDocs; 39 System.out.println("第二次查询:"); 40 System.out.printf("version=%d, segmentInfos=%s\n", newReader.getVersion(), 41 newReader.getSegmentInfos()); 42 // Iterate through the results: 43 for (int i = 0; i < hits.length; i++) { 44 System.out.println(hits[i]); 45 } 46 47 iw.commit(); 48 newReader.close(); 49 directory.close();
在第 15 行处,添加一个文档,然后执行搜索,并没有查询到文档。
在第 34 行处,调用 DirectoryReader.openIfChanged 方法,然后使用新的 reader 执行搜索,则可以查询到文档,注意此时文档仍然没有 flush 到磁盘中。
在第 47 行处,调用 IndexWriter.commit 方法,执行 flush 写盘。
OK ,现在看到了近实时的现象,对应到 ES 中的操作,在 ES 中写入一个文档,如同 15 行的操作,写入并不是立即可见;
需要执行 refresh,对应到第 24 行代码的 openIfChanged 方法;
ES 执行 flush 则对应到第 47 行的 IndexWriter.commit 方法。
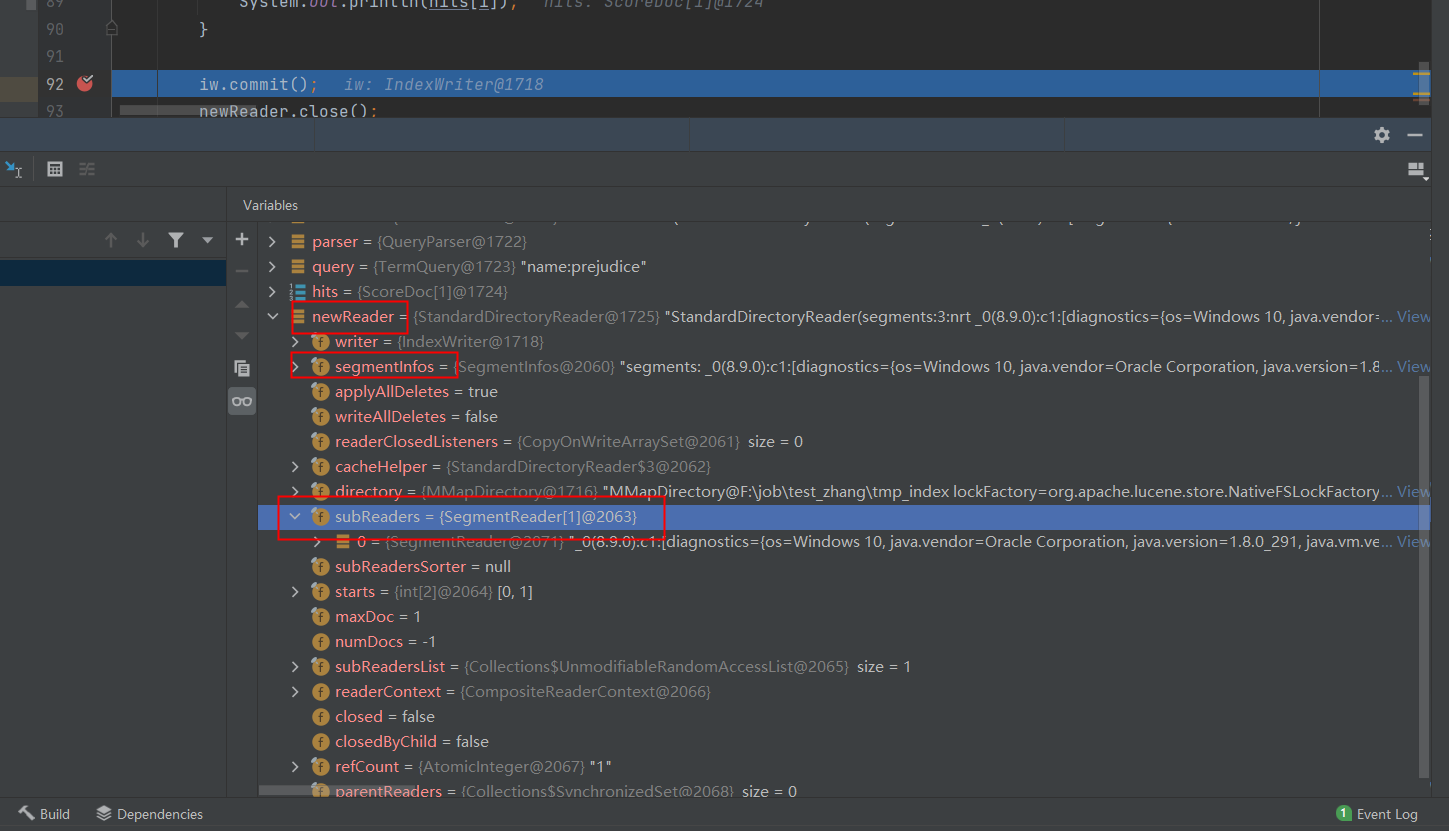
针对网上所说的,ES 每次 refresh 之后都会生成一个 segment,看看 debug 截图:
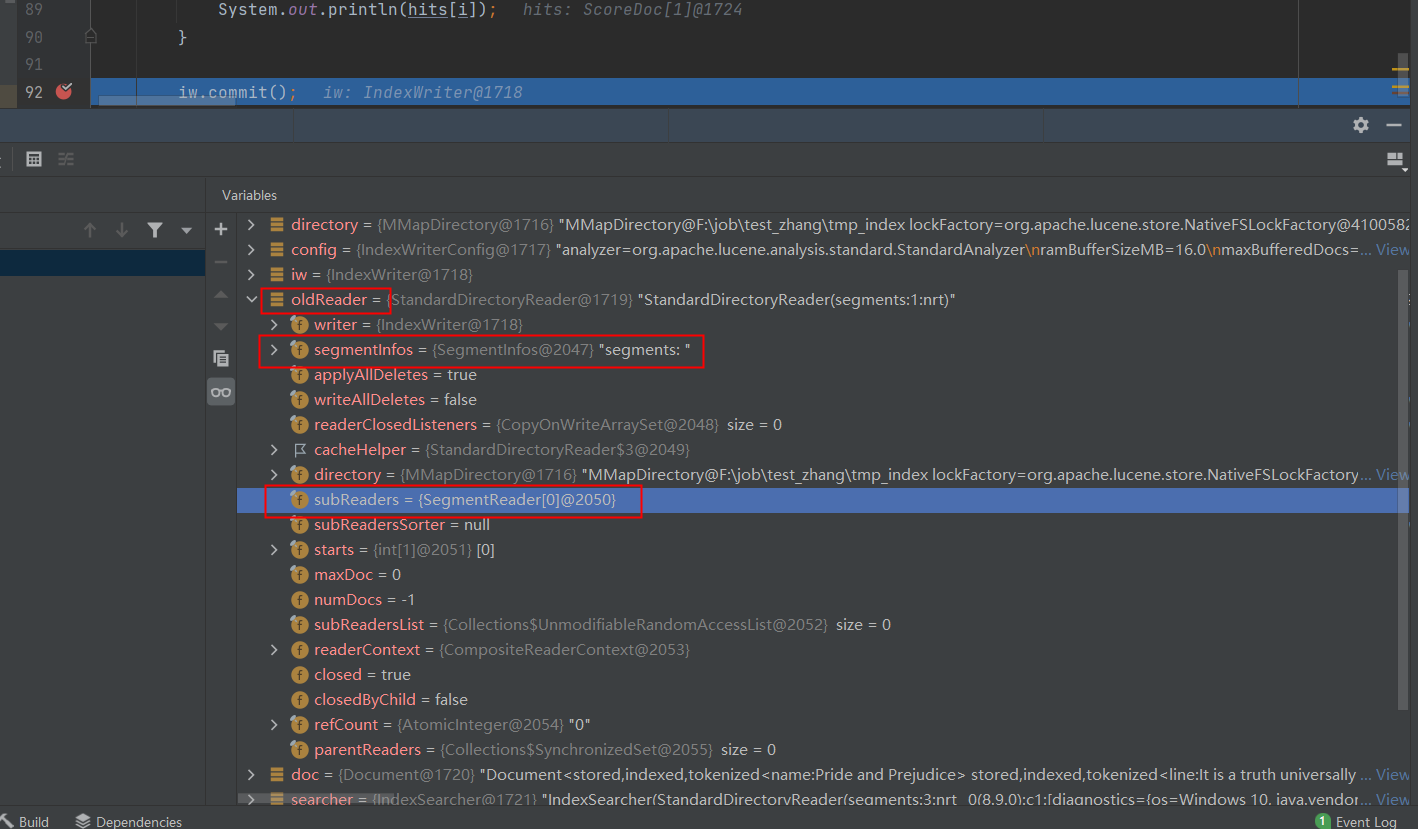
openIfChanged 之后确实生成了一个 SegmentReader
附加2个小问题:1. 当不指定文档ID时,这个ID是如何生成的?ES确实有一个算法
// org.elasticsearch.common.TimeBasedUUIDGenerator#getBase64UUID public String getBase64UUID() { final int sequenceId = sequenceNumber.incrementAndGet() & 0xffffff; long currentTimeMillis = currentTimeMillis(); long timestamp = this.lastTimestamp.updateAndGet(lastTimestamp -> { // Don't let timestamp go backwards, at least "on our watch" (while this JVM is running). We are // still vulnerable if we are shut down, clock goes backwards, and we restart... for this we // randomize the sequenceNumber on init to decrease chance of collision: long nonBackwardsTimestamp = Math.max(lastTimestamp, currentTimeMillis); if (sequenceId == 0) { // Always force the clock to increment whenever sequence number is 0, in case we have a long // time-slip backwards: nonBackwardsTimestamp++; } return nonBackwardsTimestamp; }); final byte[] uuidBytes = new byte[15]; int i = 0; // We have auto-generated ids, which are usually used for append-only workloads. // So we try to optimize the order of bytes for indexing speed (by having quite // unique bytes close to the beginning of the ids so that sorting is fast) and // compression (by making sure we share common prefixes between enough ids), // but not necessarily for lookup speed (by having the leading bytes identify // segments whenever possible) // Blocks in the block tree have between 25 and 48 terms. So all prefixes that // are shared by ~30 terms should