
个人项目
软件工程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程 |
| 这个作业要求在哪里 | 作业要求 |
github
如何使用? :terminal输入java -jar out/artifacts/SoftwareHomework_jar/SoftwareHomework.jar
(使用相对路径运行)(内置了输入用例)
psp2.1
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | 估计这个任务需要多少时间 | 80 | 90 |
| Development | 开发 | ||
| · Analysis | 需求分析 (包括学习新技术) | 250 | 270 |
| · Design Spec | 生成设计文档 | 130 | 120 |
| · Design Review | 设计复审 | 40 | 55 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 50 | 60 |
| · Design | 具体设计 | 130 | 140 |
| · Coding | 具体编码 | 150 | 160 |
| · Code Review | 代码复审 | 50 | 65 |
| · Test | 测试(自我测试,修改代码,提交修改) | 190 | 220 |
| Reporting | 报告 | ||
| · Test Report | 测试报告 | 100 | 110 |
| · Size Measurement | 计算工作量 | 30 | 25 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 65 |
| Total | 合计 | 1200 | 1340 |
项目结构
HomeWork [SoftwareHomework]
├── out#运行jar包
│ ├── artifacts
│ │ ├── SoftwareHomework_jar
│ │ │ ├── SoftwareHomework.jar
├── src#项目源文件
│ ├── main
│ │ ├── java
│ │ │ ├── com.cong
│ │ │ │ ├── utils#工具类
│ │ │ │ │ ├── FileUtils.java#读取文件类
│ │ │ │ │ ├── SimHash.java#simhash计算相似度
│ │ │ │ ├── Main.java
│ ├── resources
├── test#测试
│ ├── java
│ │ ├── FileUtilsTest.java
│ │ ├── SimHashTest.java
│ │ ├── orig.txt
