从Linux源码看Socket(TCP)的listen及连接队列
从Linux源码看Socket(TCP)的listen及连接队列
前言
笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情。 今天笔者就来从Linux源码的角度看下Server端的Socket在进行listen的时候到底做了哪些事情(基于Linux 3.10内核),当然由于listen的backlog参数和半连接hash表以及全连接队列都相关,在这一篇博客里也一块讲了。
Server端Socket需要Listen
众所周知,一个Server端Socket的建立,需要socket、bind、listen、accept四个步骤。
今天笔者就聚焦于Listen这个步骤。
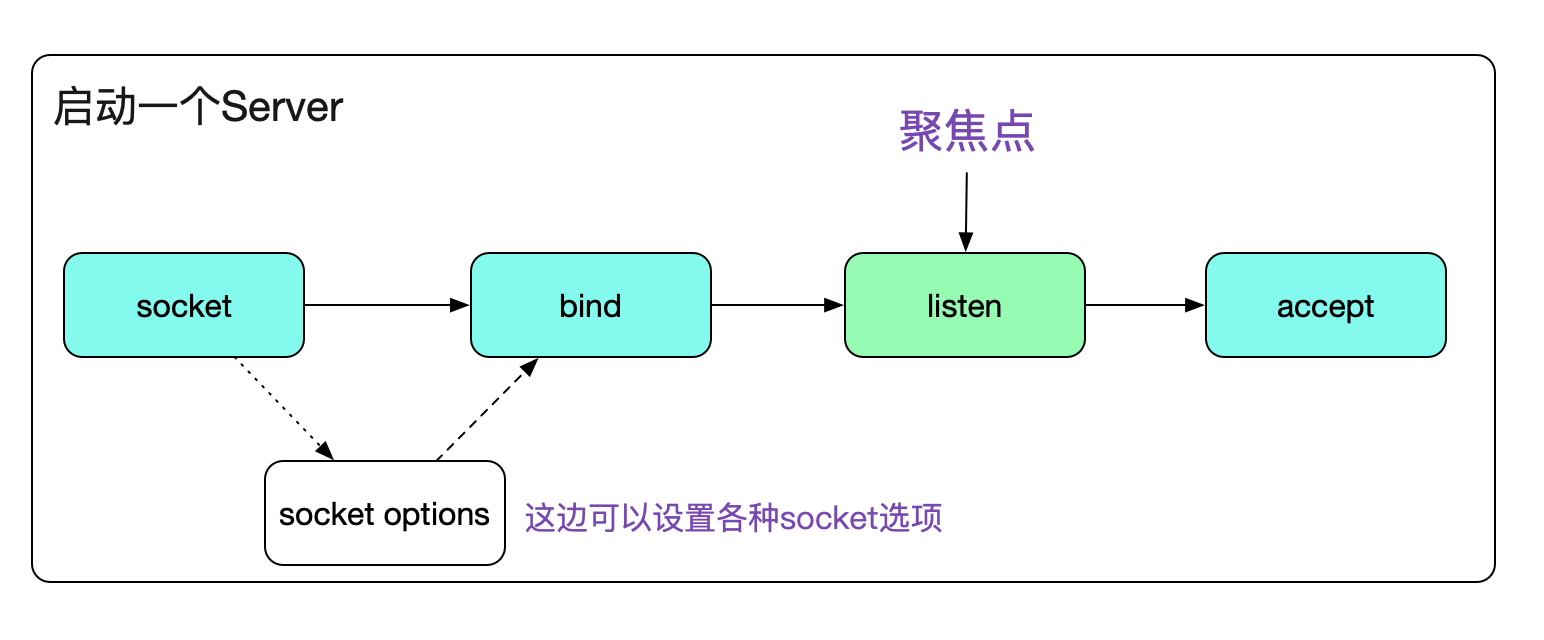
代码如下:
void start_server(){
// server fd
int sockfd_server;
// accept fd
int sockfd;
int call_err;
struct sockaddr_in sock_addr;
......
