

基于GAN文本生成视频---论文翻译(Recurrent Deconvolutional Generative Adversarial Networks with Application to Text Guided Video Generation)
摘要(原文地址链接在文章末尾)
这篇论文提出了一种新颖的视频生成模型,特别是尝试从文本描述中处理视频生成问题,即合成以给定文本为条件的逼真的视频。由于帧不连续性的问题和无文本的生成方案,现有的视频生成方法无法轻松地很好地处理此任务。为了解决这些问题,文章中提出了一种循环反卷积生成对抗网络(recurrent deconvolutional generative adversarial network RD-GAN),其中包括一个循环反卷积网络( recurrent deconvolutional network RDN)作为生成器和一个3D卷积神经网络 (3D convolutional neural network 3D-CNN)作为鉴别器。RDN是循环神经网络RNN的反卷积版本,可以很好地对生成的视频帧的长时间依赖性进行建模,并充分利用条件信息。提出的模型可以通过推动RDN生成真实视频,以使3D-CNN无法将它们与真实视频区分开来协同训练。我们将推出的RD-GAN应用于一系列任务,包括常规视频生成,条件视频生成,视频预测和视频分类,并通过取得良好的性能来证明其有效性。
关键字:视频生成 RD-GAN GAN
1. Introduction
图像生成最近引起了很多关注,其重点是从随机噪声或语义文本合成静态图像。但,在视频生成领域尚未广泛研究,即,合成动态视频,该动态视频包括内部具有一定时间顺序的静态图像序列。在这项工作中,我们希望推动这个主题的发展,生成更好的视频,解决很少有人研究的文字驱动视频生成。
这里的任务可以定义如下:给定一个描述某人正在做某事的场景的文本,目标是生成具有相似内容的视频。这面临的挑战涉及语言处理,视觉语义关联和视频生成。一个简单的解决方案是为该任务概括现有的视频生成模型。但是由于以下原因,它不是最佳的:
- 传统的视频生成直接从噪声中生成视频,而不是从语义文本中生成视频。
- 现有的视频生成模型大多会遭受视觉不连续性问题的困扰,因为它们要么直接忽略生成视频的时间相关性而建模,要么简单地在3D反卷积的有限范围内考虑它。
