电商数据分析
一、选题的背景
电商是一个伴随着数据而生的行业,由此产生了非常多的电商信息化平台,有物流系统、供应链系统、流量分析平台等。对于零售业电商企业来说,要在未来十年内取得成功,就必须关注以下几个方面:与拥有越来越多权利的消费者建立深入的联系,了解消费者行为的唯一途径就是不断测量和分析数据。通过分析销售数据来了解在线销售业务的消费情况,分析用户消费数据来分析用户的消费行为,帮助企业或个人预测未来的趋势和行为。
二、大数据分析设计方案
字段介绍:
Unnamed: 行号
event_time:下单时间
order_id:订单编号
product_id:产品标号
category_id :类别编号
category_code :类别
brand :品牌
price :价格
user_id :用户编号
age :年龄
sex :性别
local:省份
对店铺的销售情况、销售行为以及人群分层进行分析。
三、数据分析步骤
1.数据源
该数据来源于和鲸社区,共包含564170行数据
2.数据清洗
#导入模块 import pandas as pd import numpy as np #读取数据 f=open('./电子产品销售分析.csv',encoding='utf8') df=pd.read_csv(f) df.head()
#将属性名重命名 #去除无用属性 colNameDict ={ "Unnamed: 0":"行号", "event_time":"下单时间", "order_id":"订单号", "product_id":"产品号", "category_id":"类别编号", "category_code":"类别", "brand":"品牌", "price":"价格", "user_id":"用户编号", "age":"年龄", "sex":"性别", "local":"省份" } df.rename(columns=colNameDict,inplace=True) df.drop(columns=["行号"],inplace=True) df.head()
查看数据类型
df.info()

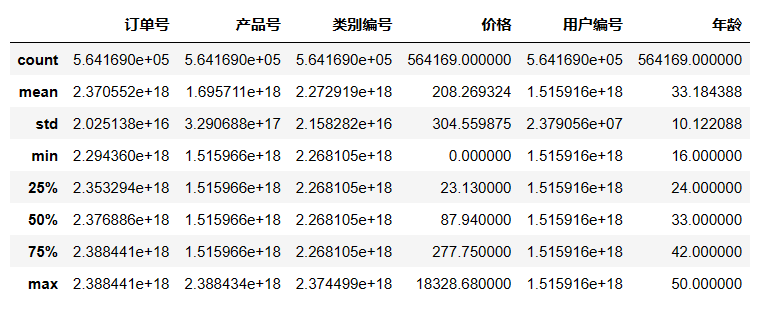
查看数据描述
df.describe()
将数据类型转化并计算时间变量
#数据类型转化 df['下单时间'] = pd.to_datetime(df['下单时间'].str[:19],format="%Y-%m-%d %H:%M:%S") df['下单时间'] = pd.to_datetime(df['下单时间']) #计算时间变量 df['Month']=df['下单时间'].dt.month df['Day'] = df['下单时间'].dt.day df['Dayofweek']=df['下单时间'].dt.dayofweek df['hour']=df['下单时间'].dt.hour df.head()
查看数据是否有缺失
#数据缺失与补充 np.sum(df.isnull())

对缺失数据添加missing
df.fillna('missing').head()
查看是否还存在缺失