be well compressed. I first tried putting the // two lower bytes of the sequence id in the beginning of the id, but compression // is only triggered when you have at least 30*2^16 ~= 2M documents in a segment, // which is already quite large. So instead, we are putting the 1st and 3rd byte // of the sequence number so that compression starts to be triggered with smaller // segment sizes and still gives pretty good indexing speed. We use the sequenceId // rather than the timestamp because the distribution of the timestamp depends too // much on the indexing rate, so it is less reliable. uuidBytes[i++] = (byte) sequenceId; // changes every 65k docs, so potentially every second if you have a steady indexing rate uuidBytes[i++] = (byte) (sequenceId >>> 16); // Now we start focusing on compression and put bytes that should not change too often. uuidBytes[i++] = (byte) (timestamp >>> 16); // changes every ~65 secs uuidBytes[i++] = (byte) (timestamp >>> 24); // changes every ~4.5h uuidBytes[i++] = (byte) (timestamp >>> 32); // changes every ~50 days uuidBytes[i++] = (byte) (timestamp >>> 40); // changes every 35 years byte[] macAddress = macAddress(); assert macAddress.length == 6; System.arraycopy(macAddress, 0, uuidBytes, i, macAddress.length); i += macAddress.length; // Finally we put the remaining bytes, which will likely not be compressed at all. uuidBytes[i++] = (byte) (timestamp >>> 8); uuidBytes[i++] = (byte) (sequenceId >>> 8); uuidBytes[i++] = (byte) timestamp; assert i == uuidBytes.length; return Base64.getUrlEncoder().withoutPadding().encodeToString(uuidBytes); }
2. 网上传言当 index buffer 满时,会触发 refresh 的动作,判断 buffer 是否满,这个参数到底是啥
/** * Determines the amount of RAM that may be used for buffering added documents * and deletions before they are flushed to the Directory. Generally for * faster indexing performance it's best to flush by RAM usage instead of * document count and use as large a RAM buffer as you can. * <p> * When this is set, the writer will flush whenever buffered documents and * deletions use this much RAM. Pass in * {@link IndexWriterConfig#DISABLE_AUTO_FLUSH} to prevent triggering a flush * due to RAM usage. Note that if flushing by document count is also enabled, * then the flush will be triggered by whichever comes