call_err=bind(sockfd_server,(struct sockaddr*)(&sock_addr),sizeof(sock_addr));
if(call_err == -1){
fprintf(stdout,"bind error!\n");
exit(1);
}
// 这边就是我们今天的聚焦点listen
call_err=listen(sockfd_server,MAX_BACK_LOG);
if(call_err == -1){
fprintf(stdout,"listen error!\n");
exit(1);
}
}
首先我们通过socket系统调用创建了一个socket,其中指定了SOCK_STREAM,而且最后一个参数为0,也就是建立了一个通常所有的TCP Socket。在这里,我们直接给出TCP Socket所对应的ops也就是操作函数。
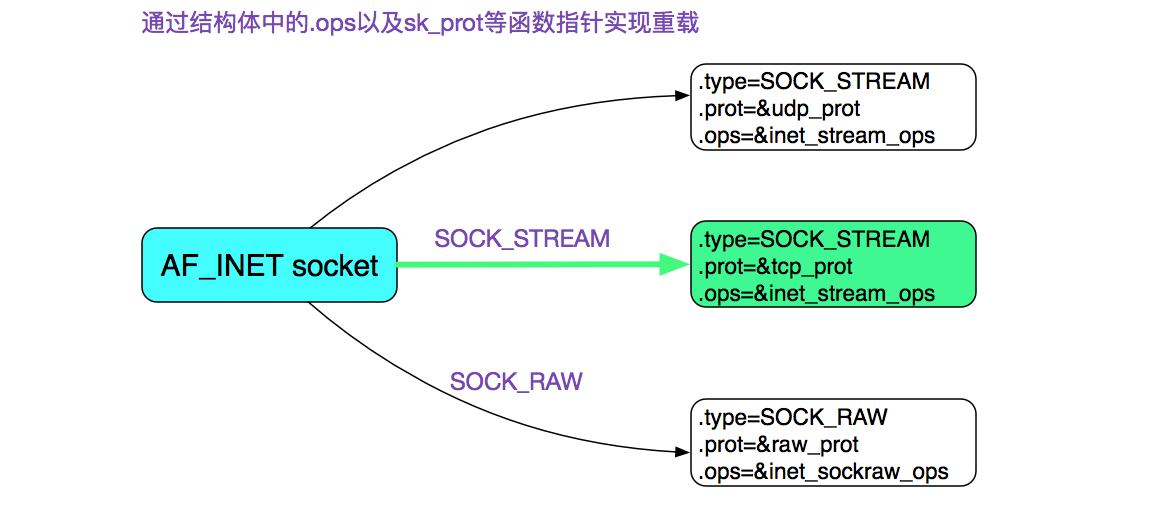
如果你想知道上图中的结构是怎么来的,可以看下笔者以前的博客:
https://my.oschina.net/alchemystar/blog/1791017
Listen系统调用
好了,现在我们直接进入Listen系统调用吧。
#include <sys/socket.h>
// 成功返回0,错误返回-1,同时错误码设置在errno
int listen(int sockfd, int backlog);
注意,这边的listen调用是被glibc的INLINE_SYSCALL装过一层,其将返回值修正为只有0和-1这两个选择,同时将错误码的绝对值设置在errno内。
这里面的backlog是个非常重要的参数,如果设置不好,是个很隐蔽的坑。
对于java开发者而言,基本用的现成的框架,而java本身默认的backlog设置大小只有50。这就会引起一些微妙的现象,这个在本文中会进行讲解。

接下来,我们就进入Linux内核源码栈吧
listen
|->INLINE_SYSCALL(listen......)
|->SYSCALL_DEFINE2(listen, int, fd, int, backlog)
/* 检测对应的描述符fd是否存在,不存在,返回-BADF
|->sockfd_lookup_light
/* 限定传过来的backlog最大值不超出 /proc/sys/net/core/somaxconn
|->if ((unsigned int)backlog > somaxconn) backlog = somaxconn
|->sock->ops->listen(sock, backlog) <=> inet_listen
值得注意的是,Kernel对于我们传进来的backlog值做了一次调整,让其无法>内核参数设置中的somaxconn。
inet_listen
接下来就是核心调用程序inet_listen了。
int inet_listen(struct socket *sock, int backlog)
{
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*if ((sysctl_tcp_fastopen & TFO_SERVER_ENABLE) != 0 &&
inet_csk(sk)->icsk_accept_queue.fastopenq == NULL) {
// fastopen的逻辑
if ((sysctl_tcp_fastopen & TFO_SERVER_WO_SOCKOPT1) != 0)
err = fastopen_init_queue(sk, backlog);
else if ((sysctl_tcp_fastopen &
TFO_SERVER_WO_SOCKOPT2) != 0)
err = fastopen_init_queue(sk,
((uint)sysctl_tcp_fastopen) >> 16);
else
err = 0;
if (err)
goto out;
}
if(old_state != TCP_LISTEN) {
err = inet_csk_listen_start(sk, backlog);
}
sk->sk_max_ack_backlog =backlog;
......
