


KAFKA 2.3 以后,consumer 分为 dynamic 和 static,以是否设置了 group.instance.id 属性区分。
以默认的 consumer 为例,即 dynamic consumer,以下图描述其正常的生命周期:
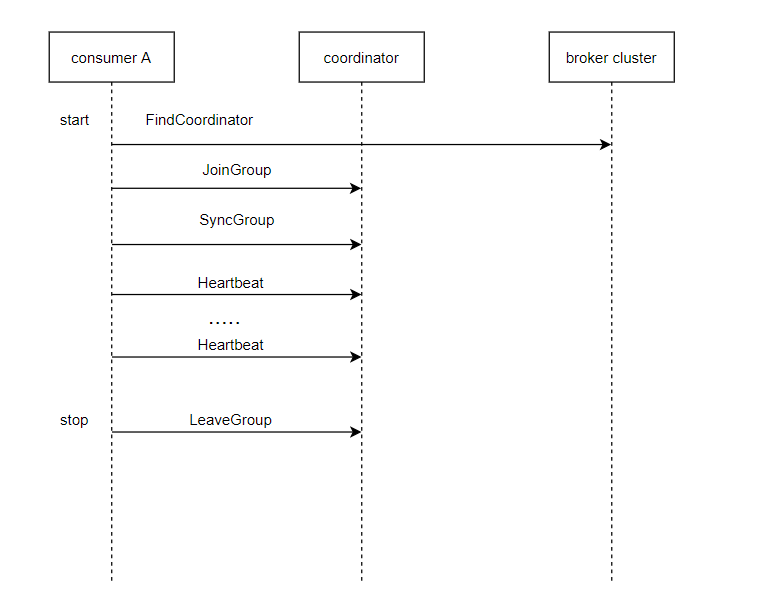
依赖 FindCoordinator, JoinGroup, SyncGroup, Heatbeat, LeaveGroup 等协议命令,kafka consumer 和 broker 联合完成了 group 管理,在 broker 侧,每个 group 有个状态机的演变过程,JoinGroup 或 SyncGroup 这种请求很可能会发送多次。
协议命令表:
| 命令 | consumer | broker |
| FindCoordinator | consumer 启动时,从配置的 bootstrap server 中选择一个负载较小的 broker,向其发送查找 coordinator 的请求 | 首先介绍 __consumer_offsets 这个功能 topic,consumer 提交的位点信息保存在这个 topic 中,这个 topic 默认有 50 个分区,1 副本。broker 接收到 FindCoordinator 请求后,对 group.id 的哈希值对 __consumer_offsets 的分区数即 50 取模,得到分区 id,分区 leader 所在的 broker 即 consumer 的 coordinator。 |
| JoinGroup |
