MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation
论文名:
MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation
"MS-TCN++: 用于动作分割的多阶段时域卷积"
Shi-Jie Li#, Yazan AbuFarha#, Yun Liu, Ming-Ming Cheng, Juergen Gall,
IEEE TPAMI,
45(6):6647-6658,
2023
关键字:时域动作分割,时域卷积网络
研究问题:
最先进的方法是利用多层时域卷积和时域池化实现动作分割。
这些方法能捕捉时域相关性的能力,但存在过度分割的问题。
为什么会有过度分割?
- 复杂的动作表达: 如果视频中存在复杂、多变的动作表达,或者有一些微小的动作变化,这可能导致模型在细节上过度敏感,产生过度分割的错误。
- 数据噪声: 视频数据通常包含噪声,例如摄像头抖动、光照变化等。这些噪声可能被误认为是动作,导致错误的分割。
- 模型复杂性: 使用复杂的模型可能导致对训练数据过度拟合,尤其是在训练集中包含了噪声或不同程度的动作变化的情况下。这可能导致模型在测试时对于新的、稍微不同的动作表达过于敏感。
- 数据标注不准确: 如果训练数据中的动作分割标注存在误差,模型可能学到了不准确的分割模式,从而在测试时表现不佳。
- 时域分辨率不足: 如果视频的帧率较低,或者动作发生的变化很快,时域分辨率可能不足以捕捉到细微的动作变化,导致过度分割。
提出了一个解决时间动作分割任务的多阶段框架MS-TCN++,克服了以往方法MS-TCN的局限性。
具体:
1.提出一个结合大接收域和小接收域的双扩展层,解决较低层的接收域小的局限性。
2.第一阶段的设计与改良阶段分离,以满足不同要求,
结果:在长期相关性和识别动作片段方面是有效的。——在长视频的时域分割和活动分类表现好。
行文结构梳理:
1.介绍:
时域动作分割
- 早期通过
模型+滑动窗口相结合。利用不同尺度的时间窗来检测和分类动作片段
缺点:成本高昂,不适用于长视频。 - 之后采用
逐帧分类器+马尔科夫模型进行粗糙的时域建模。
缺点:速度慢,需要在长序列上解决最大化问题。 - 时域卷积网络(TCNs)在语音合成时域模型取得成功,现多采用基于TCN模型解决时域动作分割任务。
优点:通过大接收域捕获视频帧的长期相关性。
局限在:处理每秒几帧、非常低的时域分辨率的视频;依赖时域池化层来扩大接收域,会丢失细粒度信心。
提出MS-TCN也使用时域卷积。相比之前的方法,提出的模型能在全时域分辨率上运行。
MS-TCN:由多个阶段组成,每个阶段输出一个初步预测,然后由下一个阶段改良。在每个阶段,我们都会应用一系列扩展的一维卷积,使模型
具有参数较少的、大的时域接收域。此外,在训练中使用平滑损失来惩罚预测中的过度分割错误。