}
从这段代码中,第一个有意思的地方就是,listen这个系统调用可以重复调用!第二次调用的时候仅仅只能修改其backlog队列长度(虽然感觉没啥必要)。
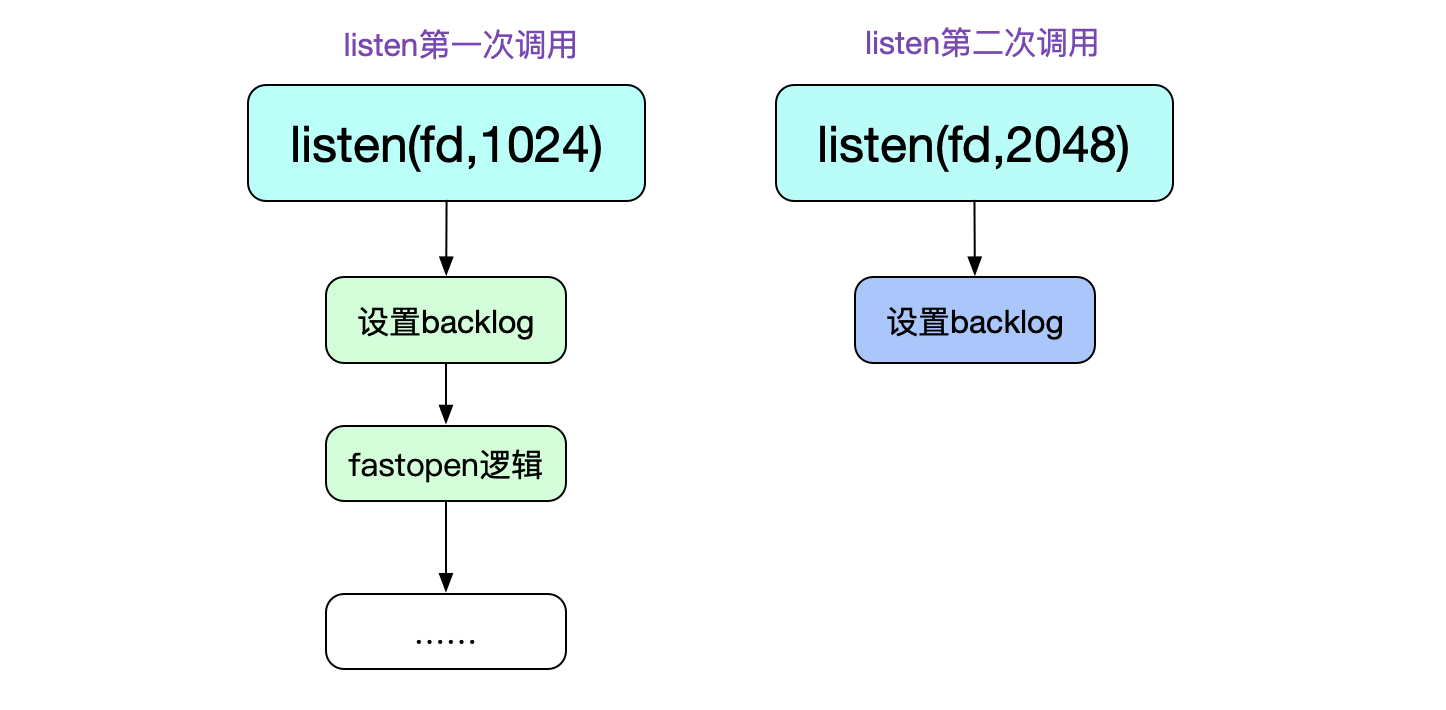
首先,我们看下除fastopen之外的逻辑(fastopen以后开单章详细讨论)。也就是最后的inet_csk_listen_start调用。
int inet_csk_listen_start(struct sock *sk, const int nr_table_entries)
{
......
// 这里的nr_table_entries即为调整过后的backlog
// 但是在此函数内部会进一步将nr_table_entries = min(backlog,sysctl_max_syn_backlog)这个逻辑
int rc = reqsk_queue_alloc(&icsk->icsk_accept_queue, nr_table_entries);
......