在本文中,我们提出了用于条件视频生成的循环反卷积生成对抗网络(RD-GAN)。提出的RD-GAN首先将具有跳过思想的给定语义文本表示为潜在向量,然后利用名为循环反卷积网络(RDN)的生成器,基于潜在向量逐帧生成视频。可以将RDN视为常规递归神经网络的反卷积版本,用权重共享的卷积和反卷积连接替换全部的全连接。因此,其隐藏状态现在是2D特征图而不是1D特征向量,这有效地促进了空间结构图案的建模。 生成之后,生成的视频随后被馈送到鉴别器,该鉴别器使用3D卷积神经网络(3D-CNN)来区分真实视频。可以对RD-GAN中的生成器和鉴别器进行联合训练,以生成可混淆鉴别器的逼真的视频。为了证明我们提出的RD-GAN的有效性,我们在常规和条件视频生成,视频预测和分类方面进行了各种实验。
我们的贡献总结如下。 据我们所知,我们尝试研究句子条件视频生成的问题,当前对这方面的生成模型的研究较少,但是这是非常重要的研究主题。 我们提出了一种称为循环反卷积生成对抗网络的新型模型来处理该任务,该模型被证明可以在各种生成任务和判别任务中均实现良好的性能。
2. 相关工作
图像生成。 随着深度神经网络的快速发展,生成模型最近取得了长足的进步。 众所周知,Tijmen [19]提出了胶囊网络来生成图像,而Dosovitskiy等人[2]提出了具有反卷积神经网络的3D椅子,桌子和汽车。还有其他一些使用监督方法生成图像的工作[15,26]。 最近,无监督方法,例如变分自动编码器(VAE)[7]和生成对抗网络(GAN)[3],引起了广泛的关注。 Gregor等人[4]发现他们可以通过基于循环变分自动编码器和注意力机制来模仿人类绘画来生成简单图像。Oord等人[21]提出的自回归模型对像素空间的条件分布进行了建模,并取得了良好的实验结果。与其他方法相比,GAN在此类任务上具有相对较好的性能,并且基于GAN生成的有吸引力的合成图像,各种模型[24,25,1,18]。除此之外,还广泛研究了条件图像生成。 首先,简单的变量,属性或类标签[9,12]用于生成特定的图像。 此外,研究人员尝试使用非结构化文本来完成这项工作。 例如,Reed等人[14]使用文本描述和对象位置约束来生成带有条件PixelCNN的图像。 根据条件GAN建立的以后的作品[13,27]通过文本描述成功地获得了64×64或更大规模的鸟类和花朵的图像。
视频生成。在我们进入视频生成模型之前,有必要回顾一下与视频预测和生成有关的最新进展。[6,28]在视频连续性方面给了我们启发。与视频预测相比,视频生成任务中没有上下文信息。 Vondrick等人[22]首先提出了一种“暴力”生成模型,该模型可以直接从3D反卷积中产生固定长度的视频。但是,与1D和2D解卷积相比,3D解卷积导致的信息丢失更为严重。 为了解决这个问题,Saito Masaki等人[16]提出了TGAN,它试图以视频由图像组成的方式找到连续帧的所有潜在矢量。他们使用1D和2D反卷积逐帧生成视频。不幸的是,他们的结果没有如他们预期的那样具有良好的连续性。 MoCoGAN [20]将运动和内容分解为视频生成,但是他们的模型缺乏对语义的理解。 在这项工作中,我们提出了一种包含反卷积网络(RDN)的循环反卷积生成对抗网络(RD-GAN),以处理视频生成中的当前问题并充分利用条件约束。
