
[论文笔记]Toward Characteristic-Preserving Image-based Virtual Try-On Network
这篇论文在VTION基础上进行了改进,提出两个模块GMM与Try-On,能够将服装转换为适合目标人物的体型,并保留服装的细节(例如纹理、标志、刺绣等)。作者在论文中提到,该论文主要有四大贡献:
(1)提出了一种新的虚拟试穿网络CP-VTON(Characteristic-Preserving image based Virtual Try-On Network),解决了在真实的虚拟试穿情况下面临的在大空间变形时的服装细节的保留问题。
(2)通过GMM模块整合了全学习的TPS,用来获得更健壮和更强大的对齐图像。
(3)在给定对齐图像的基础上,通过Try-On模块来动态合并渲染结果与变形结果。
(4)CP-VTON网络的性能已经在Han等人收集的数据集上进行了证明。
一、Motivation
该论文将基于图像的虚拟试穿任务看作一个 image-conditioned generation 问题,而之前的条件图像生成工作无法满足虚拟试穿中“在保留目标服装细节的情况下将服装转换为适合目标人物的体型”这一关键要求,于是作者提出了一个网络CP-VTON,它通过几何匹配模块GMM,将目标服装转换为适合目标人物体型的形状,之后,通过Try-On模块将变形后的服装与人物整合并渲染整合后的图像,从而有效解决该关键要求。
二、CP-VTON
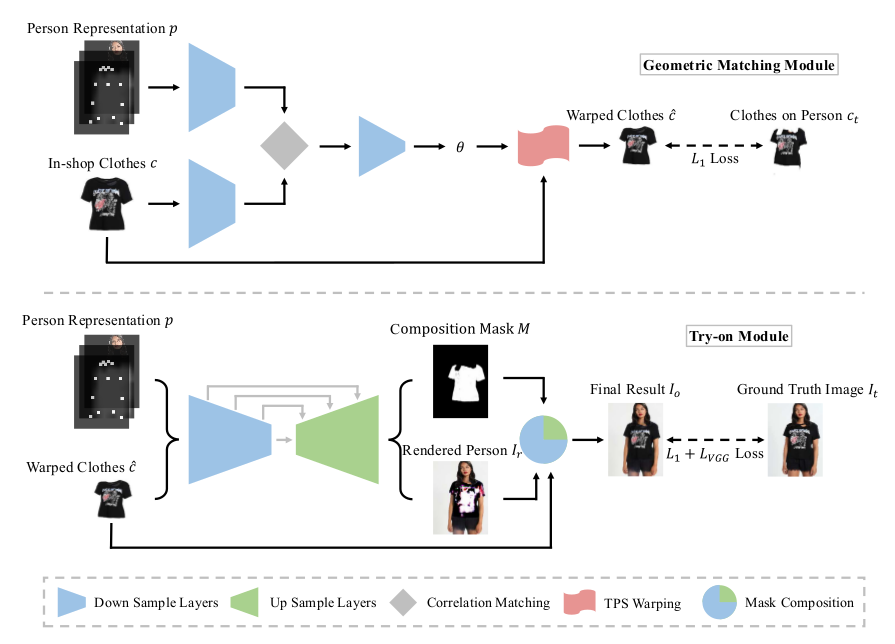
CP-VTON的网络结构:
(一)Person Representation
网络的输入之一人物表示 $p$ 由三个部分组成,分别是:
(1)Pose heatmap:一个$18$通道的特征图,每个通道对应一个人体姿势关键点(绘制为$11\times11$的白色矩形)。
(2)Body shape:一个$1$通道的 blurred binary mask 特征图,能够粗糙地包括人体的不同部位。
(3)Reserved regions:一个包括面部和头发的RGB图像,用来维持人物身份(保证生成的是同一个人)。
以上三个部分的特征图都被缩放到 $256 \times192$ 大小,并连接在一起组成 $k=18+1+3=22$ 通道的人物表示图 $p$ 。
(二)GMM
GMM是一种用 pixel-wise L1 loss 训练的端到端神经网络,用来将输入服装 $c$ 与人物表示 $p$ 对齐,并产生扭曲的服装图像 $\hat{c}$。
GMM由四部分组成:
(1)两个分别用于提取 $p$ 和 $c$ 的高级特征的网络。
(2)Correlation Matching:将两个高级特征组合为单个张量的相关层,作为回归网络的输入。
(3)用于预测空间变换参数 $\theta$ 的回归网络。
(4)TPS Warping:将图像变形为输出 $\hat{c} = T$$_\theta$$(c)$ 。
网络的连接是端到端的,使用一个三元组 $(p, c, c$$_t$$)$ 进行训练,其中$c$$_t$为ground truth。这一部分的损失函数为:
$\mathcal{L}$$_G$$_M$$_M$$(\theta)$$=\parallel$$\hat{c}$$-$$c$$_t$$\parallel$$_1$$=\parallel$$T$$_\theta$$(c)-c$$_t$$\parallel$$_1$