inet_csk_delack_init(sk);
// 设置socket为listen状态
sk->sk_state = TCP_LISTEN;
// 检查端口号
if (!sk->sk_prot->get_port(sk, inet->inet_num)){
// 清除掉dst cache
sk_dst_reset(sk);
// 将当前sock链入listening_hash
// 这样,当SYN到来的时候就能通过__inet_lookup_listen函数找到这个listen中的sock
sk->sk_prot->hash(sk);
}
sk->sk_state = TCP_CLOSE;
__reqsk_queue_destroy(&icsk->icsk_accept_queue);
// 端口已经被占用,返回错误码-EADDRINUSE
return -EADDRINUSE;
}
这里最重要的一个调用sk->sk_prot->hash(sk),也就是inet_hash,其将当前sock链入全局的listen hash表,这样就可以在SYN包到来的时候寻找到对应的listen sock了。如下图所示:
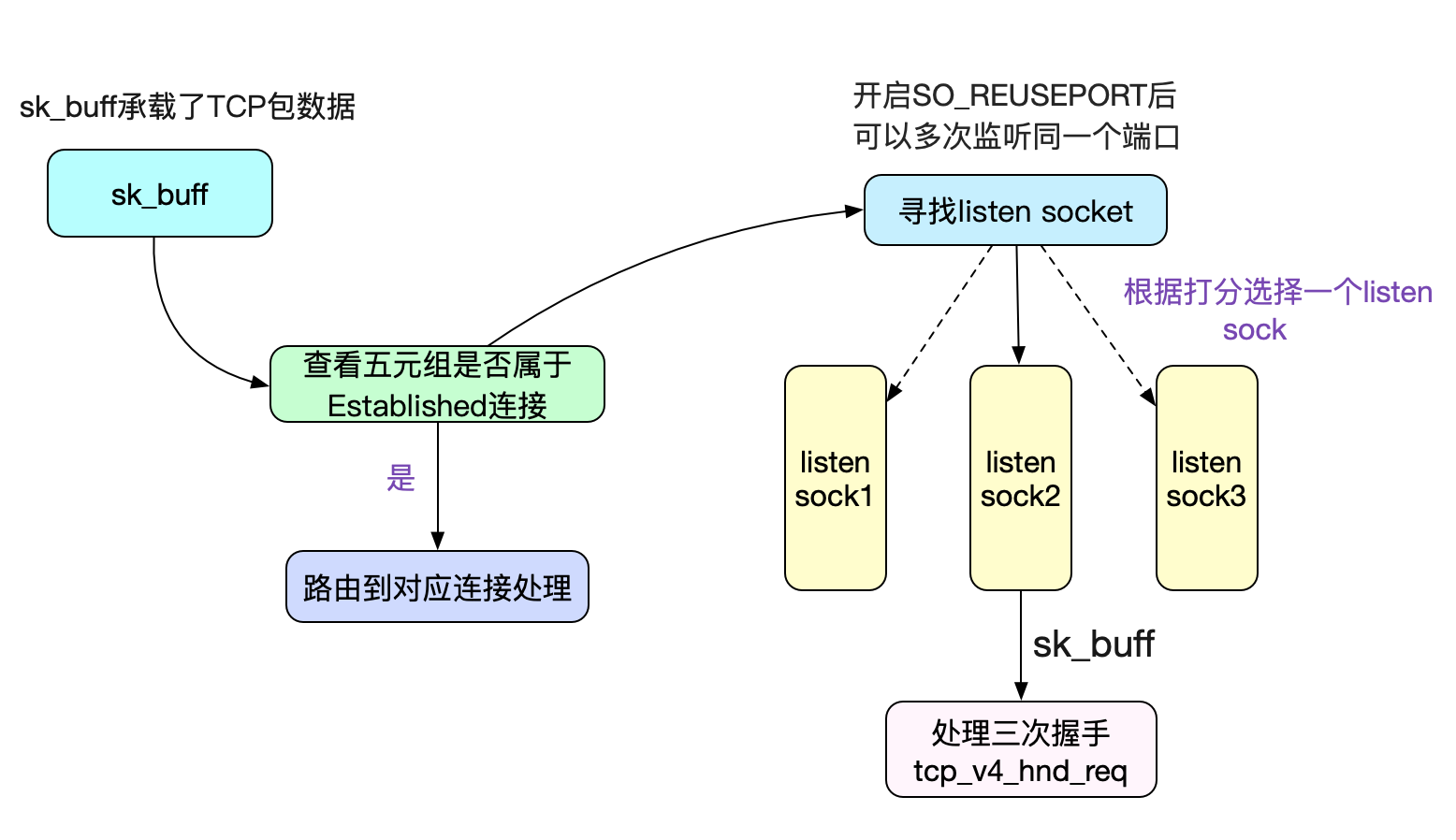
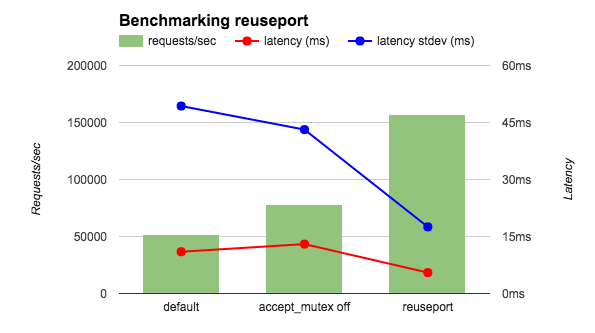
如图中所示,如果开启了SO_REUSEPORT的话,可以让不同的Socket listen(监听)同一个端口,这样就能在内核进行创建连接的负载均衡。在Nginx 1.9.1版本开启了之后,其压测性能达到3倍!