3. 循环反卷积生成对抗网络
Recurrent Deconvolutional Generative Adversarial Network 我们提出的递归反卷积生成对抗网络的体系结构如图1所示。
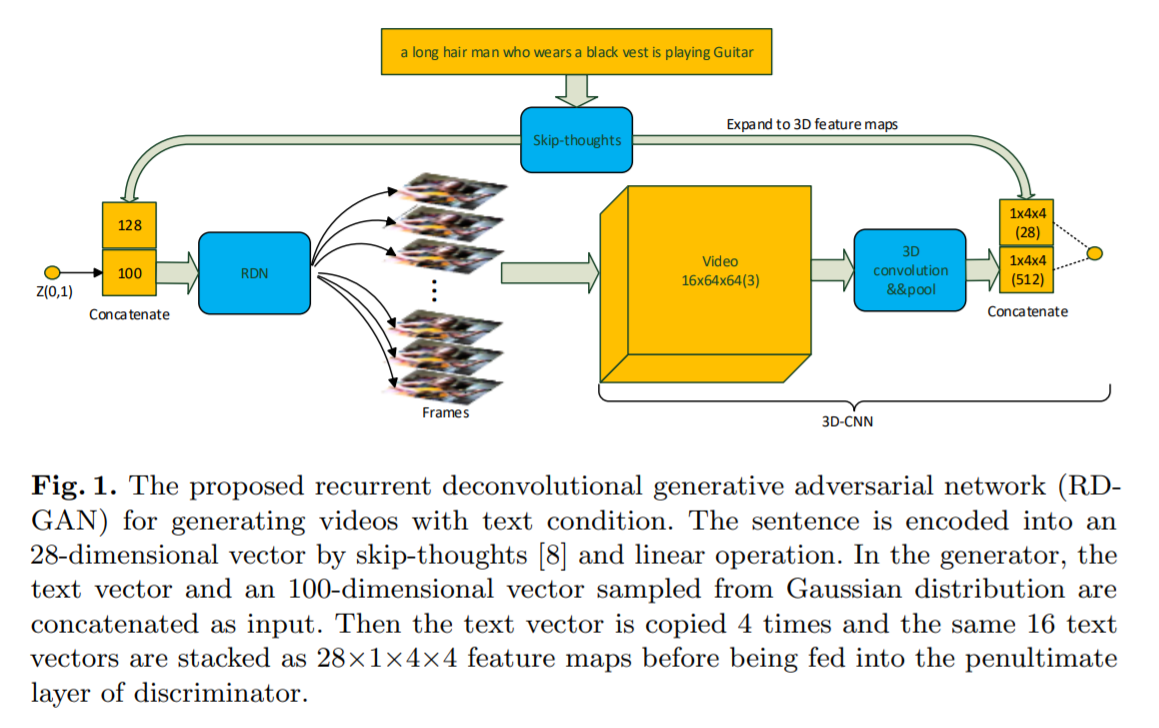
图1显示了我们提出的用于生成具有文本条件的视频的循环反卷积生成对抗网络的体系结构。RD-GAN建立在常规生成对抗网络(GAN)的基础上,该网络具有两个子网络:生成器和鉴别器。生成器是一个循环反卷积网络(RDN),它试图生成更逼真的视频,其输入是顺序级联向量(sequential concatenated vectors),由高斯分布中采样的噪声和通过跳跃思想[8]嵌入文本组成。鉴别器是3D卷积神经网络(3D-CNN),它试图在两个类别之间区分输入视频:“真实”和“伪造”。在二进制分类期间,它还利用了与鉴别器中视频特征图连接的文本嵌入。 这两个子网是通过玩非合作游戏共同训练的,其中生成器RDN试图欺骗鉴别器3D-CNN,而鉴别器的目标是避免犯错误。 事实证明,这种竞争性方案对于训练生成模型有效[3]。 接下来,我们将详细介绍生成器和鉴别器。
3.1 循环反卷积网络的生成器
基于语义文本的视频生成任务主要面临两个挑战。一种是如何从文本中提取合适的信息,并将其与生成的视频的内容相关联。这可以通过利用自然语言处理和多模式学习领域的最新进展来解决。另一个如何很好地对视频帧的长期和短期时间相关性进行建模,它们分别关注全局缓慢变化的模式和局部快速变化的模式。现有的方法要么只是考虑使用3D卷积的局部快速变化方法,要么通过将每个帧生成视为一个单独的过程而直接忽略时间相关性的建模。
为了很好地模拟视频生成过程中的长期时间依赖性,我们提出了一个循环反卷积网络(RDN),如图2所示。RDN具有深的时空架构,其输入是噪声和从给定文本中提取的矢量的组合,而输出是生成的视频帧的序列。权重分配在时间和空间方向上被广泛使用,可以有效地减少参数数量并有助于模型的稳定性。
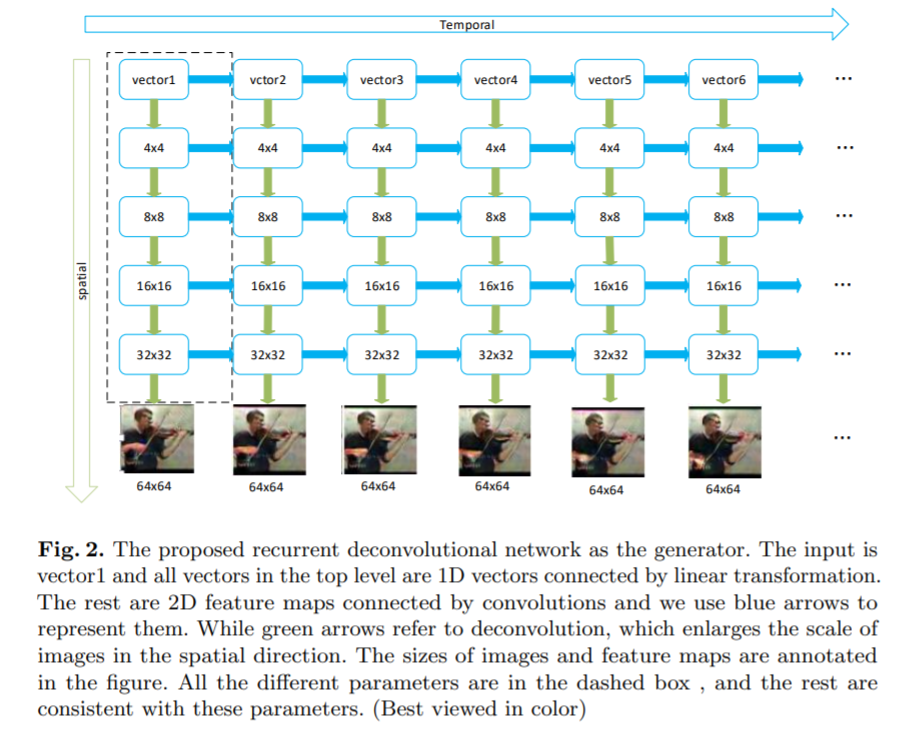
3.2 改进的3D卷积神经网络作为判别器
鉴别器的作用是通过将给定视频分为两类来识别真实性:“真实”和“伪造”。 考虑到3D卷积神经网络(3D-CNN)在视频分类任务中的表现非常好,因此我们直接将其用作判别器。 我们对3D-CNN进行了一些更改,如下所示: 1)将最后两个线性层替换为一个3D卷积层。 2)随着我们视频帧的尺寸为64×64,某些层的原始尺寸减小了。 3)每次3D卷积后使用3D批处理归一化,leakyReLU激活功能和3D最大池化。 4)在倒数第二层中组合了通过跳过思想嵌入的文本。