│ │ ├── orig_0.8_add.txt
│ │ ├── orig_0.8_del.txt
│ │ ├── orig_0.8_dis_1.txt
│ │ ├── orig_0.8_dis_10.txt
│ │ ├── orig_0.8_dis_15.txt
计算模块接口的设计与实现过程
1. 代码组织结构
本计算模块主要包括以下三个类,每个类具有不同的功能:
SimHash(核心计算类):
- 计算文本的 SimHash 值。
- 计算汉明距离。
- 计算相似度。
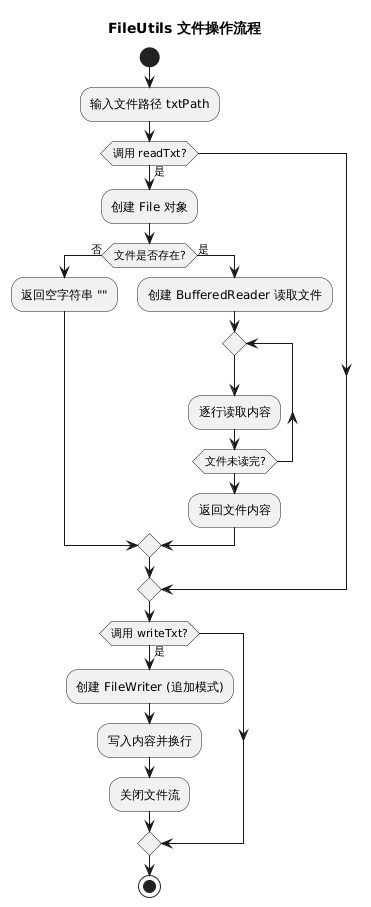
FileUtils(文件处理类):
- 读取文本文件内容。
- 写入文本文件内容。
Main(主程序类):
- 读取原文件及多个待比较文件。
- 计算 SimHash 值。
- 计算相似度并输出结果。
2. 类与函数关系
| 类名 | 主要函数 | 作用 |
|---|---|---|
| SimHash | getHash(String str) |
计算字符串的 MD5 哈希值,并转换为二进制字符串 |
| SimHash | getSimHash(String text) |
计算文本的 128 位 SimHash 值 |
| SimHash | getHammingDistance(String hash1, String hash2) |
计算两个 SimHash 之间的汉明距离 |
| SimHash | getSimilarity(String hash1, String hash2) |
计算两个 SimHash 值的相似度 |
| SimHash | getSimilarityPercentage(String hash1, String hash2) |
计算相似度并返回格式化百分比 |
| FileUtils | readTxt(String txtPath) |
读取指定路径的文本文件 |
| FileUtils | writeTxt(String content, String txtPath) |
向指定路径的文本文件写入内容 |
| Main | main(String[] args) |
主函数,执行 SimHash 计算与相似度比较 |
3. 关键算法解析
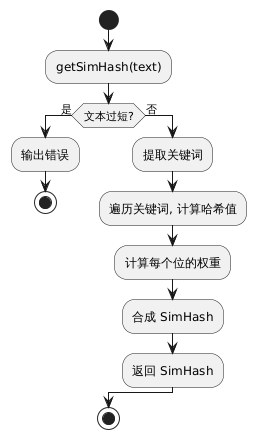
3.1 SimHash 计算过程
- 使用 HanLP 提取文本关键词。
- 计算每个关键词的 MD5 哈希值,并转换为 128 位二进制字符串。
- 统计 128 维特征向量:
- 如果某位为 1,则 +1;否则 -1。
- 生成最终的 SimHash:
- 统计结果大于 0 的位置设为 1,否则设为 0。
3.2 汉明距离计算
- 遍历两个 SimHash 字符串的每一位。