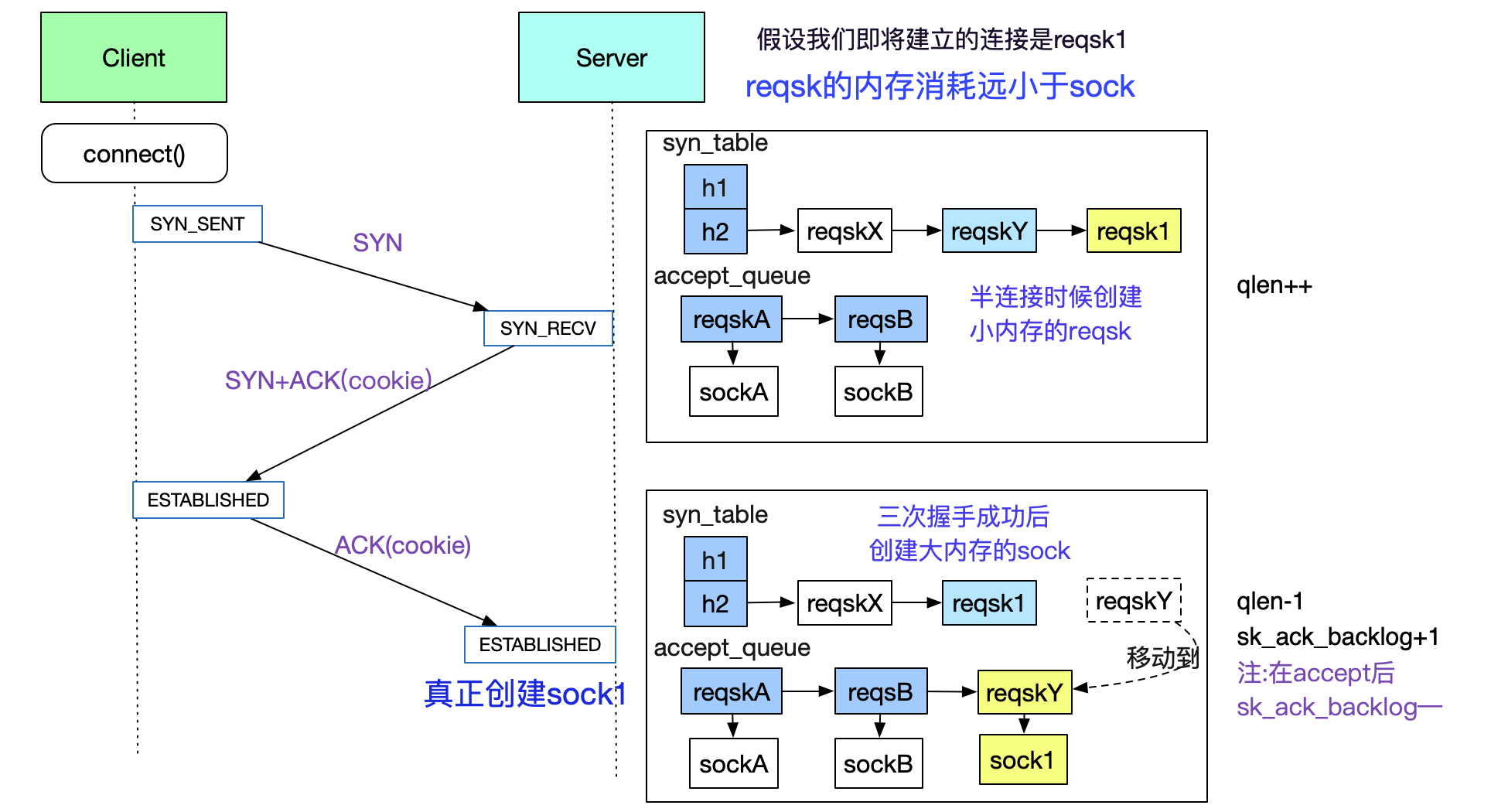
半连接队列hash表和全连接队列
在笔者一开始翻阅的资料里面,都提到。tcp的连接队列有两个,一个是sync_queue,另一个accept_queue。但笔者仔细阅读了一下源码,其实并非如此。事实上,sync_queue其实是个hash表(syn_table)。另一个队列是icsk_accept_queue。
所以在本篇文章里面,将其称为reqsk_queue(request_socket_queue的简称)。
在这里,笔者先给出这两个queue在三次握手时候的出现时机。如下图所示:
当然了,除了上面提到的qlen和sk_ack_backlog这两个计数器之外,还有一个qlen_young,其作用如下:
qlen_young:
记录的是刚有SYN到达,
没有被SYN_ACK重传定时器重传过SYN_ACK
同时也没有完成过三次握手的sock数量
如下图所示:
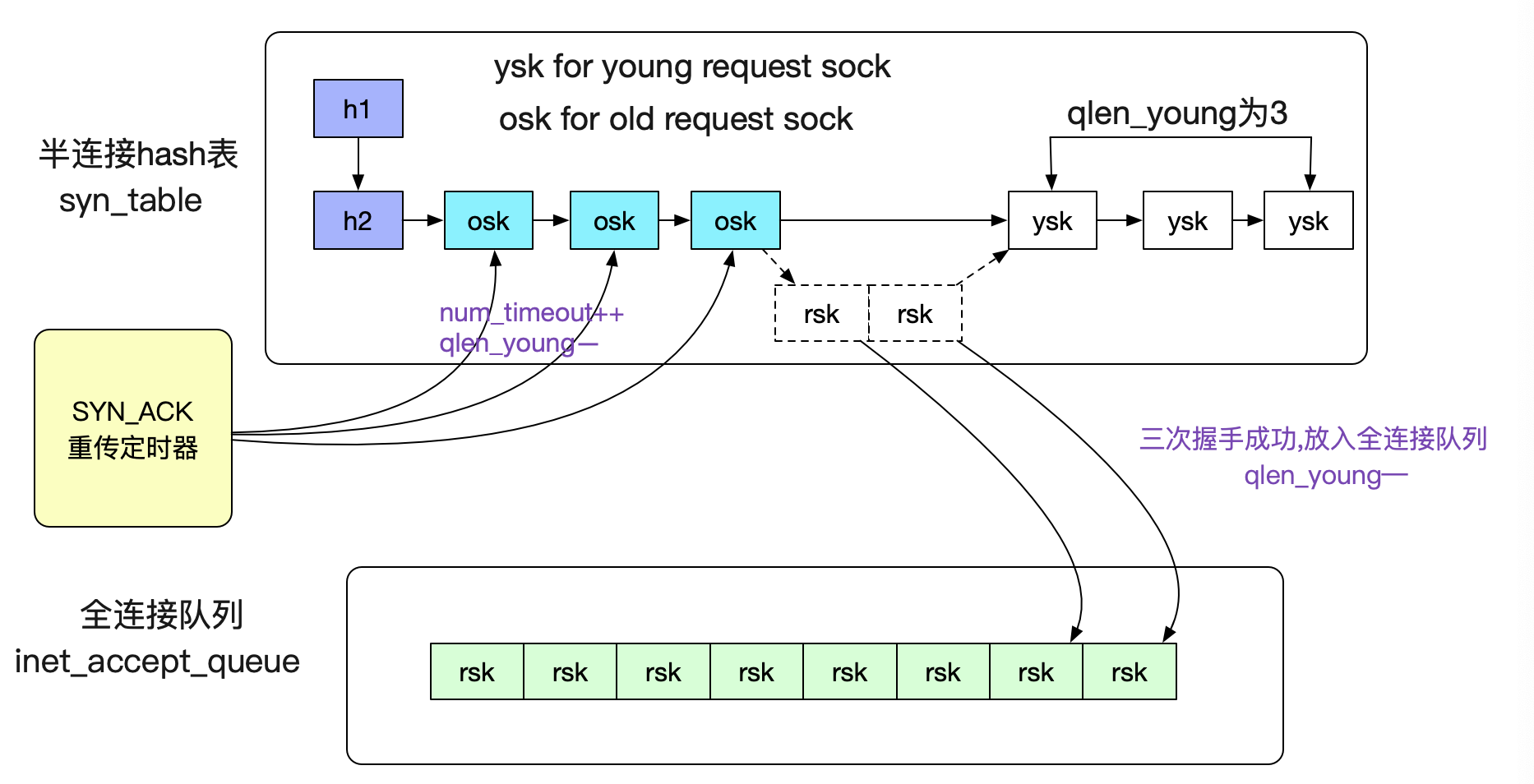
至于SYN_ACK的重传定时器在内核中的代码为下面所示:
static void tcp_synack_timer(struct sock *sk)
{
inet_csk_reqsk_queue_prune(sk, TCP_SYNQ_INTERVAL,
