机器学习基本范式

举例 : MNIST 识别手写数字
1. Hypothesis Class(我们选择的模型结构)
ŷ = softmax(W · x + b)
x = [0.0, 0.1, 0.8, ..., 0.0] ← 共 784 个数(784个像素点,原始图像根据每个像素点的亮度给每个像素点一个0-255的值,这些小数是通过归一化())
W 是一个10 * 784的矩阵(10行代表0-9 十个数字)。 每一行的784个值代表每个类别(哪个数字) 对该像素点的权重
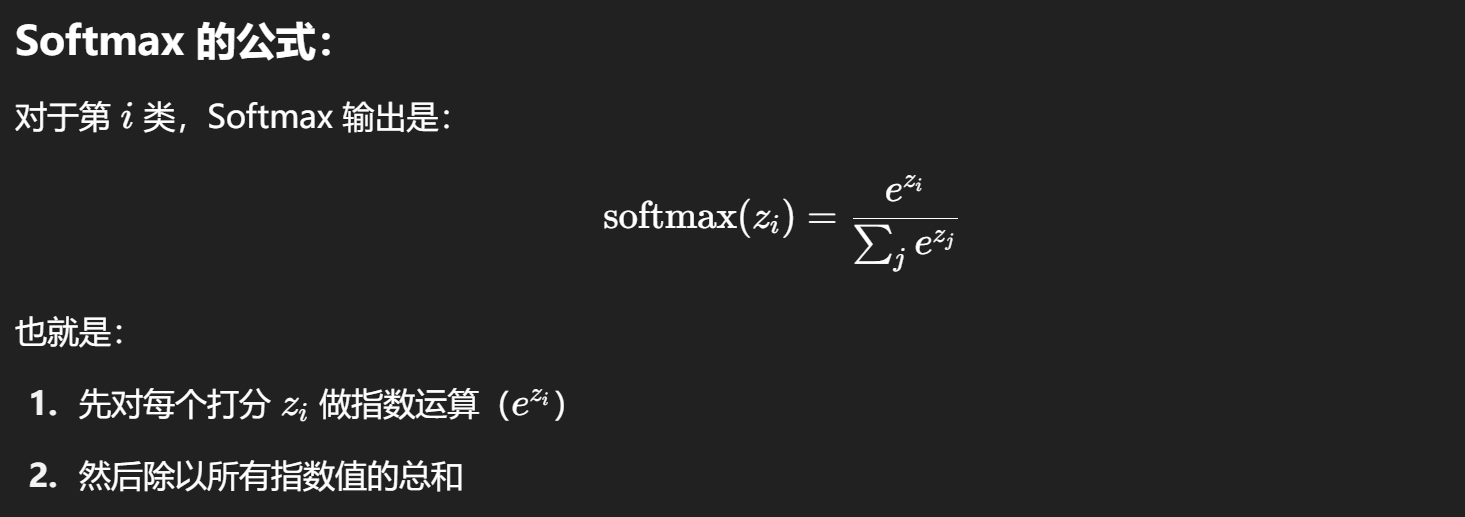
假设我们W*x+b 算出来 z = [3.2, 2.5, 0.1, -1.2, 0.9, 0.2, -0.7, 1.1, -2.4, 0.0]
z向量的每个数对应对每个数字的打分。
通过softmax得到对每个数字的概率分布 :
softmax(z) ≈[0.528, 0.263, 0.024, 0.006, 0.053, 0.026, 0.011, 0.065, 0.002, 0.021]