3.3 训练
生成器和鉴别器的权重可以通过以下目标函数共同训练:

通过从均值为0且标准偏差为0.02的高斯分布中采样来初始化所有网络权重。 我们使用ADAM求解器来优化所有参数,其中学习率是0.0002,动量是0.5。 为了加快训练过程,我们首先使用视频片段中的所有图像来训练基于图像的GAN,该GAN在空间方向上与建议的RD-GAN具有相同的体系结构。 然后,我们将学习到的权重用作RD-GAN的预训练权重,并微调视频上的所有权重。 实际上,我们可以选择以更长的培训时间删除此类预培训步骤。
4 实验
4.1 数据集和实作细节
在训练过程中使用UCF-101 [17]数据集。 它包含13320个视频,这些视频属于101种不同的人类行为。 由于UCF-101中有许多类视频,因此我们的模型很难学习到如此复杂的数据分布。 因此,我们每次都使用属于同一类别的视频来训练单独的网络。 请注意,当我们评估来自鉴别器的表示时,会使用整个UCF-101数据集。
为了扩大我们的训练数据集,我们将每个视频分为包含16个连续帧的多个视频段。 例如,帧1至16构成第一视频段,第二视频段由帧2至17组成,第三视频段由帧3至18组成,依此类推。 因此,一类视频可以获取大约20,000个视频片段,并且所包含的帧都将调整为64×64的大小。对于与视频相关的语义文本,我们尝试为不同的视频提供不同的人工文字描述。 例如,“一个戴着红色头带和黑色衬衫的可爱小男孩正在拉小提琴”或“一个戴着黑色T恤的卷曲年轻男子正在弹吉他”。 具有相同内容和背景的视频被归入同一类,并使用相同的文字描述命名,因为UCF-101中的视频是从相同的长视频中分离出来的。
4.2 从句子生成视频

从人类书写的文本中生成特定的视频等同于当我们看小说时大脑想象一个场景。为了使我们的模型适应文本驱动视频生成的任务,我们利用生成器和鉴别器的文本信息,如图1所示。我们使用跳跃思想[8]将给定的文本编码为4800维矢量,然后将矢量从4800映射到28维。之后,我们将28维文本向量与从高斯分布中采样的100维向量连接起来,然后将新的128维向量用作生成器的输入。我们还将相同的串联向量提供给鉴别器,该鉴别器在与3D-CNN的倒数第二层结合之前已扩展到3D数据。为了简单地注释视频数据,我们只是将相似的视频收集到同一类中,并为其提供相同的文字描述。 首先,我们从已知的文本生成视频,如图3所示。从该图可以看出,我们的模型能够生成与语义相关的视频。例如,当给定文本:“一个穿着黑色背心的长发男子正在弹吉他”时,我们的模型可以相应地生成具有以下属性的视频:“长长的头发”,“人”和“黑色背心”。 然后,我们尝试更改句子中的某些属性,并将这些“陌生”句子发送到我们的模型。 图4显示了我们的模型可以生成具有正确属性的新样本。由于数据量不足,结果不清楚。 换句话说,存在语义空间和图像空间之间缺乏连续映射的问题。
