
sql学习笔记
去年自己用过sql server 2000来从一个表中查询一些阀门、管件的数据,并生成出一张子表。稍微接触了些sql查询语句,但如今需要更全面地学习,因此作笔记如下。
参考链接:
1.b站视频,链接https://www.bilibili.com/video/av9004349/?p=3
2.w3school教程,链接http://www.w3school.com.cn/sql/index.asp
3.知乎讨论,链接https://www.zhihu.com/question/19552975
一、sql server 2012
Microsoft SQL Server Management Studio即管理界面,是数据库服务器和开发人员(比如你本人)之间的一个交互界面,GUI界面交互比全命令交互对于开发人员显然更加友好、便捷。而这个管理界面本身跟数据库服务器是两回事,即有没有这个管理界面,只要数据库服务器启动了,别人都可以访问你的数据库。因此,Management Studio是辅助我们开发的一个工具。
二、创建数据库、表
两种方式,1.界面方式;2.代码(脚本)方式。
界面方式:
字段类型:
int,bit,datetime,decimal,char/nchar/varchar/nvarchar,后面3个都是字符串类型。带n代表unicode的编码,所有字符占1个字符,不带n代表非unicode编码,英文1个字符,中文2个字符。带var代表长度可变,如姓名;不带var代表长度固定,如手机号。能用固定的尽量用固定的。
创建完数据库、表后,我们要添加表中各列的约束,这就是一个数据库的设计过程。现实中的仓库(储物)、保险柜(储钱)都要经过设计,大型、中型乃至家庭装修工程也都是需要经过设计的,当然数据库(储数据)也是要经过设计的。
约束有主键、非空、唯一、默认、检查、外键【给关系(列)加的约束称作外键约束】这几种。
外键是对关系所作的有效性检查,有关系的前提下,可以做也可以不做外键约束,为了保证数据的有效性,一般我们做外键。
外键的添加逻辑:首先分析(表与表)有没有关系,有关系再创建关系列,(为了保证有效性)再在关系列上添加外键约束。
在数据库中,我们只关心表和表之间的关系的类型,一对一,一对多,多对多,至于关系是什么,是父子、共轭、继承、引用、包含等等,我们并不关心,不去加以考虑。万事万物之间的关系有很多很多种,千万不要因为自己认识的关系的有限性导致自己认为关系就那么一两种。我们说关系型数据库,关系不是我们在别的学科别的问题里面说的那种关系,比如数学里面相等、互为相反、相互垂直等等,我们根本不关心那些方面,我们关心的是这个关系是几对几的。
面向对象编程里面,继承的关系是很重要的,但万事万物的关系并不只有继承关系,只不过面向对象的核心思想是继承,不要把关系认为是继承,它是为了实现代码重用和多态。
例:学生表的班级编号是由班级表的班级编号决定的,学生表是外键表,班级表是主键表。因此:谁的值是由谁决定的,第一个谁是外键表,第二个谁是主键表。
脚本操作:
目的:学习了命令操作数据库后,就不一定需要SSMS这个界面工具了。
特点:不区分大小写,字符串使用单引号,末尾不需要加分号
select语句是用的最多,变化也最多的。
--单行注释,/**/多行注释
点击新建查询,可以调出脚本编辑界面。alt+x直接执行所有脚本,选中单行再点击上方工具栏的执行,即可单独执行那一行脚本(推荐使用)。
use master 使用master数据库
create database dbtest 新建数据库
drop database dbtest 删除数据库
三、增、改、删语句insert,update,delete/truncate
insert UserInfo(UserName,UserPwd) values('alex','123456')为指定列赋值
insert into ClassInfo values('金'),('水'),('木'),('火'),('土') 这是批量插入的方法
update UserInfo set UserPwd = 'admin' 更改数据,为所有行的指定列修改
update UserInfo set UserPwd = 'admin' WHERE UserId>1 更改数据,为指定行的指定列修改,where的作用是进行行筛选
delete from ClassInfo where ClassId >3删除后,重新inert into ClassInfo values('气'),发现该行编号是6(而非4),因此delete后系统维护的ClassId在继续往下数。
truncate table UserInfo 清空,将原来表的设置重置了,又重新从1开始计数
四、查询语句select
select * from UserInfo ui 显示表UserInfo中的所有内容,并给起别名
select UserName from UserInfo只显示表UserInfo中的UserName列
select top 2 percent * from UserInfo 显示表UserInfo中的前2%行,至少一行
select top 5 * from UserInfo order by UserId asc, cId desc 显示表UserInfo中的前5行,并按UserId列升序排列,并按cId列降序排列