- 计算对应位置不同的个数,即汉明距离。
3.3 相似度计算
- 计算汉明距离。
- 归一化:
相似度 = 1 - (汉明距离 / 128)。
4. 代码实现的独到之处
- 优化关键词提取:使用 HanLP 提取关键词,提高文本特征提取的质量。
- 高效计算 SimHash:使用 128 维权重数组,减少不必要的字符串处理操作。
- 文件处理模块化:
FileUtils使得文件读取和写入更加简洁、复用性强。 - 相似度格式化输出:提供“百分之XX.XX”格式,方便直观理解。
5.流程图
simhash流程
文件读取
性能分析
Cpu flame![]()

内存![]()
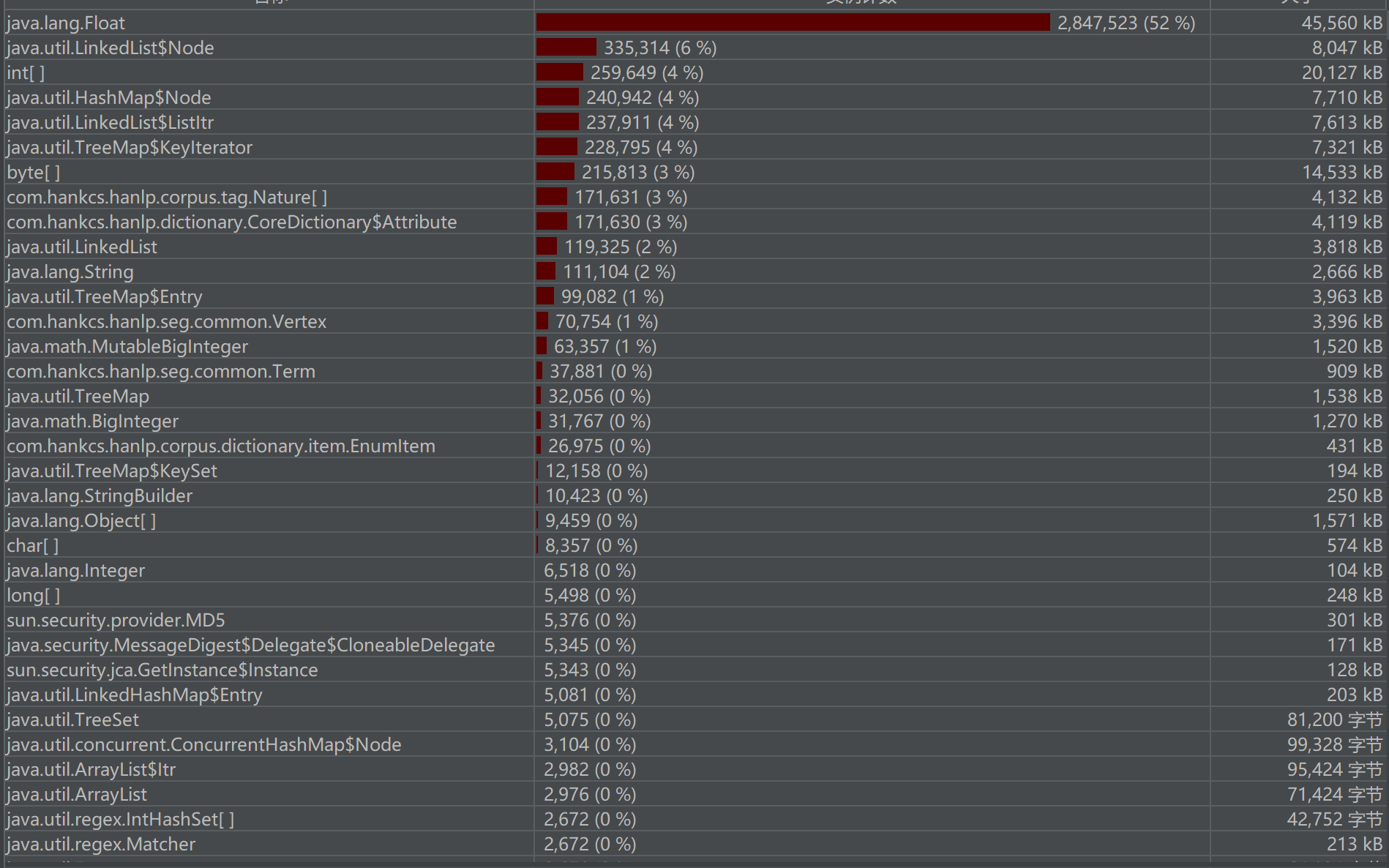
原因
-关键词提取耗时较长:HanLP.extractKeyword(text, text.length()) 处理大文本时,计算量较大,成为瓶颈。
-MD5 哈希计算较慢:getHash(String str) 需要频繁计算 MD5,可能存在优化空间。
-汉明距离计算存在冗余:getHammingDistance(String hash1, String hash2) 逐位比较时未做优化。
改进思路
-减少关键词提取时间:只提取 固定数量的关键词(如 Math.min(text.length(), 20)),而非 text.length() 个。使用缓存,避免对相同文本重复计算关键词。
-优化哈希计算:采用 更快的哈希算法(如 MurmurHash 代替 MD5),减少 CPU 计算开销。
在 SimHash 计算过程中,避免重复哈希相同的关键词。
-优化汉明距离计算:使用 位操作(Integer.bitCount(xorResult))计算不同位数,替代逐位遍历。
计算模块部分单元测试展示
1. 单元测试代码
1.1 单元测试FileUtils
import com.cong.utils.FileUtils;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class FileUtilsTest {
private final String testFilePath = "testFile.txt";
@BeforeEach
void setup() throws IOException {
Files.deleteIfExists(Path.of(testFilePath)); // 确保每次测试前文件不存在
}
@AfterEach
void tearDown() throws IOException {
Files.deleteIfExists(Path.of(testFilePath)); // 测试后清理文件
}
@Test
public void testReadTxt_ValidFile() throws IOException {