MS-TCN概览:
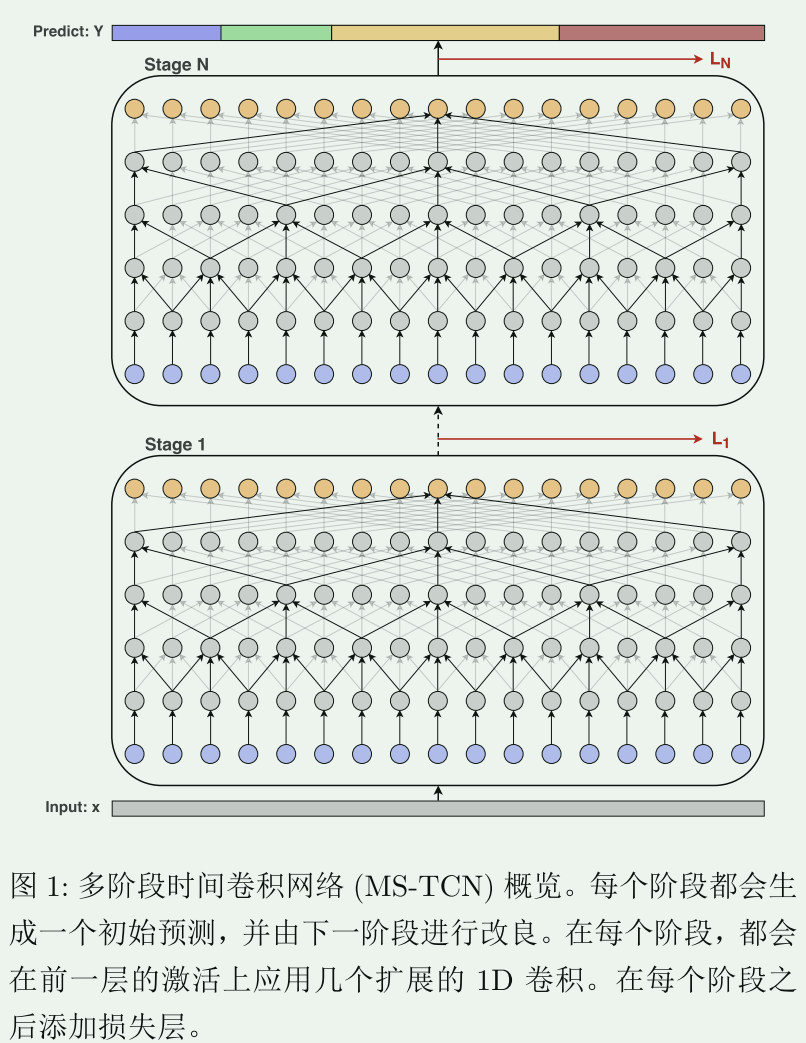
MS-TCN:仍有局限性:
- 较高层的接受域非常大,而较低层的接受域很小
- 第一阶段生成一个初步预测,其余阶段对该预测进行改良。两个任务存在差异但使用相同的架构。
解决局限方法:
- 双扩展层DDL,每一层结合了大接受域和小接受域。
- 将整个体系分成两部分:第一阶段为预测生成阶段,其余阶段为预测改良阶段。
并将此模型命名为MS-TCN++.
本文贡献:
• 我们提出了一个结合大接受域和小接受域的双扩张层。
• 我们通过去除预测阶段和改良阶段的耦合来优化 MS-TCN的架构设计。我们将新模型命名为 MS-TCN++,其效果优于MS-TCN。
• 我们进一步证明,在 MS-TCN++ 的改良阶段之间共享参数可以在不影响性能的情况下得到更紧凑的模型。
2.相关工作
时域动作分割:
- 早期,次用非最大抑制的滑动窗口方法;计算高昂
- Bhattacharya使用视频的时间序列矢量表示形式+线性动力系统理论对复杂动作的时域动力学建模。得到基于预训练的、重叠时域窗的概念检测器。
- Cheng 视频表示一个视觉词序列,并采用离散序列的非参数贝叶斯模型对视频序列同时进行分类和分割,对时域相关性进行建模。
——————以上方法捕捉长视频序列的前后关系时失败了——————
为了缓解这一问题,许多 proposals 尝试在逐帧分类器上采用高级时域建模。
- Kuehne et al. [9] 使用改进密集轨迹的 Fisher 向量表示视频的帧,然后使用隐马尔可夫模型 (HMM) 对每个动作建模。这些 HMMs 和与前后无关的语法结合在一起进行识别,以确定最可能的动作序列。
HMMs也可用于其他方法:
HMMs 与高斯混合模型 (GMM) 结合作为一种逐帧分类器。然而,由于逐帧分类器无法捕获足够的前后关系来检测动作类,Richard et al. [11] 和 Kuehne et al. [24] 使用GRU而非 [23] 中使用的 GMM。还使用了隐马尔可夫模型来建模状态之间的转换及其持续时间。 - Vo 和 Bobick [26] 使用贝
叶斯网络来分割活动。它们使用随机的与前后无关的语法和AND-OR 操作表示动作的组成部分。[27] 提出了一个时域动作检测模型,其包含三个部分: 一个将从视频帧中提取的特征映射到动作概率的动作模型, 一个描述序列级动作概率的语言模型, 最后是一个对不同的动作片段的长度建模的长度模型。为了实现视频分割,他们使用动态规划来寻找三个模型取得最大联合概率的方案。 - Singh et al. [28] 使用双流网络来学习短视频的分块表示。然后将这些表示传递给双向 LSTM,以捕捉不同块之间的相关性。但是,由于采用的是顺序预测,他们的方法速度很慢。
3 时域动作分割