select distinct cId from UserInfo 消除重复的cId行,只显示不重复的cId
select * from UserInfo where cId = 2 只返回表UserId中的cId=2的行,where表示条件查询,行筛选。单个=号就表示相等了,其余比较运算符与一般的编程语言一致。
select * from ScoreInfo where ScoreValue between 60 and 80 筛选表ScoreInfo中ScoreValue列的值在60到80之间的那些数据。between...and用于连续取值的列。
select * from StudentInfo where cId in (1,3)班级编号为1或3的学生信息,用in关键字
select * from StudentInfo where cId=1 or cId=3班级编号为1或3的学生信息,逻辑运算符and,or,not
select * from StudentInfo where studentId between 3 and 8 and cId=1 取学生编号在3~8之间的在1班的学生
连接查询:当所要查询的东西来自于多张表时,要用到连接查询。怎么用连接查询?规则是:需要的数据在哪些表里?这些表之间是什么关系?然后再按语法写查询。
select * from StudentInfo as si inner join ClassInfo as ci on si.cId=ci.cId 内连接查询表StudentInfo和表ClassInfo中的内容,以cId为连接关系,StudentInfo全显示,ClassInfo部分显示,on之后的条件满足的数据才显示。
select * from StudentInfo as si inner join ClassInfo as ci on si.cId=ci.cId where ci.cTitle='青龙',比上一行多了where用于行筛选
select * from StudentInfo as si left join ClassInfo as ci on si.cId=ci.cId左连接,也即左外连接,left outer join,指返回的结果里面多了左表中特有而右边没有的数据。
select * from StudentInfo as si right join ClassInfo as ci on si.cId=ci.cId右连接,也即右外连接,同上。
多表查询的分析方法:数据在哪些表中,表之间的关系是什么,最后按照语法写脚本。
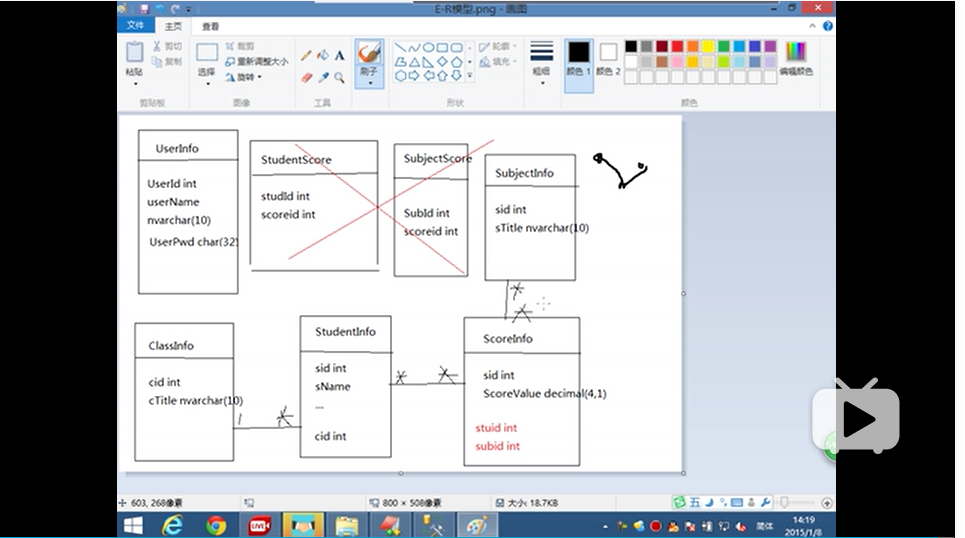
以下从班级找到学生找到成绩,最后找到科目
select * from ScoreInfo as score
inner join StudentInfo as stu on score.stuId=stu.sId
inner join SubjectInfo as sub on score.subId=sub.sId
inner join ClassInfo as class on stu.cId=class.cId 只要这些表中找到一个关系,这句inner join语句就可以写出来,此处class表不一定非得和score表产生关系。
有多少张表,就用多少个join,有多少个关系,就用多少个on.(此句描述有些粗略)
查询例子例题:(数据库、表采用https://blog.csdn.net/qaz13177_58_/article/details/5575711/)
问题1:查询“男”教师及其所上的课程。
我的查询:select a.tname,a.tsex,course.cname from teacher a where a.tsex='男'
inner join course on a.tno=course.TNO
正确查询:select a.tname,a.tsex,course.cname from teacher a
inner join course on a.tno=course.TNO
where a.tsex='男'
分析:where语句应该放置所有inner join(连接)语句后。
问题2:查询Score表中至少有5名学生选修的并以3开头的课程的平均分数。
正确查询:select avg(degree),cno from score where cno like '3%' group by cno having count(sno)>=5
加粗体部分是后面的知识点。
聚合函数:对行数据进行合并
avg,sum,count,min,max
select count(*) as count1 from StudentInfo查询所有行的行数,*代表所有列,也可以用列名代替
select count(*) as count1 from StudentInfo where cid=1查询班级为1班的行的行数
分组:根据指定列进行分组
group by 列名1,列名2...
聚合函数一般结合分组使用,对分组内的数据进行统计
分组后条件筛选:having...