Files.writeString(Path.of(testFilePath), "Hello World!", StandardCharsets.UTF_8);
String content = FileUtils.readTxt(testFilePath);
assertEquals("Hello World!", content, "文件内容应与预期值匹配");
}
@Test
public void testReadTxt_FileNotExist() {
String content = FileUtils.readTxt("nonexistent.txt");
assertEquals("", content, "不存在的文件应返回空字符串");
}
@Test
public void testWriteTxt_AppendsContent() throws IOException {
FileUtils.writeTxt("First Line", testFilePath);
FileUtils.writeTxt("Second Line", testFilePath);
String content = Files.readString(Path.of(testFilePath), StandardCharsets.UTF_8);
assertTrue(content.contains("First Line"), "文件应包含第一行内容");
assertTrue(content.contains("Second Line"), "文件应包含第二行内容");
}
}
1.2 单元测试SimHash
import com.cong.utils.SimHash;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertNotEquals;
public class SimHashTest {
@Test
public void testGetSimHash_NonEmptyForValidText() {
String text = "今天是星期天,天气晴朗,我去看电影。";
String simHash = SimHash.getSimHash(text);
assertNotEquals("", simHash);
assertEquals(128, simHash.length());
}
@Test
public void testGetHammingDistance_SameHashes() {
String identical = "1".repeat(128);
int distance = SimHash.getHammingDistance(identical, identical);