MS-TCN++将给定视频的帧\(x_{1:T}=(x_{1},...,x_{T})\),目标是推断每个帧的类别标签\(c_{1:T}=(c_{1},...,c_{T})\),其中T是视频长度。
3.1. 讨论了单阶段方法
3.2. 讨论了多阶段方法
3.3. 介绍双扩展层
3.4. 分析了MS-TCN模型和改进的MS-TCN++模型
3.5. 损失函数
3.1 单阶段时域卷积网络SS-TCN
3.2 多阶段时域卷积网络MS-TCN
3.3 双扩展层DDL
3.4 MS-TCN++
3.5 损失函数
研究方法:
主要结论:
解释术语:
什么是时域分割?
视频的时域分割是视频处理领域中的一个概念,指的是将视频流分解成一系列离散的时间段或帧序列的过程。这种分割可以基于不同的准则,通常是为了更好地理解和处理视频内容。
以下是一些常见的时域分割的方式:
- 关键帧提取: 在视频中选择关键帧,这些关键帧代表了视频中的重要内容或变化点。这有助于快速浏览视频,同时减少存储和处理需求。
- 镜头切换检测: 识别视频中不同镜头之间的切换点。这对于视频编辑、摄影分析以及某些应用中的关键场景检测非常有用。
- 动作检测和跟踪: 通过检测视频中的运动或动作来分割视频。这可以用于视频监控、行为分析等应用。
- 活动识别: 识别视频中的特定活动或事件,将视频分为不同的活动段。这在智能监控系统和视频内容理解中很有用。
- 音频-视频同步: 将视频分割为音频和视频同步的片段。这对于音视频处理和同步播放很重要。
- 时间戳标记: 在视频中标记时间戳,以便在视频中进行时间导航和检索。
时域分割可以帮助提高对视频内容的理解和处理效率,同时有助于应用中特定任务的实现,如视频摘要、检索和分析
什么是动作分割?
动作分割是指在视频序列中检测和分割出不同的动作或活动。这种技术通常用于视频内容分析、行为识别和视频监控等领域。动作分割的目标是将视频流划分成具有相似运动特征的时间段,从而使得每个时间段内的动作相对一致。
动作分割的步骤可能包括:
- 动作检测: 在视频中识别和检测运动。这可以通过分析视频帧之间的像素变化、光流(运动中的像素变化方向和速度)等来实现。
- 运动特征提取: 从检测到的运动中提取特征,以便描述和区分不同的动作。这些特征可以包括运动的方向、速度、幅度等。
- 相似性度量: 衡量不同时间段内运动特征的相似性,以确定何时动作发生了变化。这可以通过计算特征向量之间的距离或相似性度量来完成。
- 分割决策: 基于相似性度量,决定何时在视频序列中进行动作的分割。分割点表示不同的动作或活动开始或结束。
动作分割的应用包括视频编辑、智能监控系统、视频检索和内容理解。通过对视频进行动作分割,系统可以更有效地理解视频中的内容,提取关键信息,并为后续的分析和处理提供基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号