consumer 查询到 coordinator 后,开始加入组,join group 时携带了客户端的配置信息,具体内容参见 JoinGroupRequestData |
|
| SyncGroup |
consumer 接收到 join group 响应后,如果当前实例分配到了 leader,则按照分配策略分配分区给各消费者,并将分配结果以 SyncGroup 请求发送给 broker。如果当前实例非 leader,则发送一个不带内容的 SyncGroup 请求。具体内容参见 SyncGroupRequestData |
|
| Heatbeat | 从某种程度上看,一次 poll 算是一次心跳,poll 时会更新心跳计时器的时刻,如果 consumer 一直没有 poll 动作,HeartbeatThread 则自己发起心跳请求 | |
| LeaveGroup |
kafka 协调客户端和 broker 进行组管理的过程足够复杂,我们先有一个大致的框架,然后由浅入深看代码,对于 dynamic consumer,consumer 属于某一个 group,每个 consumer 有一个 member id,consumer 在进行 join group 的时候,有 generation 的概念,这个 generation 类似大多数集群选举时的 term,相当于朝代的意思。
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator.JoinGroupResponseHandler // org.apache.kafka.clients.consumer.internals.AbstractCoordinator.SyncGroupResponseHandler
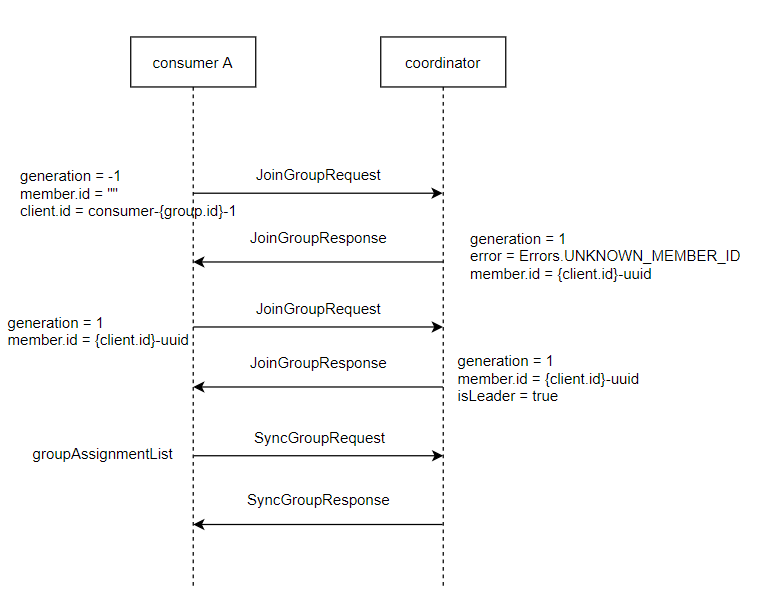
JoinGroupResponseHandler 和 SyncGroupResponseHandler 是 consumer 在收到 JoinGroup 响应和 SyncGroup 响应时所执行的逻辑,下图显示了一个完整的客户端视角的加入组的过程:
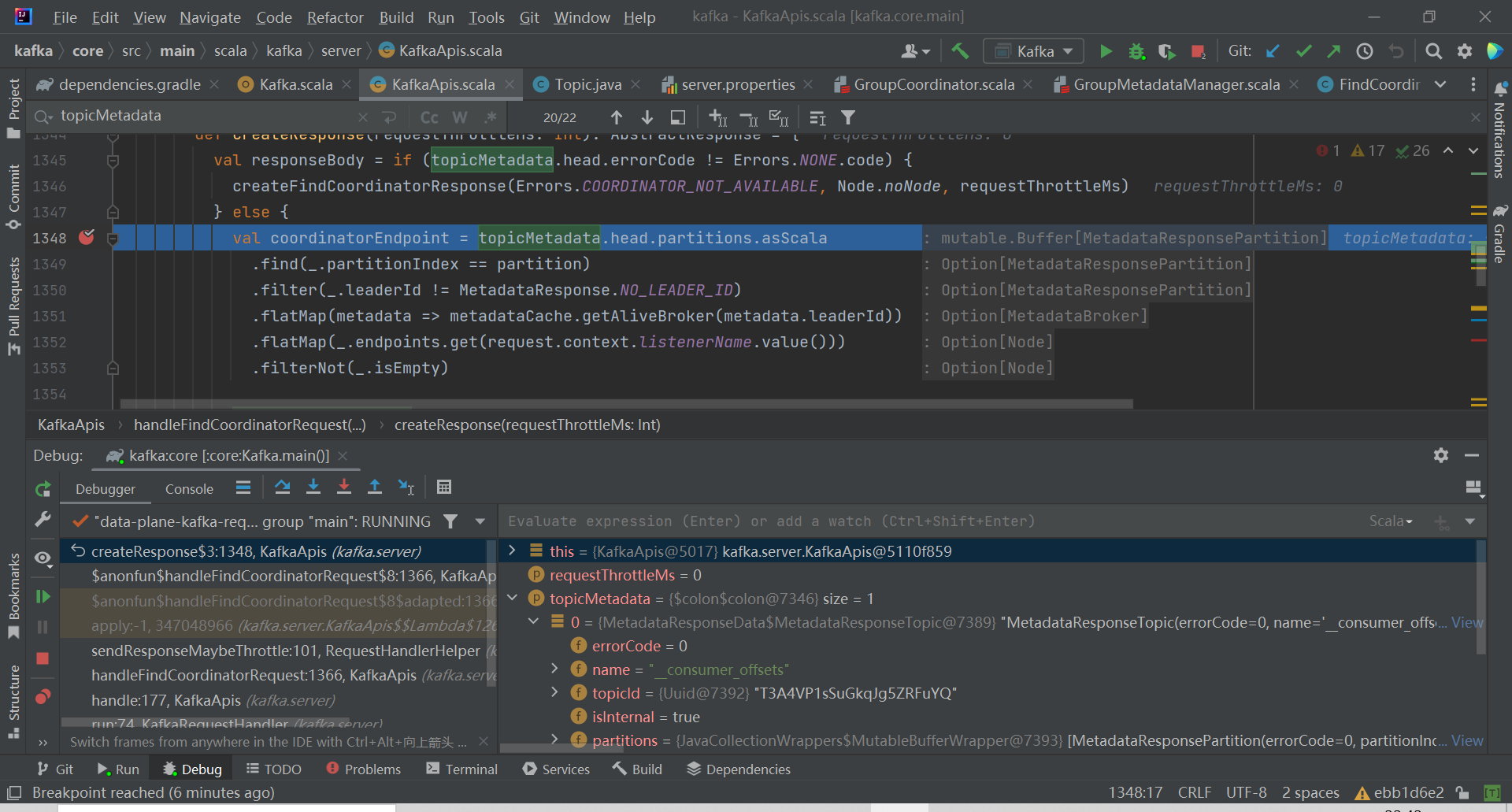
broker 处理 FindCoordinator 的请求栈如下图:
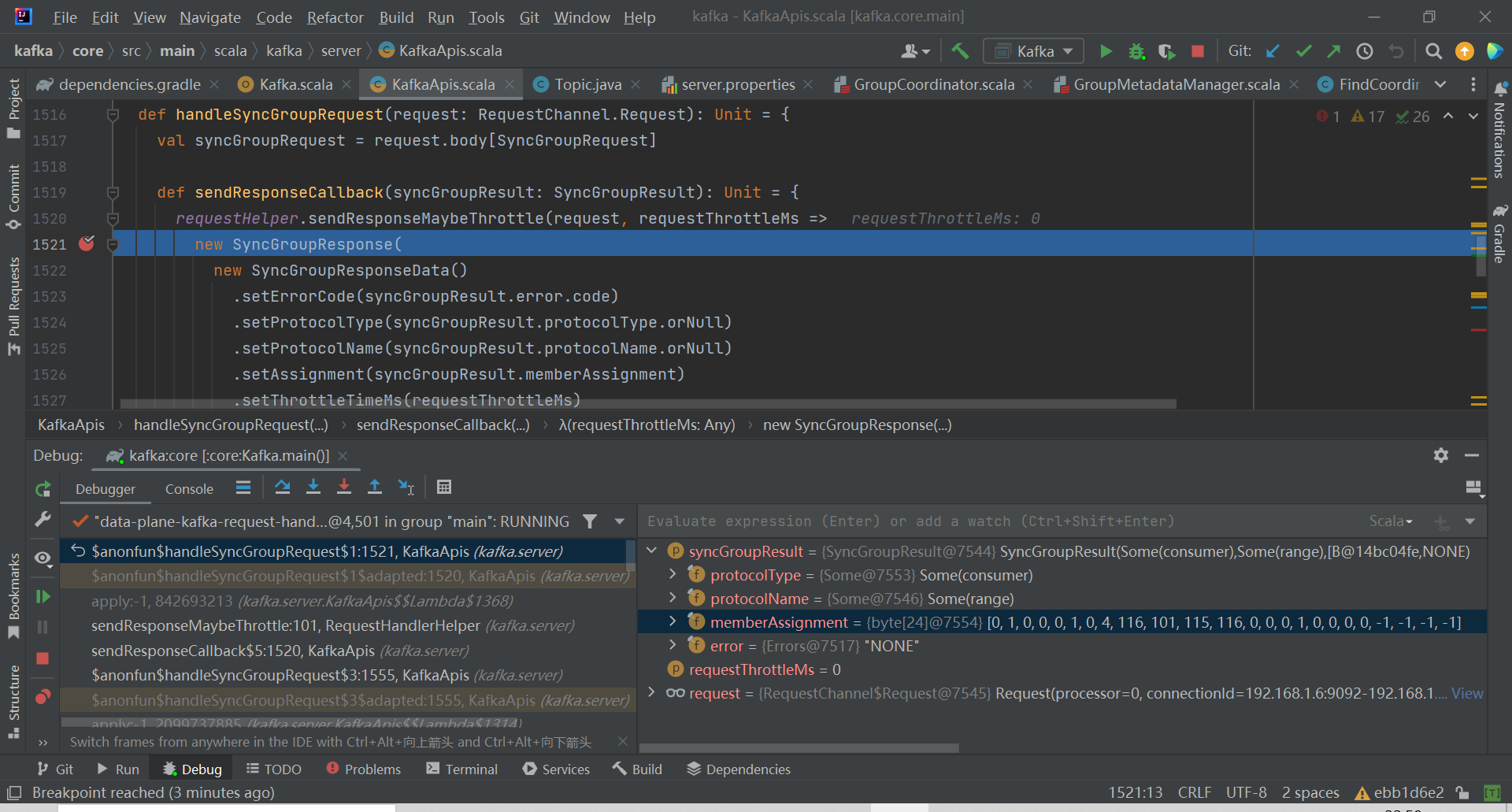
broker 处理 JoinGroup 的调用栈如下图:

broker 处理 SyncGroup 的调用栈如下图:
配置信息表:
| 属性 | 默认值 | 别名 | consumer | broker |
| group.id | groupId | |||
| group.instance.id | groupInstanceId | 如果提供了值, 则为 static consumer,当 consumer close 时,不会主动 leave group。可避免滚动发布时,频繁的 rebalance | ||
| max.poll.interval.ms | 300000 | rebalanceTimeoutMs | HeartbeatThread 检查 consumer 两次 poll 的时间间隔,如果超过了配置值,则主动 leave group | |