assertEquals(0, distance);
}
@Test
public void testGetSimilarity_SameHashes() {
String hash = "1".repeat(128);
double similarity = SimHash.getSimilarity(hash, hash);
assertEquals(1.0, similarity, 0.0001);
}
@Test
public void testGetSimilarityPercentage_Format() {
String hash1 = "1".repeat(128);
String hash2 = "0".repeat(128);
String percent = SimHash.getSimilarityPercentage(hash1, hash2);
assertEquals("百分之0.00", percent);
}
}
2. 测试数据构造思路
测试点
- 正常情况:测试文件读取、文本相似度计算等核心功能是否正确执行。
- 边界情况:如空文本、超长文本、特殊字符等输入的处理情况。
- 异常情况:如文件不存在、数据格式错误等。
构造方式
- 采用手动编写测试数据,如 和 作为测试用例。
"Hello World!"``"你好,世界!" - 对于 SimHash,使用固定长度 128 位哈希值,测试不同汉明距离的影响。
3. 测试覆盖率截图
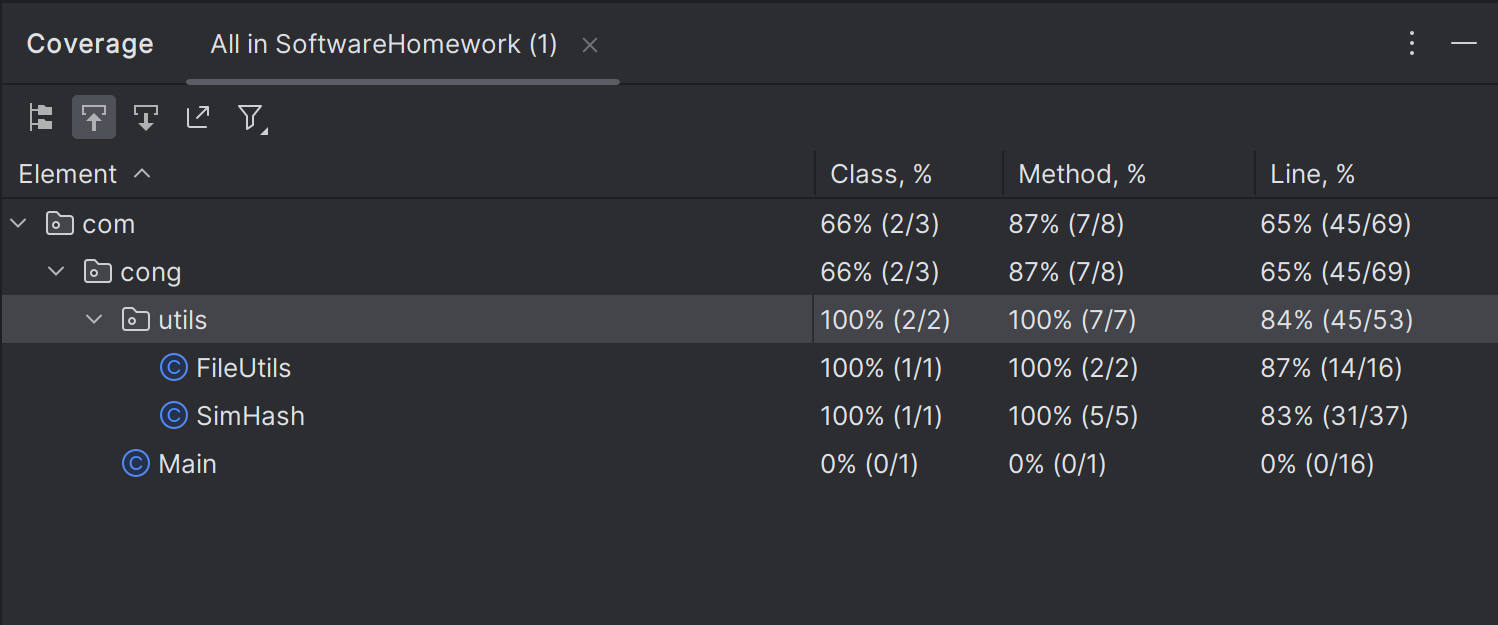
4.测试截图![]()
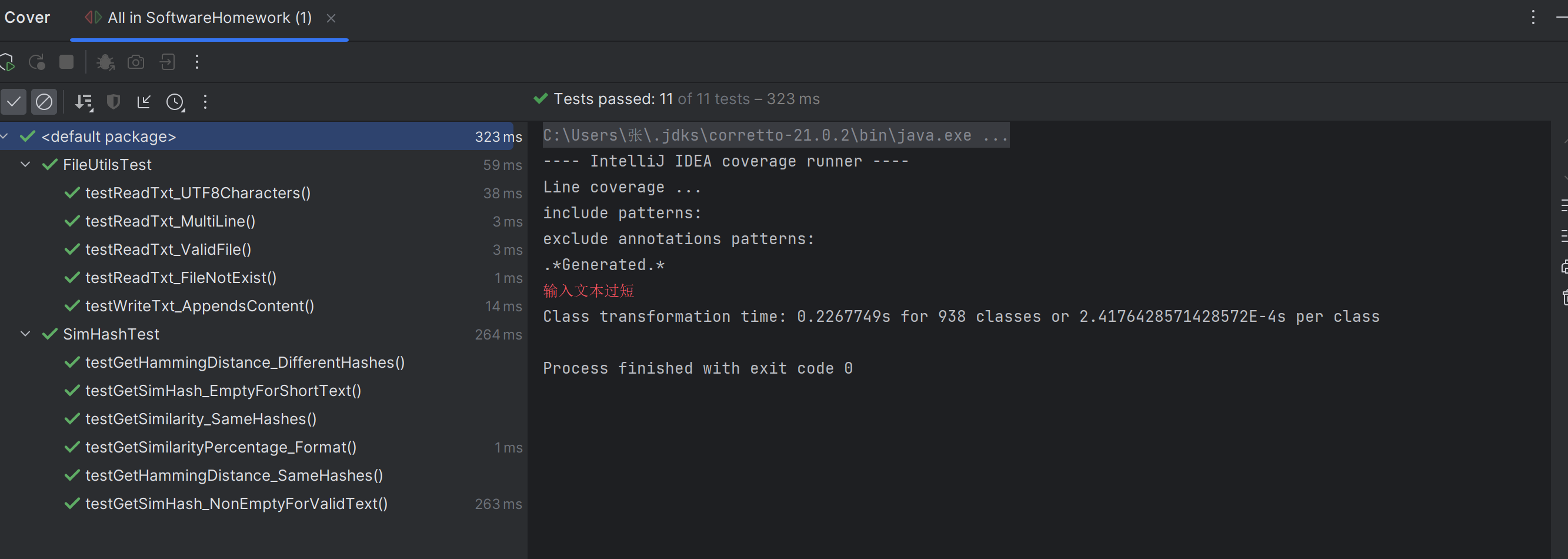
计算模块部分异常处理说明
1. 设计目标
在计算模块中,我们可能会遇到以下异常情况:
- 文件不存在异常:用户尝试读取一个不存在的文件。
- 文本输入为空异常:SimHash 计算时,输入文本为空。
- 无效哈希值异常:计算汉明距离时,输入的哈希值格式错误。
2. 异常单元测试示例
2.1 文件不存在异常
java复制编辑@Test
public void testReadTxt_FileNotExist() {
String content = FileUtils.readTxt("nonexistent.txt");
assertEquals("", content, "不存在的文件应返回空字符串");
}
错误场景:用户提供了一个不存在的文件路径。
2.2 空文本异常
java复制编辑@Test
public void testGetSimHash_EmptyForShortText() {
String text = "";
String simHash = SimHash.getSimHash(text);
