解读Mirantis最新的Neutron性能测试
最近,mirantis的工程师发布了最新的基于Mitaka版本的Neutron性能测试结果。得出的结论是:Neutron现在的性能已经可以用生产环境了。
报告的三位作者都是OpenStack社区的活跃开发者,其中一位还是Neutron的core reviewer。并且这份报告出自实际环境(并非各种模拟环境),因此含金量还是很高的。这不禁让人觉得,或许这才是社区开发的正确打开方式,同时也佩服mirantis舍得花真金白银(人力,物力)来做这样的基础性验证。
下面我来给大家解读一下这篇测试报告。
测试环境
基于Mirantis OpenStack 9.0,对应社区Mitaka版本。值得注意的是,社区的Newton版本已经release几个月了,但是Mirantis的最新发布版还是M版本。其实这么做是合理的,虽然最新的版本包含了更多的功能,更多的功能对应了更多的代码,更多的代码意味着更多的bug。所以采用最新的版本往往会有更多的风险。另外,在OpenStack Mainstream开发时,一些重要的bug通常都会backport到之前的版本。通常是之前两个版本,也就是说虽然现在已经是O版本的开发,但是Mitaka版本还在维护中。所以,在现阶段采用的Mitaka版本,是最稳定的版本。当OpenStack进入P版本开发,Mitaka版本将不再维护,相信那个时候Mirantis会推出自己的基于Newton版本的OpenStack。
测试重点关注的是OpenStack Neutron,但是由于是一个完整的系统,其他的组件,例如RabbitMQ,DB,Nova,Ceph,Keystone也跟着被测试了一把。
再看一看Neutron的配置:
- ML2 OVS:使用了Neutron OpenVSwitch agent作为L2 agent
- VxLAN/L2 POP:数据网络使用VxLAN,并打开L2 pop功能。
- DVR:L3使用DVR
- rootwrap-daemon ON:打开rootwrap进程
- ovsdb native interface OFF:关闭ovsdb native interface。OpenStack Neutron默认是打开这一项的。关闭这项功能意味这用ovs的外部命令“ovs-vsctl”来配置ovs网卡。Ovsdb native interface是通过用tcp连接ovs db来配置ovs网卡。通常情况下ovsdb native interface效率更高。Mirantis没有给出关闭的理由,我估计是想减少tcp连接,以减少对数据转发层的影响。