| session.timeout.ms | 10000 | sessionTimeoutMs | HeartbeatThread 检查 session 超过了配置的值,则标记 coordinator 为 unkonwn,并主动断开连接,重新开始下一轮 group 流程,即 rebalance | |
| heartbeat.interval.ms | 3000 | heartbeatIntervalMs | 以默认值为例,假定 consumer 在没有 poll 行为且还没超过 rebalance 间隔时,HeartbeatThread 每隔 3 秒向 broker 发送一次心跳,成功接收到心跳响应后,则更新 seesion 的时刻 | |
| partition.assignment.strategy | RangeAssignor | consumer 在发送 join group 请求时,会携带分配的策略 |
梳理完上面的表格,得出结论:在 HeartbeatThread 无限循环中, consumer 利用心跳来维持 session,当 session 过期时触发 rebalance,当 poll 时间过期时,触发 rebalance
分析 2 种常见的异常情况:
1. consumer 发送心跳,由于网络原因,或者 coordinator broker 宕机,consumer 一直没有接收到心跳响应,则 session 随之会过期,会触发重新加入组,即 reblance
2. consumer 和 coordinator 心跳正常,但是 consumer 一直没有 poll 动作,此时 consumer 会主动离开 group

 浙公网安备 33010602011771号
浙公网安备 33010602011771号