4.3 视频分类
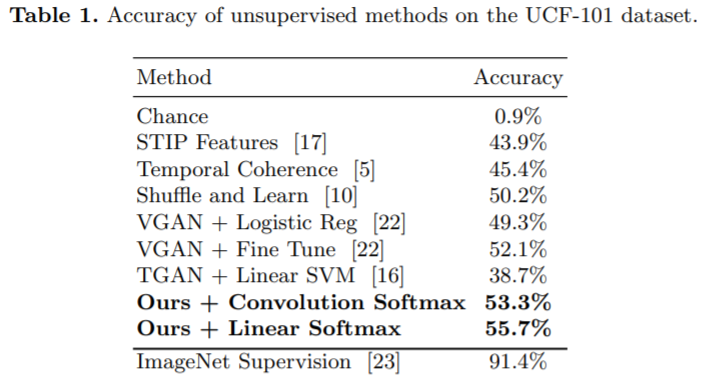
考虑到鉴别器中的特征是在没有监督的情况下学习的,因此我们想定量分析对视频分类任务的鉴别能力。 由于鉴别器最初用于二进制分类,因此我们必须用softmax分类器替换其最后一层,以进行多类分类。 此实验中使用了UCF-101数据集中的所有视频。 通过将所有视频分割为16帧片段,我们总共可以获得600万个视频片段。 每个视频片段的类别都与其原始视频的类别一致。 我们首先在最后两层中使用与[22]相同的softmax和dropout,后者使用卷积使最后的特征图转换为101维向量。 我们关注它们并使用1/8标记的视频来训练softmax分类器。 表1显示了我们的模型将精度提高了1.2%。
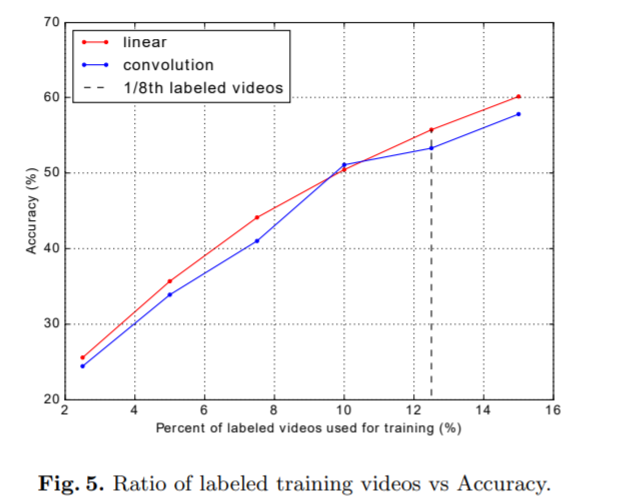
考虑到线性运算还可以将最后的特征图转换为101维向量以进行分类,因此我们使用线性运算来替换先前使用的卷积。 令我们惊讶的是,该班轮业务将我们的绩效进一步提高了2.4%。 请注意,卷积运算和线性运算都具有相同数量的参数。 显然,利用外部监督的模型仍然比非监督方法要好得多。 在图5中,还通过使用不同数量的标记视频比较了卷积softmax和线性softmax的性能,我们可以看到,训练数据数量越多,准确性越高。 总体而言,线性softmax比卷积softmax产生更多判别结果。
5 总结与展望
我们提出了一种循环反卷积生成对抗网络,该网络基于语义文本生成视频。它的生成器是循环神经网络的反卷积版本,它能够很好地利用文本信息,并在视频生成过程中有效地对远程时间相关性进行建模。我们在常规视频生成,文本驱动的视频生成,视频预测和视频分类方面进行了各种实验。 实验结果证明了我们模型的有效性。 请注意,这只是视频生成的初步工作,可能具有以下缺点。 如果基于太多帧进行训练,则基于GAN的建议模型将变得不稳定,并且目前无法很好地生成较大尺寸和较长长度的清晰视频。 给定文本的处理仅涉及特征提取的简单步骤。 使其与各种视频内容关联可能不是最佳选择。 将来,我们将考虑使用更多帧训练RDN,并扩展模型以级联方式生成更大尺寸和更长长度的视频。 此外,我们计划详细扩展带注释的视频,以更好地生成文本驱动的视频。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号