OO第一单元总结
OO第一单元总结
一、基于度量分析程序结构
1.类图分析

因为三次作业是一一迭代的过程,同时我的程序在类图方面三次作业区别不大,就只放第三次作业的图了。总的来看,整个程序的框架还是很清楚的,利用递归下降法,从而使用expression-term-factor的树状结构来对表达式的每一个单元进行存储,而进行到第三次作业后,factor又可以细分出sin,cos等因子。此外Function类对自定义函数提前进行解析。虽然结构清晰比较有层次,但我在某些方法上没有做更好的细化,导致其行数很高,内聚性较低,这也是我日后在程序架构时要特别注意的问题。
2.框架分析
1.第一次作业
俗话说万事开头难,虽然第一次作业无需处理嵌套括号和自定义函数,但是要在一周之内要实现从无到有,构建一个解析多项式的程序,对我来说仍是个挑战。整体思路上我采用了递归下降法,从expression中解析term,再从term中解析factor,从而构建一个表达式的树状存储结构。
而在整个构建过程中我碰到的第一个难点便是拆括号,由于两个表达式因子相乘展开会产生许多新的项,因此我在Term这个类里面新增了ArrayList <Term>的容器,专门存储两个表达式因子展开后的项。
而第二个难点是对因子的解析提取,如何判断因子的类型,我采用了正则表达式+捕获组的方法.在存储方面我对常数因子和变量型因子进行统一处理,用“系数+指数”的方式对其进行表示。
在优化方面,由于第一次作业仍未涉及到三角函数,因此优化角度较少,我所做的优化也仅仅是将项中多余的“1”给抹去,以及进行项内部和项之间的合并同类项处理。由于我的容器是用ArrayList,因此在合并时使用两个for循环找到同类型对象进行合并,比较简单粗暴。
2.第二次作业
第二次作业在第一次作业的基础上新增了对三角函数和自定义函数的处理。因此我新增了Sin和Cos两个类对三角函数进行解析存储。由于三角函数的内部只能是常数或变量因子,因此对该类型进行合并同类项操作也较为简单,只需一一判断三角内部的因子以及外部的指数是否达到合并条件即可。
自定义函数方面我新建了一个Function类对该类型进行解析。虽然助教建议采用先对函数进行解析后代入因子的方法,但由于我一开始便使用replace替换,并且验证该方法可行,便没再改了。值得注意的是由于自定义函数自变量为x/y/z,而在表达式中仅会出现x变量,因此在替换时要先对x替换。同时应对替换因子添加括号,避免一些bug。