first. * <p> * The maximum RAM limit is inherently determined by the JVMs available * memory. Yet, an {@link IndexWriter} session can consume a significantly * larger amount of memory than the given RAM limit since this limit is just * an indicator when to flush memory resident documents to the Directory. * Flushes are likely happen concurrently while other threads adding documents * to the writer. For application stability the available memory in the JVM * should be significantly larger than the RAM buffer used for indexing. * <p> * <b>NOTE</b>: the account of RAM usage for pending deletions is only * approximate. Specifically, if you delete by Query, Lucene currently has no * way to measure the RAM usage of individual Queries so the accounting will * under-estimate and you should compensate by either calling commit() or refresh() * periodically yourself. * <p> * <b>NOTE</b>: It's not guaranteed that all memory resident documents are * flushed once this limit is exceeded. Depending on the configured * {@link FlushPolicy} only a subset of the buffered documents are flushed and * therefore only parts of the RAM buffer is released. * <p> * * The default value is {@link IndexWriterConfig#DEFAULT_RAM_BUFFER_SIZE_MB}. * * <p> * Takes effect immediately, but only the next time a document is added, * updated or deleted. * * @see IndexWriterConfig#setRAMPerThreadHardLimitMB(int) * * @throws IllegalArgumentException * if ramBufferSize is enabled but non-positive, or it disables * ramBufferSize when maxBufferedDocs is already disabled */ public synchronized LiveIndexWriterConfig setRAMBufferSizeMB(double ramBufferSizeMB) { if (ramBufferSizeMB != IndexWriterConfig.DISABLE_AUTO_FLUSH && ramBufferSizeMB <= 0.0) { throw new IllegalArgumentException("ramBufferSize should be > 0.0 MB when enabled"); } if (ramBufferSizeMB == IndexWriterConfig.DISABLE_AUTO_FLUSH && maxBufferedDocs == IndexWriterConfig.DISABLE_AUTO_FLUSH) { throw new IllegalArgumentException("at least one of ramBufferSize and maxBufferedDocs must be enabled"); } this.ramBufferSizeMB = ramBufferSizeMB; return this; }
该参数默认是 16 MB
// org.apache.lucene.index.IndexWriterConfig public static final double DEFAULT_RAM_BUFFER_SIZE_MB = 16.0;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号