(三)Try-On
在Try-On模块中,将人物表示 $p$ 与扭曲的服装图像 $\hat{c}$ 连接作为输入到U-Net中,经过encoder-decoder得到粗糙的合成图像 $I$$_r$,并预测了一个Composition Mask $M$,之后,使用 $M$ 将 $I$$_r$ 和 $\hat{c}$ 融合在一起,得到最终的结果 $I$$_o$ 。其中 :
$I$$_o$$=M$ $\odot$ $\hat{c}+(1-M)\odot I$$_r$
$\odot$ 代表element-wise矩阵乘法。
网络使用三元组 $(p,c,I$$_t$$)$ 进行训练,训练的目标是最小化网络输出 $I$$_o$ 与 ground truth $I$$_t$ 之间的差异,损失函数为L1 loss与VGG感知损失的组合,其中VGG感知损失的定义是:
$\mathcal{L}$$_{VGG}$$(I$$_o$$,I$$_t$$)$ $=$ $\sum\limits_{i=1}^5$ $\lambda$$_i$ $\parallel\phi$$_i$$(I$$_o$$)$ $-$ $\phi$$_i$$(I$$_t$$)\parallel$$_1$
其中,$\phi$$_i(I)$ 表示在预训练的VGG19网络中第 $i$ 层的图像 $I$ 的特征图( $i\ge{1}$ 的层分别代表‘conv1_2’,‘conv2_2’,‘conv3_2’,‘conv4_2’,‘conv5_2’)。为了保持服装的细节,作者使用L1正则 $\parallel{1}$ $-$ $M\parallel$$_1$来偏置Composition Mask $M$ ,使得最终的合成图像尽可能多的选择warped clothes。Try-On模块的整体损失为:
$\mathcal{L}$$_{TOM}$ $=$ $\lambda$$_{L1}$$\parallel$$I$$_o$ $-$ $I$$_t$$\parallel$$_1$ $+$ $\lambda$$_{vgg}$$\mathcal{L}$$_{VGG}$$(\hat{I},I)$ $+$ $\lambda$$_{mask}\parallel$$1$ $-$ $M\parallel$$_1$
三、Experiments
(一)Implementation Details
Training Setup:
$\lambda$$_{L1}$ = $\lambda$$_{vgg}$ = $\lambda$$_{mask}$ = 1
steps = 20,000
batch size = 4
input image size = 256 x 192
使用Adam优化,其中 $\beta$$_1$ = 0.5,$\beta$$_2$ = 0.999,学习率在前10,000步为0.0001,之后线性衰减到0。
(二)Test Result
作者的开源代码在这里
测试结果如下:



其中,可能因为作者采用了直接将warped cloth 粘贴到目标人物来生成粗糙合成图像的方法,所以如果模特摆出的姿势对衣服有遮挡,则生成效果比较差:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号