- ofctl native interface OFF:与上一项类似,关闭ovs OpenFlow controller。Neutron默认也是打开这一项的。关闭之后,Neutron将使用ovs的外部命令“ovs-ofctl”来下发OpenFlow规则。这也会大大降低控制面的效率。Mirantis同样没有给出理由,不过估计理由也是为了减少对数据转发面的影响。
- agent report interval 10s:小于默认值30s
- agent downtime 30s:小于默认值75s,这两项值的调低会增加控制面的负担,但是能更快的检验控制面的有效性。
配置项的倒数4项都是为了测试而修改的配置,修改后会影响控制面的性能,实际生产环境还是建议使用Neutron默认值。
Integrity test(连通性测试)
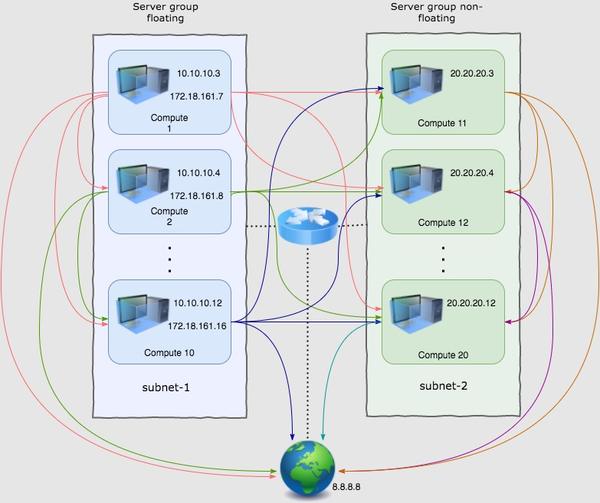
这个测试没太多可说的,就是同时测试Neutron的L2 domain通信,L3 domain东西向通信,L3 南北向floating IP通信,L3 南北向NAT 通信,确保这些通讯正常。有两点值得注意的:
- 测试中的不同虚机在不同的计算节点上。也就是说,测试中的数据包,都经历了完整的网络路径,而并不是只在某个计算节点的br-int上走了个来回。
- 这里的测试将伴随着其他测试进行。在后继的测试中,这个测试的脚本仍然会运行着,以检查其他测试本网络连通性的影响。
Density test(最大容量测试)
这个测试验证了,OpenStack Neutron最多可以支持多少个虚机。这里说的支持,是指能给虚机配置网络,并且虚机具有外网访问权限。
测试的硬件是200台主机,其中Compute node有196台。其他细节报告里没有说,但是Mirantis的Controller node一般是3台,还有一台主机估计是辅助测试用的外部服务器。
测试中的虚机在启动的时候,会向metadata server申请IP地址,并且会向一个外部服务器汇报自己的IP地址。也就是说如果虚机的网络正常,外部服务器可以收到虚机的汇报。
测试基于Heat,测试中的Heat stack有一个network,里面包含一个subnet,一个DVR,以及每个Compute node上的一个虚机,也就是196台虚机。一次创建5个Heat stack。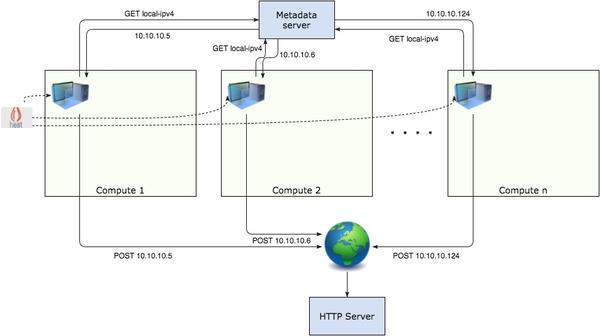
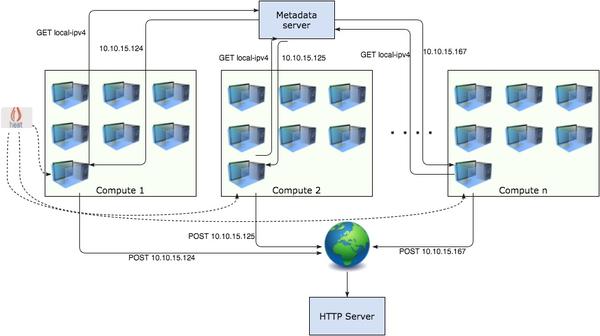
最终,成功创建了125个Heat Stack,对应的也就是125*196 = 24500个虚机。 这个数字比他们的7.0版本(对应的应该是Kilo版本)要多2倍,从这可以看出,随着OpenStack的进化,使得其性能越变越好。