由于我在replace中多加了一层括号,这便要求我的程序要拥有处理嵌套括号的功能,我在括号展开的方法中加入的递归操作,从而便具备了展开嵌套括号的功能。同时在表达式匹配方面由于嵌套括号的出现,难以找到一个适配与所有情况的正则表达式,因此我在正则匹配前先对表达式进行预处理,识别每个左括号对应的右括号,在对括号内部进行正则匹配,大大减少了正则表达式的长度以及出现bug的概率。
优化方面,我没有进行三角函数公式形式的优化,还是采用了第一次作业的优化方式,对同类型的因子以及项进行合并操作,思路大致相同。
3.第三次作业
由于我在第二次作业便加入了处理嵌套阔号的功能,其实第三次作业便已经完成了一半了。由于三角函数内新增了表达式因子这一类型,其实对我们程序的优化带来了麻烦。如何判断两个带有表达式因子的三角函数相同,我利用toString方法返回表示表达式因子的字符串,若相同便可对二者进行合并。但这一方法的缺陷便是需要实现对因子先进行排序操作,在进行字符串比较,程序复杂度提高了不少。
3.经典OO度量
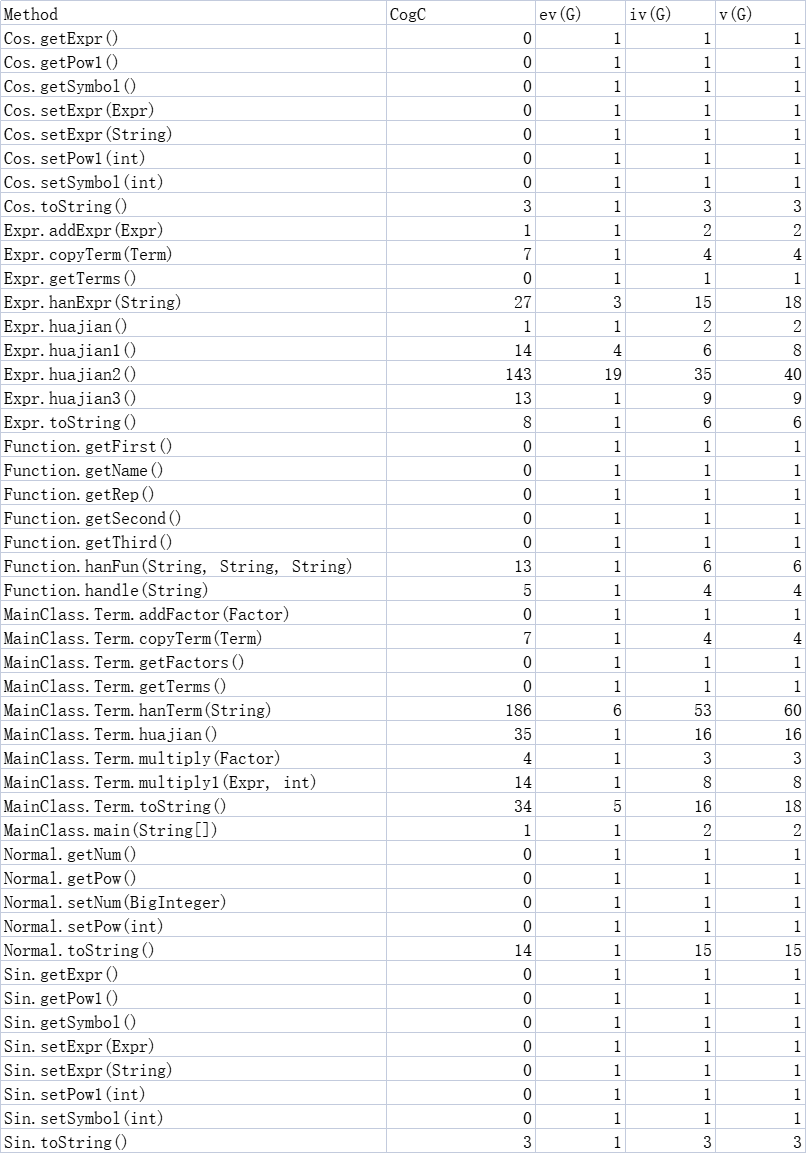

可以看到,在提取因子的方法hanTerm以及项与项之间的合并同类项方法huajian2的行数极高,主要是因为要考虑到多种因子情况进行分类讨论并处理。后来细想其实可以将处理的过程交给别的方法,将方法的功能更集中在识别判断因子类型上,从而提高程序的内聚性,同时也使得类的功能实现更加灵活。
4.代码规模
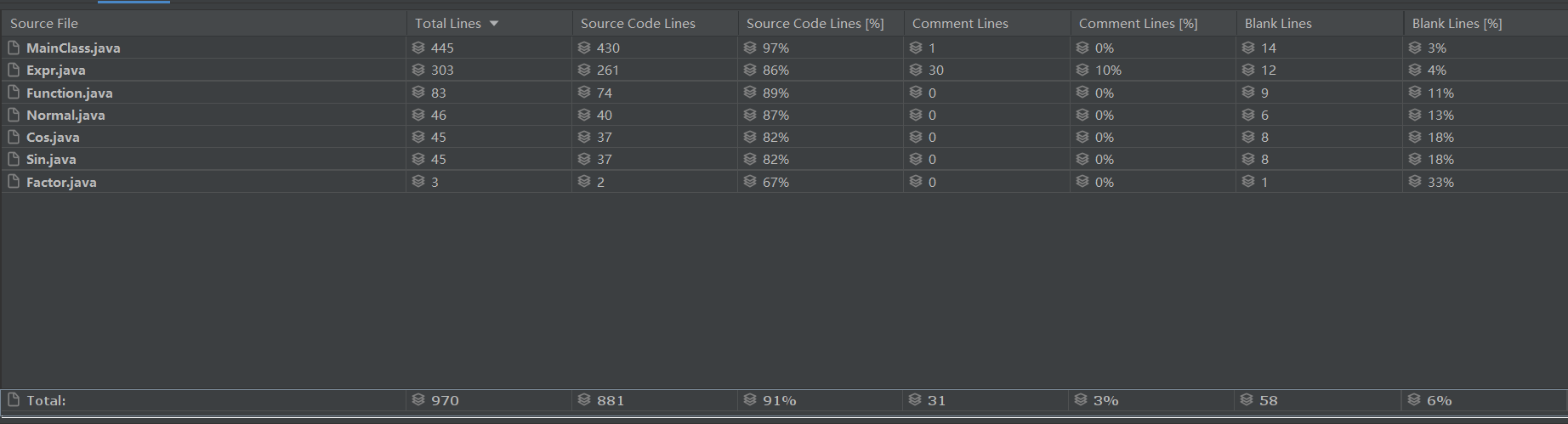
这次作业由于没有在类上进行细分,导致某些类的代码量极高,也算是长教训了。之后也反思到某些类的方法其实可以移植到其它类中,使整个架构的功能分配更加合理。
二、分析自己的bug
1.sum函数的上下标问题
万万没想到就这么一个简单的东西便导致了我两个bug:一个是未考虑到上下标可以是负数以及携带符号,知道导致正则匹配的时候出现异常;而另一个是上下标可以为大数,从而超过int存储范围。
总结:唉,归根结底还是审题不清,没有意识到上下标的边界问题,仅仅把他当成两个简单的正整数处理。
2.sum函数的替换问题
上文说到,我在自定义函数为了避免bug便给替换因子又套了一层括号,但是在对sum函数进行操作时本以为替换者为常数因子,无需进行括号添加,而忽视了i**2这一特殊情况。
