
有初步转 go 的意愿,大概看了下 filebeat 的代码,发现 filebeat 的源码值得剖析,不过也是个逐步的过程。
filebeat 整体是个多 input -> 单 output 的过程,那么就看看数据是怎么通过代码流转的?
bufferingEventLoop 我认为是一个顶层的类,它有一个 broker 属性,所有 input 和 output 的事件先汇入到 broker 的 channel 中,bufferingEventLoop 对输入的事件进行缓存,并批量处理,
事件流如下:producer.Publish -> broker.pushChan -> bufferingEventLoop.buf -> bufferingEventLoop.flushList -> consumer.Get
1. 本来想查看 filebeat 处理 fields.yml 文件的过程,全局搜索 "fields.yml" 发现一段代码:
func init() { if err := asset.SetFields("filebeat", "fields.yml", asset.BeatFieldsPri, AssetFieldsYml); err != nil { panic(err) } }
查询发现 go 语言有 init 函数,先于 main 方法执行。
2. 详细跟了下 filebeat 中,consumer 从 broker 获取数据,并通过 output 发送出去的流程,图如下:
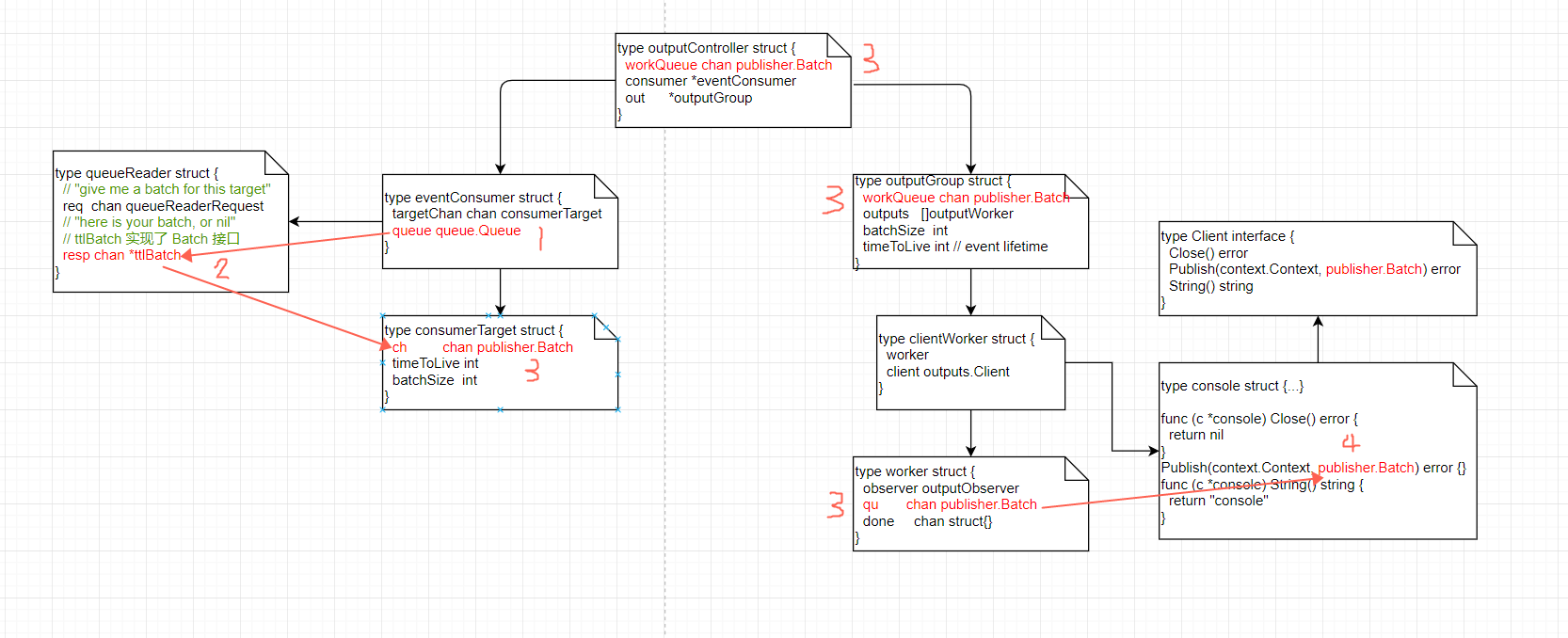
此段流程的发起点在 consumer 中,consumer 从 queue 中获取消息,发送到 Batch 的 channel 中,图中标名 3 的是同一个 channel,然后由 clientWorker 从 channel 中取出 Batch,并驱动 Client 执行,图中的示例 Client 是控制台 console,其他的可以是 elastic search,redis,kafka 等。
3. 毕竟 filebeat 是 elastic stack 中的一员,filebeat 的功能更多地服务于 elastic search,代码中涉及到 es 的 index template,fields 字段的处理:可以额外指定 fields.yml 文件,但是 filebeat 仍然有一些默认字段,所有这些 fields 最终会写入 es 中。查询 filebeat 在 es 中创建索引的 mapping,发现一系列并没有显式配置的字段。
在 libbeat/publisher/processing/default.go:256 Create 方法中大致描述了 event 字段的处理过程
setup 3, 4, 5: client config fields + pipeline fields + client fields + dyn metadata
input, env
setup 6: add beats and host metadata
ecs, host, agent
3.1 以 kafka input 为例,在 filebeat/input/kafka/input.go:435 composeEventMetadata 中自行添加了元数据字段,[(headers, key, offset, partition, topic), (message)]
3.2 在 libbeat/publisher/processing/default.go:144 WithAgentMeta 方法中,准备好了 agent 的元数据信息,ephemeral_id, id, name, type, version
3.3 在 libbeat/processors/add_host_metadata/add_host_metadata.go:84 Run 添加了 host 字段
3.4 在 libbeat/processors/actions/add_fields.go:75 Run 中分别添加 input 和 env 字段,以及 ecs,host,agent 字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号