测试中,相关的性能数据如下表:
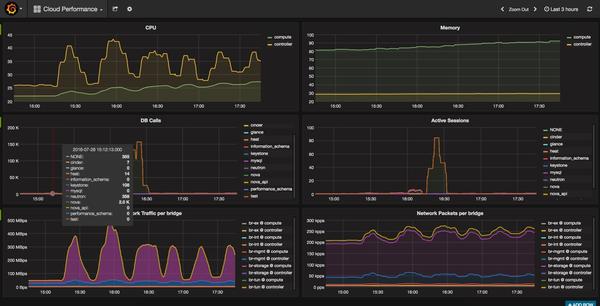
得出的结论就是,随着虚机数量的增加,Controller,Compute,DB,网桥上的负担缓慢增加。这个也比较好理解,因为测试中的虚机只在启动的时候有网络请求,之后就一直处于idle,没有网络请求。实际环境中,不可能起了虚机什么也不干,所以实际环境中的曲线会更“陡”一些。
最终阻止测试进行下去的是内存的限制,而不是OpenStack Neutron的限制。
Mirantis的报告中指出了在测试中遇到的一些问题。
- 调大了ARP表。在创建大概16000个虚机的时候,ARP表爆了,导致虚机网络不可用。调大了ARP表,继续跑测试就不再出现问题。
- 将OpenStack Nova的配置项cpu_allocation_ratio提升至12.0,以防止Compute Node上的nova vCPU的限制。
- 在创建了大概20000个虚机的时候,RabbitMQ和Ceph开始出现异常,而到24500个虚机的时候,OpenStack service和agent开始大规模罢工。而此时Compute Node的内存也快要耗尽,因此结束测试。分析认为,可以通过增加Ceph monitor或者给在专属的主机上运行Ceph来解决Ceph的问题。
值得注意的是,尽管OpenStack service和agent最后大规模的罢工,但是虚机仍然具有网络连通性。这正是SDN将控制层和数据层分离的好处。
Shaker tests(网络性能测试)
Shaker是一个针对OpenStack设计的网络性能测试工具。Shaker基于iperf3和netperf,可以调用OpenStack API生成测试场景,并且有可视化的测试报告。
网络性能测试同样是基于L2 domain通信,L3 domain东西向通信,L3 南北向通信,但是目前Mirantis只公开了L3 东西向测试的结果。L3东西向的网络拓扑如下:
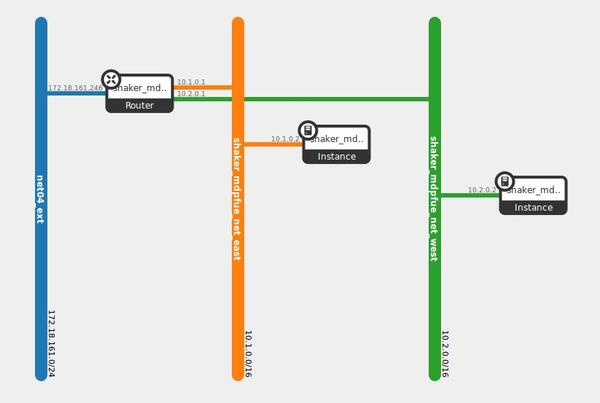
在测试过程中,有几点影响了测试结果:
MTU
当使用默认的MTU 1500时,虚机的上行/下载的速率极限约为561/528 (Mbit/S)。之后,将MTU更新到9000,虚机的上行/下载速率极限变成3615/3844(Mbit/S)。也就是说MTU由1500改到9000,网络带宽提升了7倍。 MTU越大,网络数据报文被分片的可能性越小,相应地效率更高,但是每一个数据包的延时也变大,且数据包bit出错率也相应增加。所以实际环境数据中心的MTU,应该调试到一个适当值,而不是盲目的改变。