assertEquals("", simHash, "空文本应返回空哈希值");
}
错误场景:SimHash 计算时输入的文本为空。
2.3 无效哈希值异常
java复制编辑@Test
public void testGetHammingDistance_InvalidHash() {
String hash1 = "abc"; // 非 128 位二进制字符串
String hash2 = "1".repeat(128);
assertThrows(IllegalArgumentException.class, () -> {
SimHash.getHammingDistance(hash1, hash2);
}, "无效哈希值应抛出异常");
}
错误场景:计算汉明距离时,输入的哈希值格式不正确。
github记录
方法局限性说明
尽管该计算模块能够有效计算文本的 SimHash 值并进行相似度比较,但仍然存在一些局限性:
-
对短文本处理效果有限:
- SimHash 依赖文本特征的分布,短文本可能无法形成足够的特征向量,导致哈希值不稳定。
- 在
testGetSimHash_EmptyForShortText例子中,过短文本返回空哈希值,可能影响后续计算。
-
无法处理语义相似度:
- SimHash 仅基于关键词和哈希计算相似度,不考虑语义信息。例如,"我去看电影" 和 "我去电影院" 可能具有不同的 SimHash 值。
-
汉明距离计算存在误差:
- SimHash 计算基于二进制位,计算汉明距离时未考虑词频或权重变化,因此在某些文本类型下可能导致误差。
-
对文本修改的鲁棒性不足:
- 如果文本只修改了少量高权重词语,SimHash 可能会发生较大变化,导致相似度计算不准确。
-
文件处理的错误恢复能力有限:
FileUtils.readTxt()仅返回空字符串,而不是抛出异常,可能导致用户误以为文件内容为空,而不是文件缺失。
-
对于超长文本计算性能受限:
- 由于 SimHash 计算需要对文本进行关键词提取和哈希转换,超长文本处理可能会导致计算时间增加。
- 解决方案可以是采用分块计算 SimHash 或使用局部敏感哈希(LSH)优化大规模文本对比。
5. 未来优化方向
针对上述局限性,可以考虑以下优化方案:
- 改进短文本处理:使用 NLP 方法对短文本进行扩展,使其能形成稳定特征。
- 引入语义分析:结合 Word2Vec 或 BERT 提升语义理解能力,避免仅靠关键词匹配。
- 优化汉明距离计算:在计算汉明距离时考虑词频和权重,提升相似度计算精度。
- 增强异常处理机制:区分文件不存在与文件为空的情况,提高文件操作的可靠性。
- 提升计算效率:采用哈希索引或并行计算方式优化超长文本 SimHash 计算速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号