
04 Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
1、Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2、2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
Hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
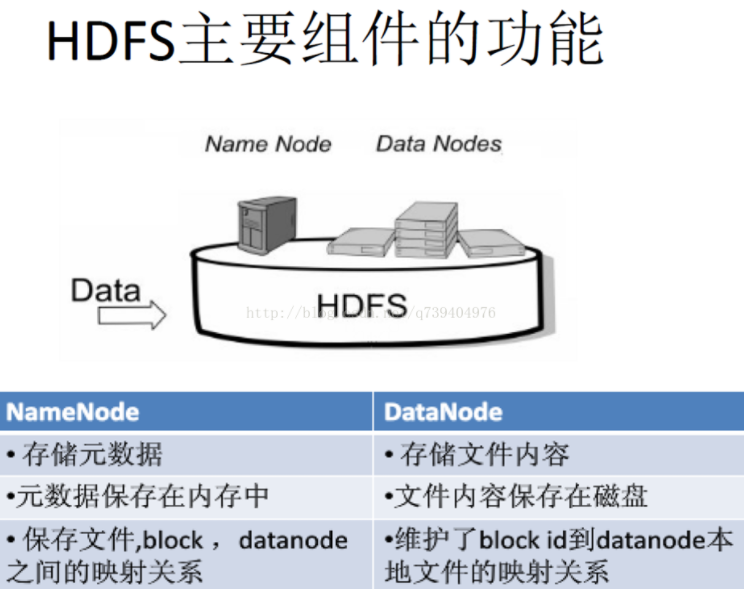
主要功能:
1、HDFS 采用主/从架构,主节点即NameNode 从节点即:DataNode
2、NameNode即是模式, 并完成外模式和模式之间的映像,模式和内模式之间的映像。
3、NameNode存放HDFS全局命名空间,充当全局数据目录;存储全局文件系统树,目录-文件-文件块信息
NameNode存放的数据块信息是在启动时扫描所有数据节点重构;
在运行过程中周期性受到数据节点发送的数据块列表信息重构而得;
4、在客户端读取数据过程中,将数据块和数据节点映射按远近排序列表发送给客户端;
5、在客户端写数据过程中,检查文件是否存在、是否有权限;将待写入文件分成若干文件块,并根据数据节点的繁忙和磁盘容量程度,分配数据块和数据节点对应关系列表反馈给客户端
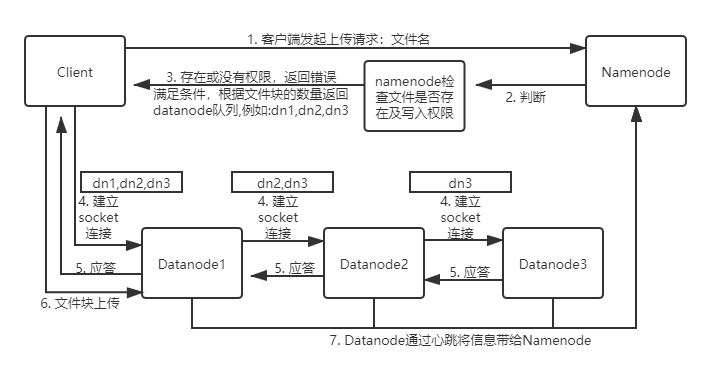
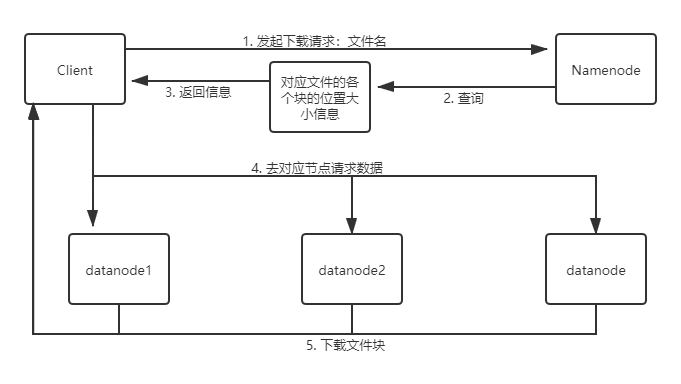
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
![]()
![]()
4.简述HBase与传统数据库的主要区别
1.数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。
2.数据操作:Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库通常有各式各样的函数和连接操作。
3.存储模式:Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,这样的好处是数据即是索引,访问查询涉及的列大量降低系统的I/O,并且每一列由一个线索来处理,可以实现查询的并发处理;传统数据库是基于表格结构和行存储,其没有建立索引将耗费大量的I/O并且建立索引和物化试图需要耗费大量的时间和资源。
4.数据维护:Hbase的更新实际上是插入了新的数据;传统数据库只是替换和修改。
5.可伸缩性:Hbase可以轻松的增加或减少硬件的数目,并且对错误的兼容性比较高;传统数据库需要增加中间层才能实现这样的功能。
6.事务:Hbase只可以实现单行的事务性,意味着行与行之间、表与表之前不必满足事务性;传统数据库是可以实现跨行的事务性。
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
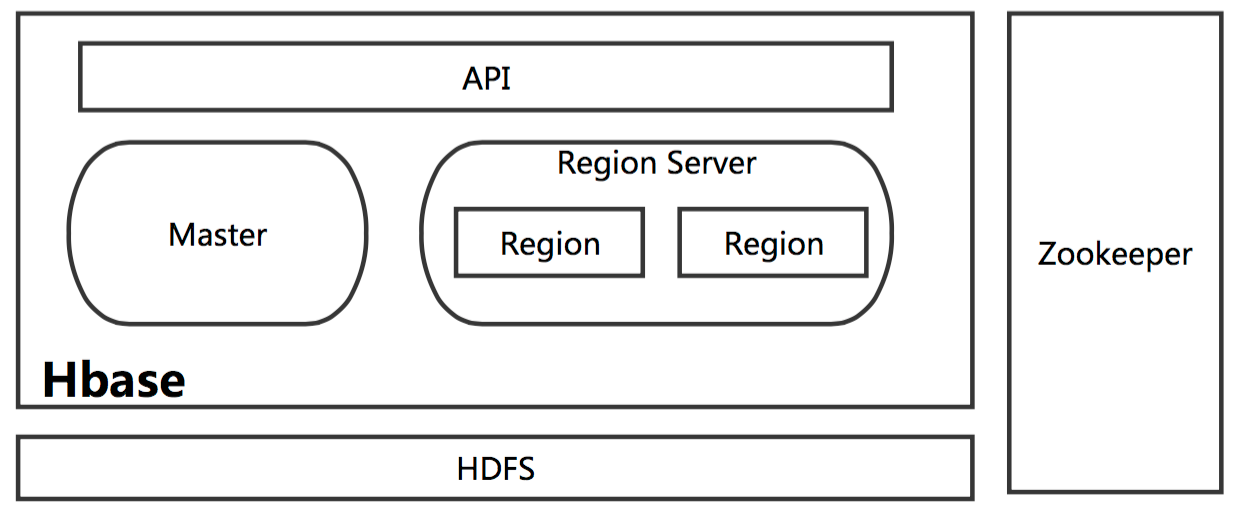
Master主服务器的功能