例:统计男女生人数
select count(*),sGender from StudentInfo group by sGender,注意:goup by 后只能看到'男'/'女'sGender这一列,其它的已经看不到了。比如:
select count(*),sPhone from StudentInfo group by sGender就会报错,你取谁的电话号码?8个男生的信息,2个女生的信息已经合并在一起了,电话等信息被屏蔽了,所以这样取是取不到的。
总结:分组之后某些信息被屏蔽了,而分组依赖的信息是可以公布出来的。
例:查询score中选学一门以上课程的同学中分数为非最高分成绩的记录。
select * from score a where a.degree not in (select max(b.degree) from score b group by b.cno) and a.sno in (select c.sno from score c group by c.sno having count(cno)>1)
注意,上述not in 和in不能改为!=和==,因为紧跟着的括号中的select子句返回的不只是一个值。having也不能改为where,固定搭配使然。
分组本身就是按照某一列进行行的合并的操作。因此select count(*),max(sAge) from StudentInfo group by sGender是可以的,因为max()聚合函数也是对行进行操作。
select avg(scoreValue) from scoreInfo group by subId求所有科目的平均分
开窗函数over()
和聚合函数、排名函数写在一起来用,将统计出来的数据分布到原表的每一行中。
select ScoreInfo.*,AVG(scoreValue) from ScoreInfo where subId = 1,会报错,需要改为:select ScoreInfo.*,AVG(scoreValue) over() from ScoreInfo where subId = 1
例1:统计学生编号大于2的各班级的各性别的学生
select cId,sGender,count(*) from StudentInfo
where sId>2
group by cId,sGender
例2:统计学生编号大于2的各班级的各性别的学生人数大于3的信息
select cId,sGender,count(*) from StudentInfo
where sId>2 and count(*)>3(此处错误,因为该count(*)位于group by语句之前,也就是说统计了原来所有的数据,显然不对)
group by cId,sGender
正确写法:
select cId,sGender,count(*) from StudentInfo
where sId>2
group by cId,sGender having count(*)>3(注意,是对分组后的数据(含cId,sGender,count(*)3列的数据)进行筛选)
查询语句总结
select distinct top n *
from t1 join t2 on ... join t3 on ...
where...
group by... having...
order by...
五、联合查询Union
作用:对查好的多个结果数据集进行行的连接。前提:1.结果集列数要一致;2.对应列的数据类型一致。
union,union all,except,intersect
六、备份数据:
备份数据,新表为test1
select * into test1 from student 未有表test1
insert into test2(cTitle) select cTitle from classInfo已有表test1
类型转换:
select CAST(89.000000 as decimal(4,1)),将89.00000->89.0
select CONVERT(decimal(4,1),89.000000),同上,CONVERT可以对目标字符串设置样式。
后续可以参考:
https://zhuanlan.zhihu.com/p/42008396
七、Python的pymssql模块
参考:https://jingyan.baidu.com/article/d45ad14857168e69552b801f.html,https://blog.csdn.net/sqlserverdiscovery/article/details/53490100,
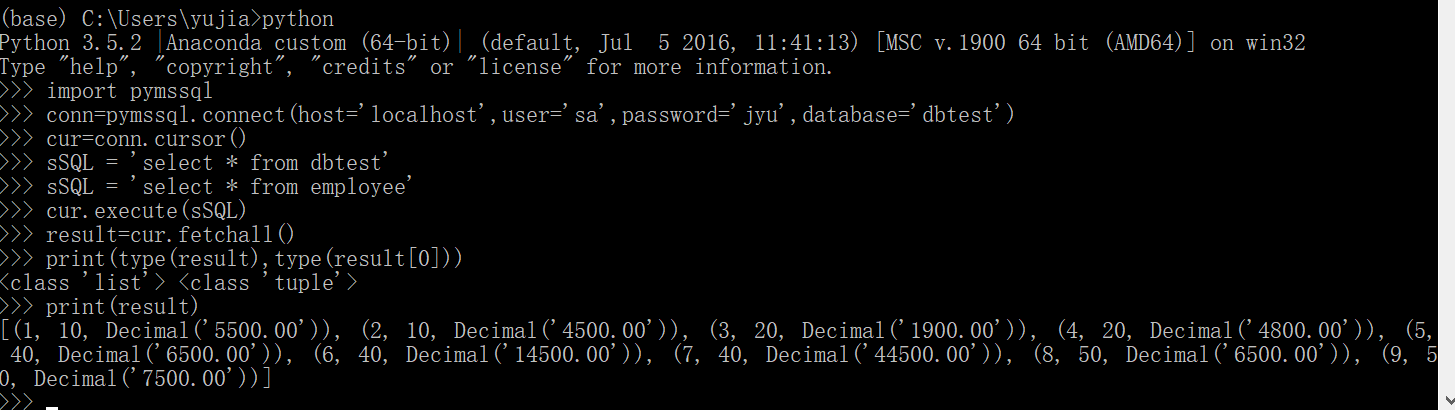
(2)打开cursor,执行sql
(3)通过cursor获取数据,具体可以是一次获取所有数据,也可以是一次获取一行。
整个结果集是元组列表,就是list类型的,而每一条记录是一个tuple,也就是元组。
(4)如果是增、改数据,必须就要调用commit()函数来提交事务,否则程序已退出,数据库里的数据不会有变化。
(5)最后要用close关闭连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号