选最大概率的数字,所以输入的图片被识别为数字0
2. Loss Function(损失函数)
损失函数告诉我们:当前模型的输出和真实答案差多远
识别手写数字这种分类问题常用的损失函数是交叉熵损失
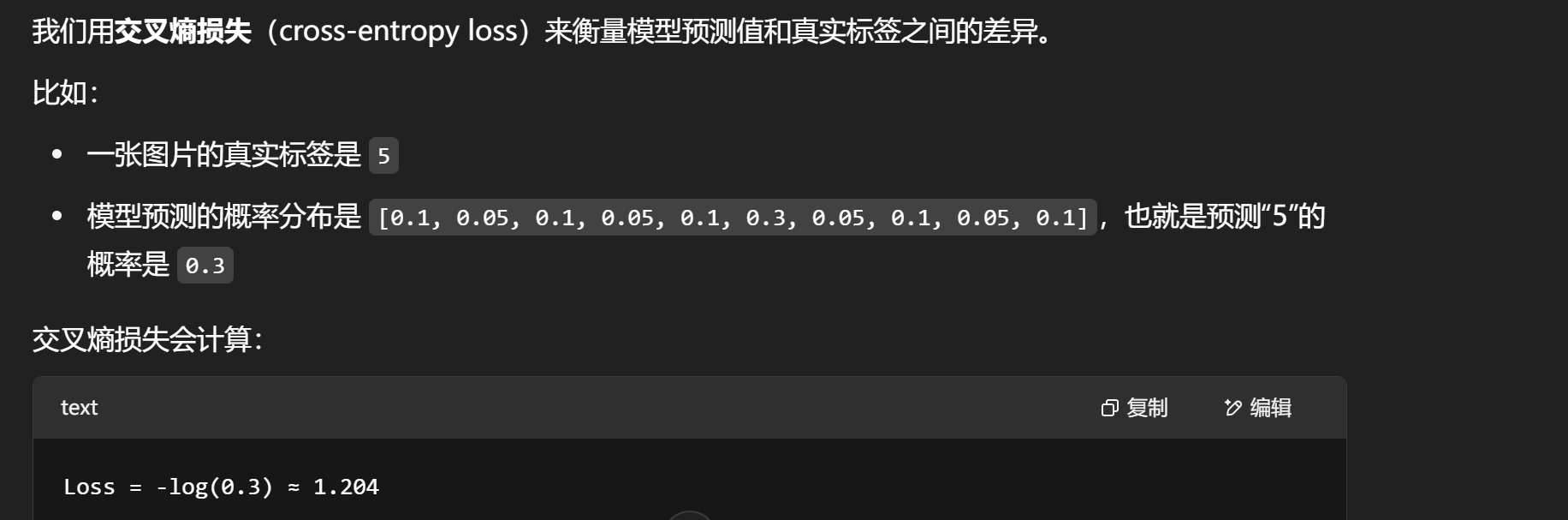
Loss 越小代表模型效果越好
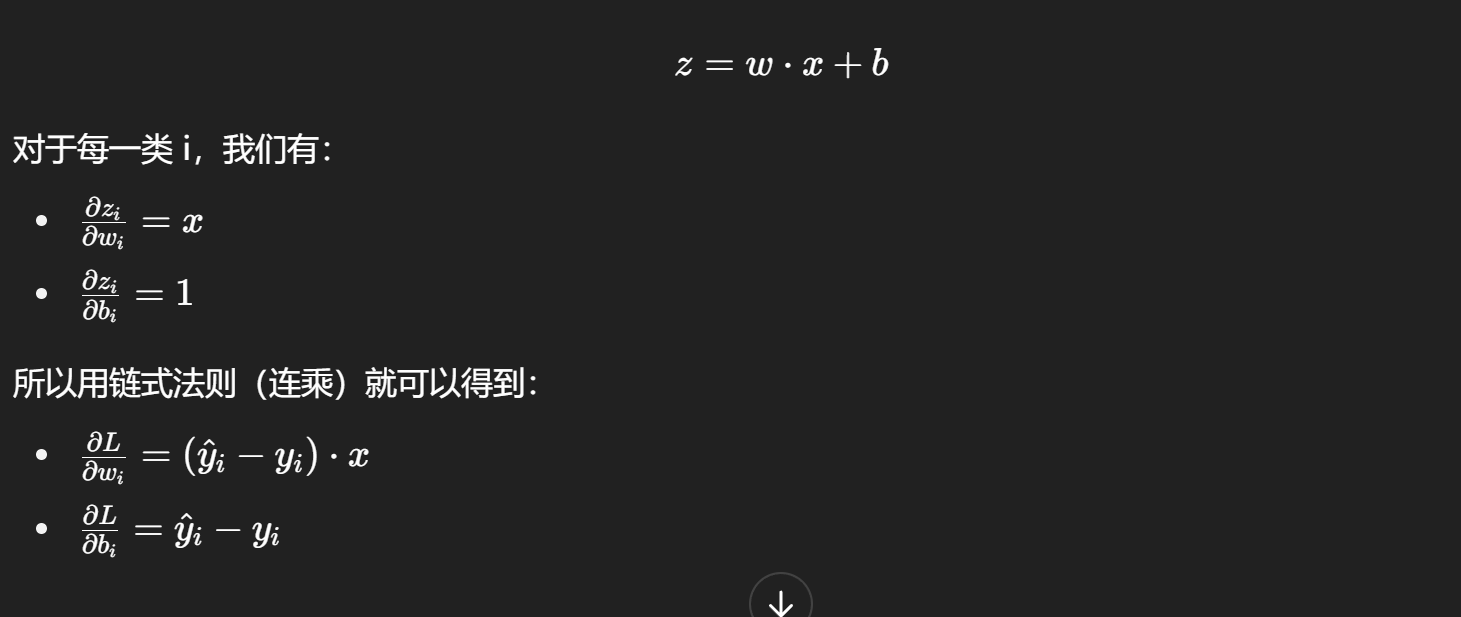
3. Optimization Method(优化方法)