TCP_TIMEOUT_INIT, TCP_RTO_MAX);
}
这个定时器在半连接队列不为空的情况下,以200ms(TCP_SYNQ_INTERVAL)为间隔运行一次。限于篇幅,笔者就在这里不多讨论了。
为什么要存在半连接队列
因为根据TCP协议的特点,会存在半连接这样的网络攻击存在,即不停的发SYN包,而从不回应SYN_ACK。如果发一个SYN包就让Kernel建立一个消耗极大的sock,那么很容易就内存耗尽。所以内核在三次握手成功之前,只分配一个占用内存极小的request_sock,以防止这种攻击的现象,再配合syn_cookie机制,尽量抵御这种半连接攻击的风险。
半连接hash表和全连接队列的限制
由于全连接队列里面保存的是占用内存很大的普通sock,所以Kernel给其加了一个最大长度的限制。这个限制为:
下面三者中的最小值
1.listen系统调用中传进去的backlog
2./proc/sys/inet/ipv4/tcp_max_syn_backlog
3./proc/sys/net/core/somaxconn
即min(backlog,tcp_ma_syn_backlog,somaxcon)
如果超过这个somaxconn会被内核丢弃,如下图所示:
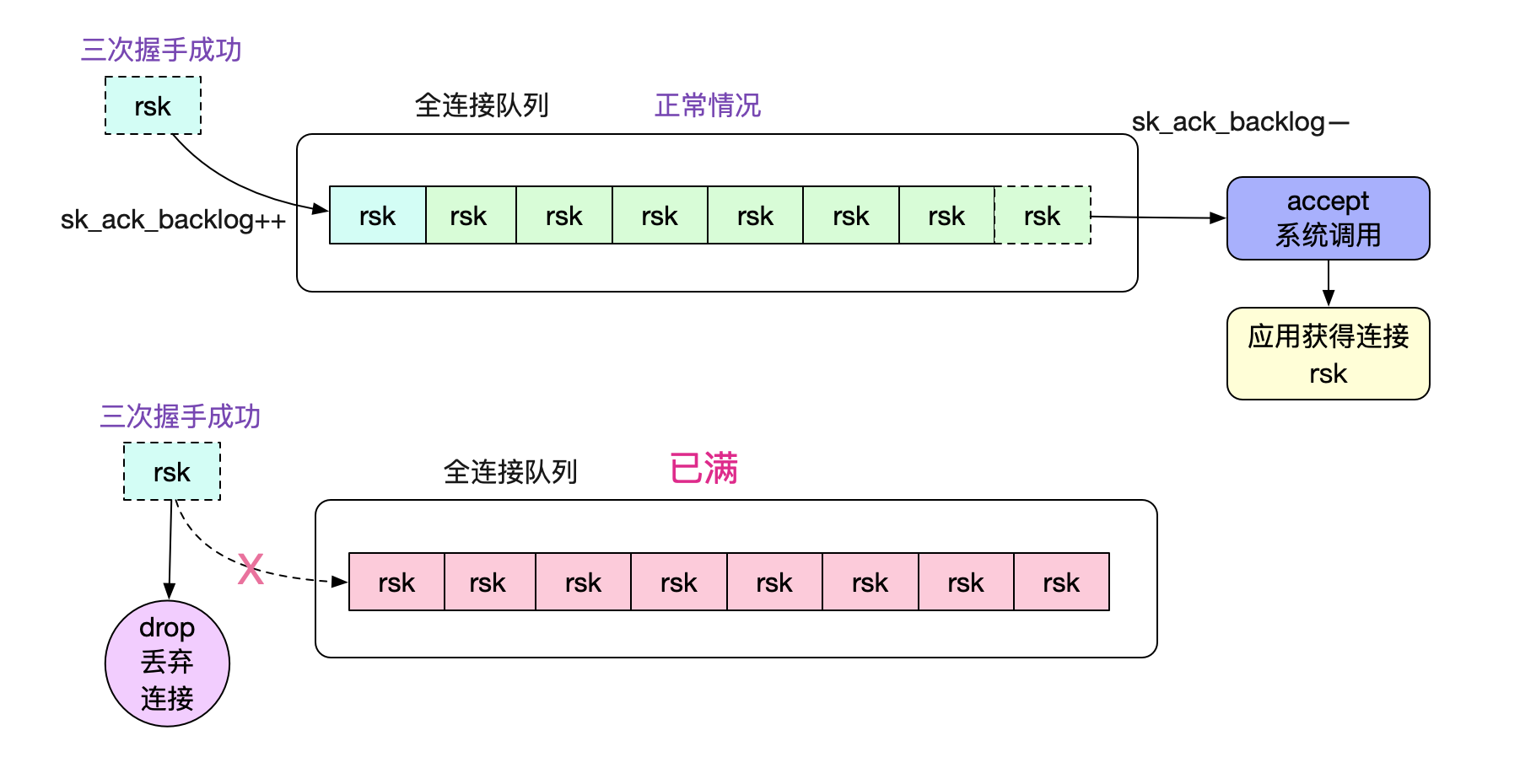
这种情况的连接丢弃会发生比较诡异的现象。在不设置tcp_abort_on_overflow的时候,client端无法感知,就会导致即在第一笔调用的时候才会知道对端连接丢弃了。
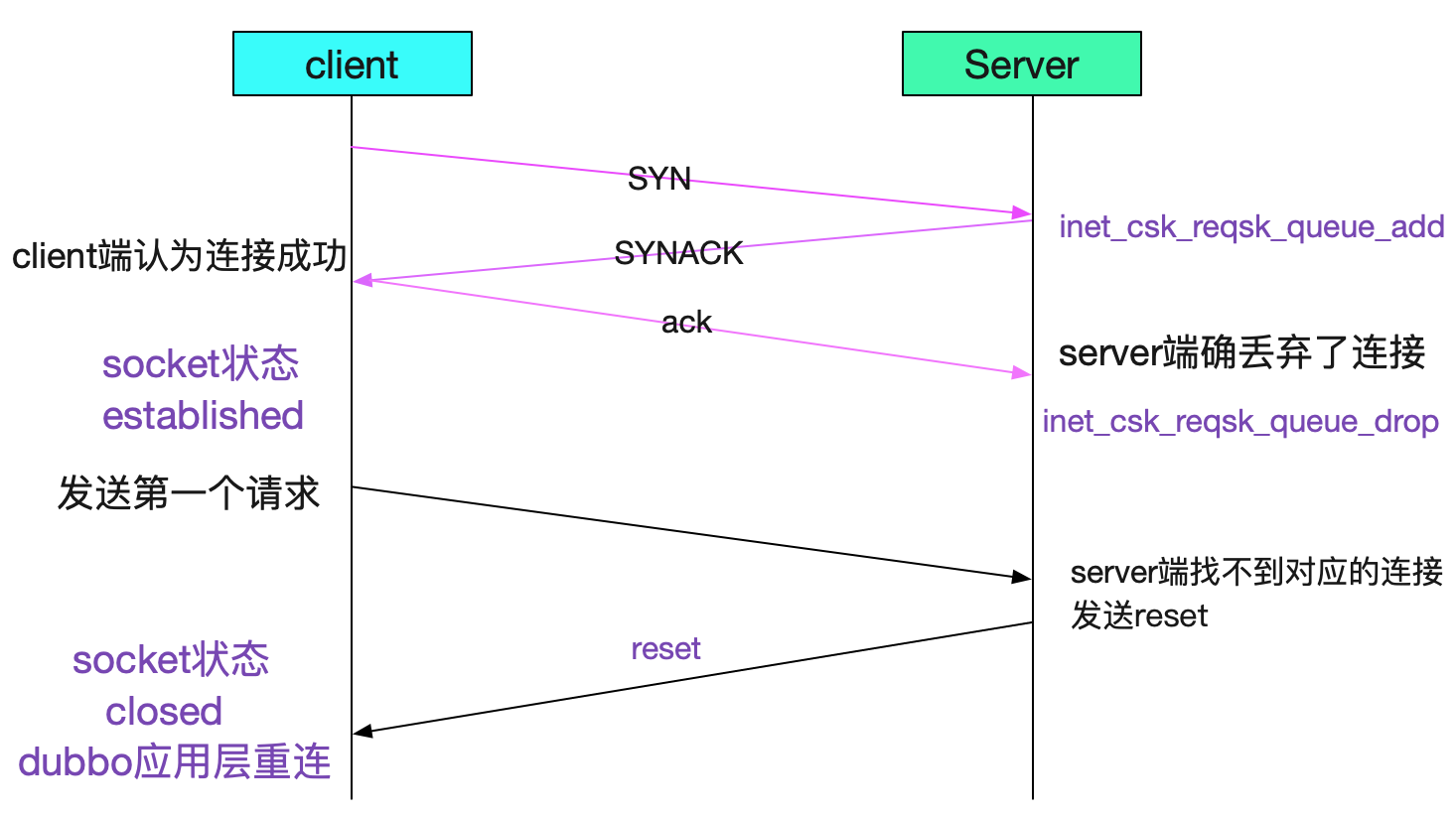
那么,怎么让client端在这种情况下感知呢,我们可以设置一下tcp_abort_on_overflow
echo '1' > tcp_abort_on_overflow
设置后,如下图所示:

当然了,最直接的还是调大backlog!
listen(fd,2048)
echo '2048' > /proc/sys/inet/ipv4/tcp_max_syn_backlog
echo '2048' > /proc/sys/net/core/somaxconn
backlog对半连接队列的影响
这个backlog对半连接队列也有影响,如下代码所示:
/* TW buckets are converted to open requests without
* limitations, they conserve resources and peer is
* evidently real one.
*/
// 在开启SYN cookie的情况下,如果半连接队列长度超过backlog,则发送cookie
// 否则丢弃
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
if (!want_cookie)
goto drop;
}
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
// 在全连接队列满的情况下,如果有young_ack,那么直接丢弃
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
我们在dmesg里面经常看到的
Possible SYN flooding on port 8080
就是由于半连接队列满以后,Kernel发送cookie校验而导致。
总结
TCP作为一个古老而又流行的协议,在演化了几十年后,其设计变的相当复杂。从而在出问题的时候变的难于分析,这时候就要reading the fucking source code!而笔者也正是写这篇博客而详细阅读源码的时候偶然间灵光一闪,找到了最近一个诡异问题的根因。这个诡异问题的分析过程将会在近期写出来分享给大家。
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号