Hardware offload
测试中的数据网络用的是VxLAN网络,在网络传输过程中,VxLAN协议会在数据包之外增加50 bytes长度。这就涉及了数据包出/入主机时,VxLAN协议的封包/解包。旧的网卡不具备硬件封包/解包的能力,这部分工作由CPU运算完成,而一些新型号的网卡(Intel X540 or X710),具备硬件封包/解包能力。配合这些新的网卡,网络性能势必会有提升。
在Mirantis的测试中,总共有三个环境:
- Lab A:主机网卡不具备hardware offload,但是没有给出具体网卡型号。
- Lab B:主机配备具备hardware offload 能力的X710 NIC网卡。
- Lab C:主机配备了4 块 10G X710 网卡,并且bond在一起。
Lab A
Lab A的情况,在MTU部分已经讲过。
Lab B
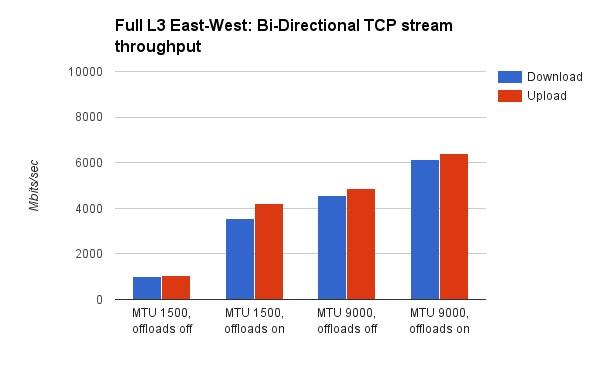
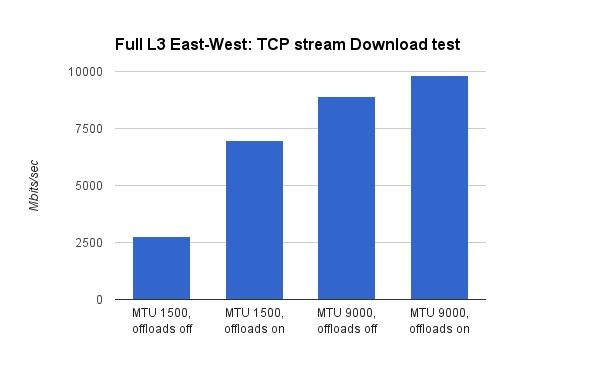
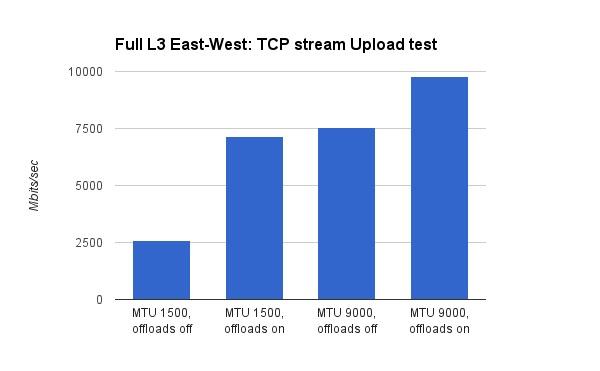
Mirantis测试了X710关闭/打开hardware offload时,对应的MTU=1500 和MTU=9000时的带宽:
从上面的图中,可以得出以下结论:
- VxLAN hardware offload,在低MTU(1500)时提升比较大。在双向带宽测试时,提升了3.5倍,在单向测试时提升了2.5倍。这个比较好理解,MTU越低,意味着网络数据包分片越严重,实际的数据包越多,对应的VxLAN offload压力也越大。这个时候的硬件加速,能带来显著的效果。
- 打开了hardware offload,MTU由1500升至9000,网络带宽仍然有明显的提升。在双向带宽测试时,提升了75%,单向带宽测试时,提升了41%。根据前面(Lab A的结果)MTU的分析可以知道,MTU变化带来的提升,与hardware offload是两个概念,因此即使打开和hardware offload,MTU的提升效果还在。
- 测试报告没有指出,同样情况下(hardware offload off),Lab B性能要明显好于Lab A,前者是后者的5倍。Lab B明显是一个更新的机房。因此,物理网络设备,例如网卡,交换机,对虚拟网络的带宽影响也是明显的。
Lab B的测试可以看出,开启硬件VxLAN offload,并使用较大的MTU,能明显提升虚拟网络带宽。
Lab C