优化器就是用来寻找最好的参数,让整个训练集的损失最小,在识别手写数字钟就是寻找最合适的W和b
我们先用一个W和b算出一组数据,然后(W和b的梯度是针对损失函数而言,让损失函数值最小)
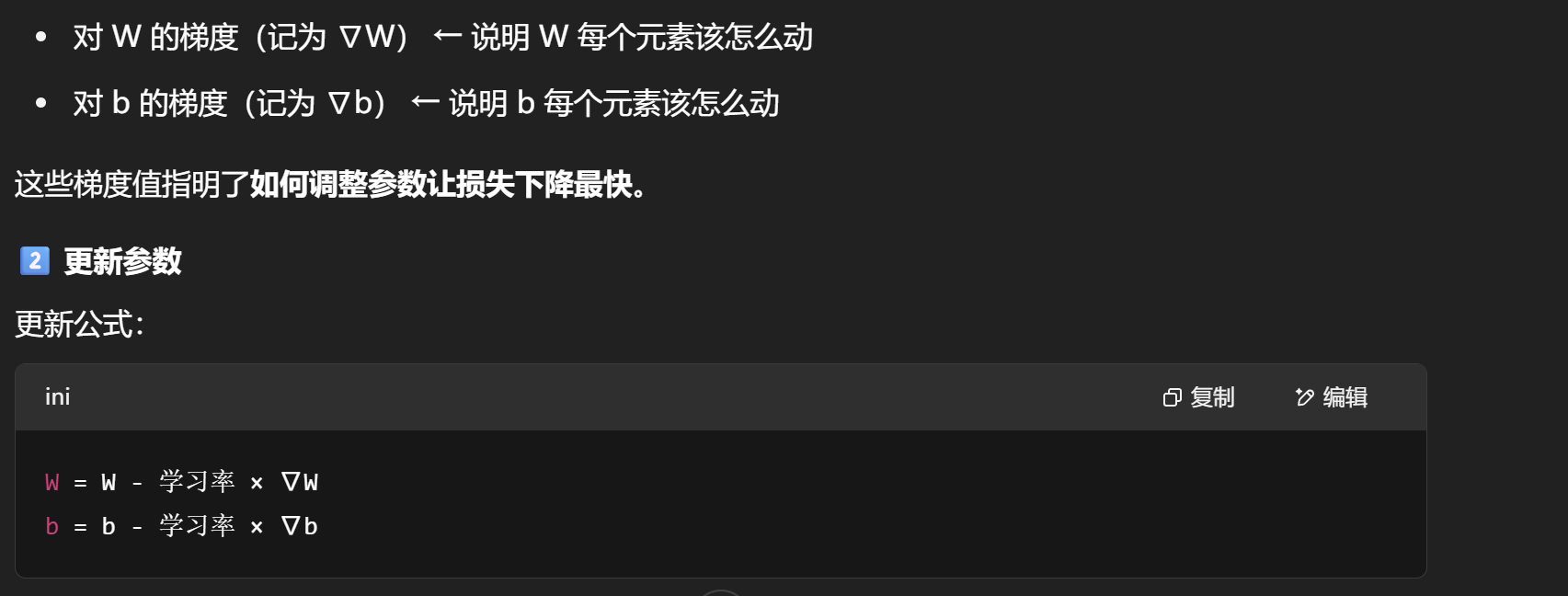
将更新后的参数再喂给一张图片,重复算出最合适的参数(交叉熵最小的)
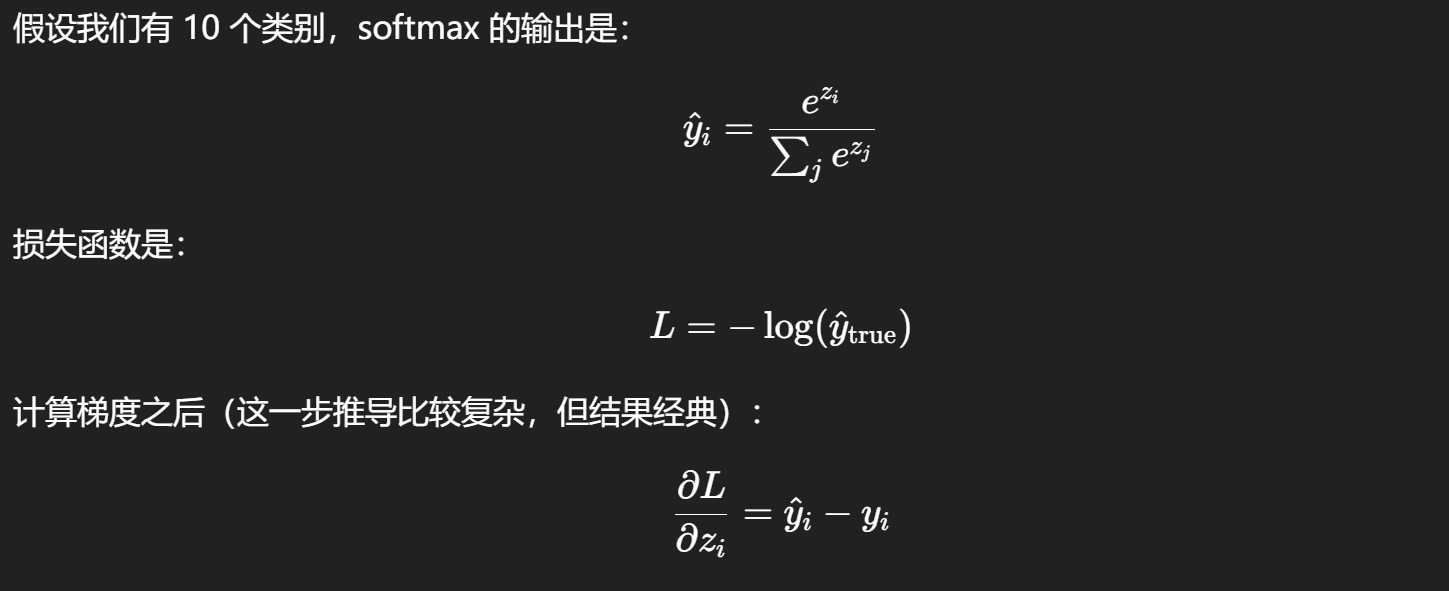

 浙公网安备 33010602011771号
浙公网安备 33010602011771号