总结:因此,在进行特殊类型处理时一定要考虑全面,不要想当然。
3.toString函数的处理
在toString函数输出字符串时我会视情况进行抹“1”操作,但是我忘记考虑“-1”的情况,在进行抹“1”操作时未删去其后面带有的“*”从而出现“-*x”这种尴尬情况。
总结:其实在处理“1”时我便已考虑到要抹去“*”的情况,但未举一反三,想到“-1”也该如此,因此在调试过程中若debug不应该仅仅是见招拆招,而是从架构层面分析bug出现的原因,不仅找到浮于表面的bug,还要找到与之相关的隐藏bug。
三、分析寻找bug的策略
1.自测策略
在自测方面主要还是考虑从因子角度出发,进行多种因子类型的组合,而组合方式考虑普通的加减乘除以及嵌套,比如三角函数里面套三角。
同时也考虑因子的边界条件,比如常数因子和变量因子的系数可能是大数等。
符号处理,由于表达式的特殊性导致正负号可能会出现在很多奇怪的地方,在自测的时候主要考虑“负负得正”的情况,在项,表达式,以及三角函数内部等添加负号等操作来进行检测。
考虑特殊情况,比如0的生成,构造合并同类项后结果为0的情况,检测程序的合并功能是否完善。
2.互测策略
互测时主要还是广撒网,先测一些在自测中自己出现bug的样例,若命中则先看对方代码中出现bug的位置,在进行分析看是否会出现其他bug。
同时互测时也会询问他人是否有强测数据点,团队作战。
四、架构设计体验及心得
这次作业也算是我写的第一个比较大的Java工程。从寒假刚学习完有关面向对象的一些基本理念到开学第一周就要写一个Java工程,说实话挺崩溃的,一整个懵了的状态。初步敲定整个架该怎么写,到每个方法的具体实现,都挺磕磕绊绊的,有时还碰到一些莫名其妙的bug,比如调试和运行结果不一致,某个对象的属性莫名其妙变了,属实心态爆炸。不过也通过问助教和同学一点点地发现和解决问题(感谢亲爱的助教和舍友们!!),最后看到中测的点全部AC也算是真切感受到付出的努力没有白费。
在后面的增量开发过程中得益于之前架构逻辑也比较清晰,第二三周的工作量相对第一周就比较少了,不过也碰到了一些之前埋下的坑。万事开头难,也算是深刻认识一个好的架构会为之后后面的增量开发减少许多工作量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号