硬件上Lab C与Lab B同规格,只是Lab C将4块网卡bond在一起,这带来的好处是网络带宽非常稳定,几乎线性。多块网卡bond之后,能实现多块网卡之间的负载均衡,因此得到这样的测试结果也是意料之中。
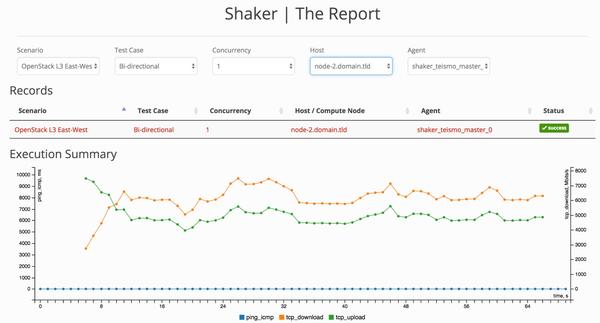
Lab B:
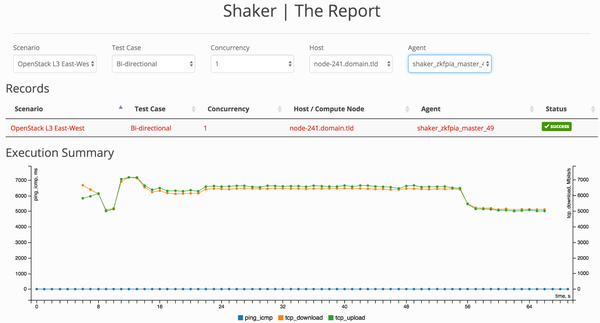
Lab C:
综合比较
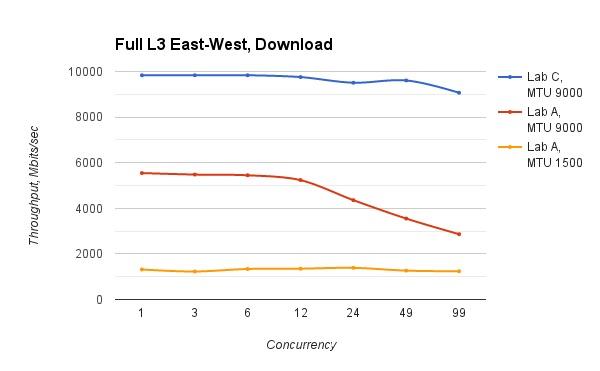
从这个图中,可以得出结论:高MTU,VxLAN hardware offload,以及bond 网卡,可以在高网络吞吐量时,保证虚拟网络带宽的稳定和更高的带宽。
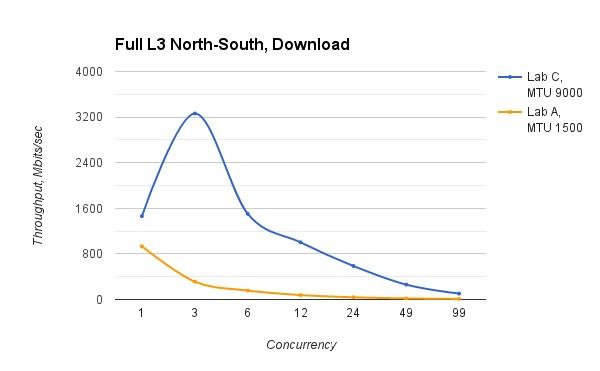 这张图就不那么好看了,当并发数增加时(可以理解多个虚机同时请求北向最大带宽),虚拟网络的带宽急剧下降。即使Lab C也是如此。DVR的SNAT还是集中式处理,当并发数增加时,网络节点的负担将大大增加,并成为瓶颈。北向访问的外网,其MTU,物理网络也变得更加不可控,这也是影响测试结果的因素。总之,OpenStack Neutron L3的南北向带宽,不尽如人意。
这张图就不那么好看了,当并发数增加时(可以理解多个虚机同时请求北向最大带宽),虚拟网络的带宽急剧下降。即使Lab C也是如此。DVR的SNAT还是集中式处理,当并发数增加时,网络节点的负担将大大增加,并成为瓶颈。北向访问的外网,其MTU,物理网络也变得更加不可控,这也是影响测试结果的因素。总之,OpenStack Neutron L3的南北向带宽,不尽如人意。
结论
- 在大规模部署中,Mitaka版本的OpenStack Neutron的没有大问题。一些小问题也已经在社区fix,并backport到Mitaka。
- 数据层的性能令人满意,通过配置合适的MTU,使用新型号的网卡和对网卡做bond能大幅提升虚拟网络带宽。
- 使用OpenStack Neutron在控制层崩溃的情况下,数据层还是能正常工作。虚机的网络连通性仍然保持着。
- Mitaka版本的OpenStack,管理虚机的能力比之前版本有明显提升,OpenStack处于正向进化的发展中。
- Neutron的控制层可以管理至少24500个虚机(配合3个控制节点,也就是3个neutron-server)。实际测试中,24500并非Neutron的极限,而是其他组件的极限。
- Neutron可以在超过350个计算节点的大规模环境中部署。
- Neutron L3的南北向性能目前仍然存在问题,在南北向流量较大的环境中,使用仍需谨慎。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号