HBase Master用于协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载。HBaseMaster还有一个职责就是负责分配Region给RegionServer。HBase允许多个Master节点共存,但是这需要Zookeeper的帮助。不过当多个Master节点共存时,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点宕机时,其他的Master则会接管HBase的集群。
Region服务器的功能
对于一个RegionServer而言,其包括了多个Region。RegionServer的作用只是管理表格,以及实现读写操作。Client直接连接RegionServer,并通信获取HBase中的数据。对于Region而言,则是真实存放HBase数据的地方,也就说Region是HBase可用性和分布式的基本单位。如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。
Zookeeper协同的功能
对于 HBase 而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为HBase Master的HA解决方案。也就是说,是Zookeeper保证了至少有一个HBase Master 处于运行状态。并且Zookeeper负责Region和Region Server的注册。其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是HBase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
Client客户端的请求流程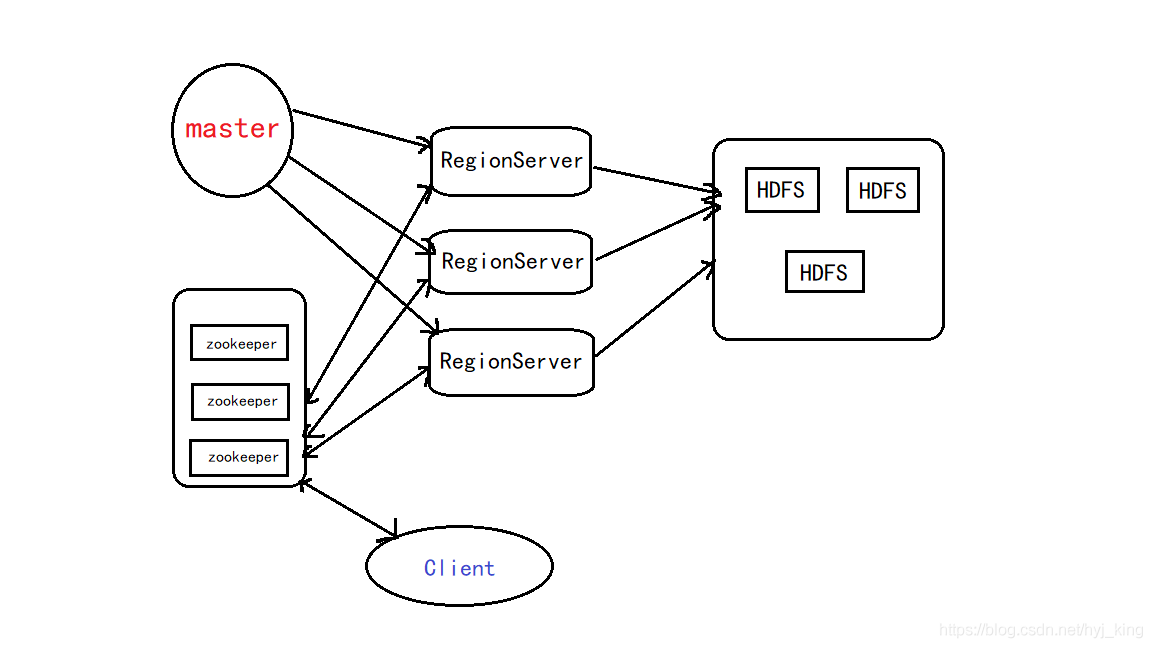
四者之间的关系
1、Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
2、Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
3、客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
4、RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
5、客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
与HDFS的关联
RegionServer保存的数据直接存储在Hadoop的HDFS上
6.完整描述Hbase表与Region的关系,三级寻址原理。
系统如何找到某个row key (或者某个 row key range)所在的region
bigtable 使用三层类似B+树的结构来保存region位置。
第一层: 保存zookeeper里面的文件,它持有root region的位置。
第二层:root region是.META.表的第一个region其中保存了.META.表其它region的位置。通过root region,我们就可以访问.META.表的数据。
第三层: .META.表它是一个特殊的表,保存了hbase中所有数据表的region 位置信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号