df['类别'].fillna('missing',inplace=True) df['品牌'].fillna('missing',inplace=True) np.sum(df.isnull())
去除重复行
#去除重复行 df.duplicated() df.drop_duplicates()
3.数据可视化
对成交金额,消费人事以及订单数量进行分析
import numpy as np
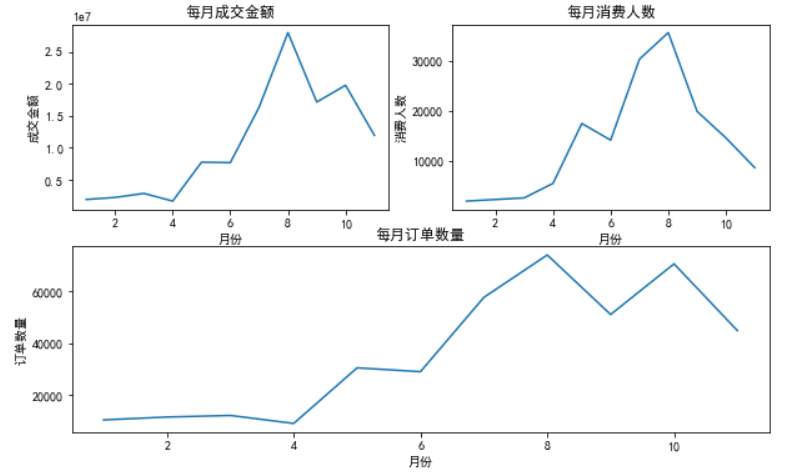
import pandas as pd import matplotlib.pyplot as plt import matplotlib #每月成交金额 plt.rcParams['figure.figsize'] = (10.0, 6.0) # 设置figure_size尺寸 #设置中文字体 plt.rcParams['font.family'] = ['SimHei'] #每月成交金额,包含未成单金额 plt.figure() #绘图函数 def store_plot(data,xlab,ylab,title): plt.plot(data) plt.xlabel(xlab) plt.ylabel(ylab) plt.title(title) axes1 = plt.subplot(2,2,1) store_plot(data=df[df['价格']>0].groupby('Month')['价格'].sum(), xlab='月份', ylab='成交金额', title='每月成交金额') axes1 = plt.subplot(2,2,2) store_plot(data=df[df['价格']>0].groupby('Month')['用户编号'].nunique(), xlab='月份', ylab='消费人数', title='每月消费人数') axes1 = plt.subplot(2,1,2) store_plot(data=df[df['价格']>0].groupby('Month')['订单号'].nunique(), xlab='月份', ylab='订单数量', title='每月订单数量')
#销售情况最好的月份集中在7-9月份,店铺可以在1-4月份减少营业人员,5-11月增加营业人员,应对销售高峰期。
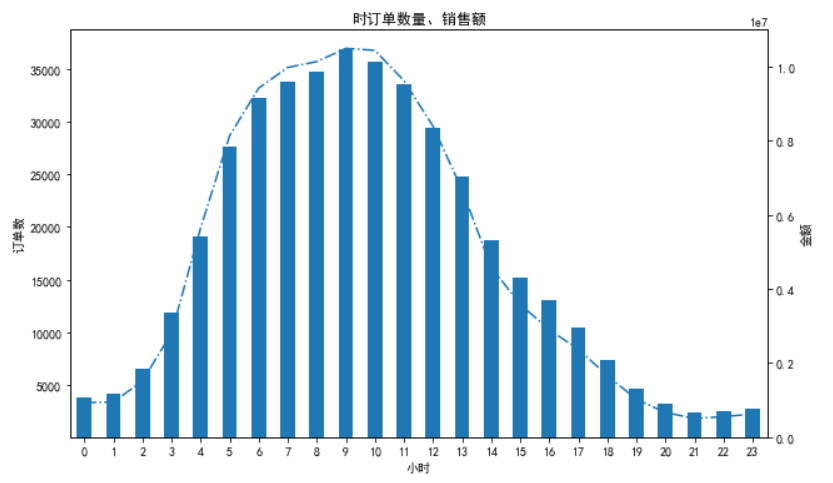
对时订单数量及销售金额分析
fig = plt.figure() ax1 = fig.add_subplot(111) df[df['价格']>0].groupby('hour')['订单号'].nunique().plot(kind='line',linestyle='-.') plt.ylabel('订单数') plt.xlabel('小时') plt.title('时订单数量、销售额') ax2 = ax1.twinx() df[df['价格']>0].groupby('hour')['价格'].sum().plot(kind='bar') plt.ylabel('金额') #订单集中在早晨,6点到12点是消费高峰期,这段时间要注意维持好网站的稳定性。
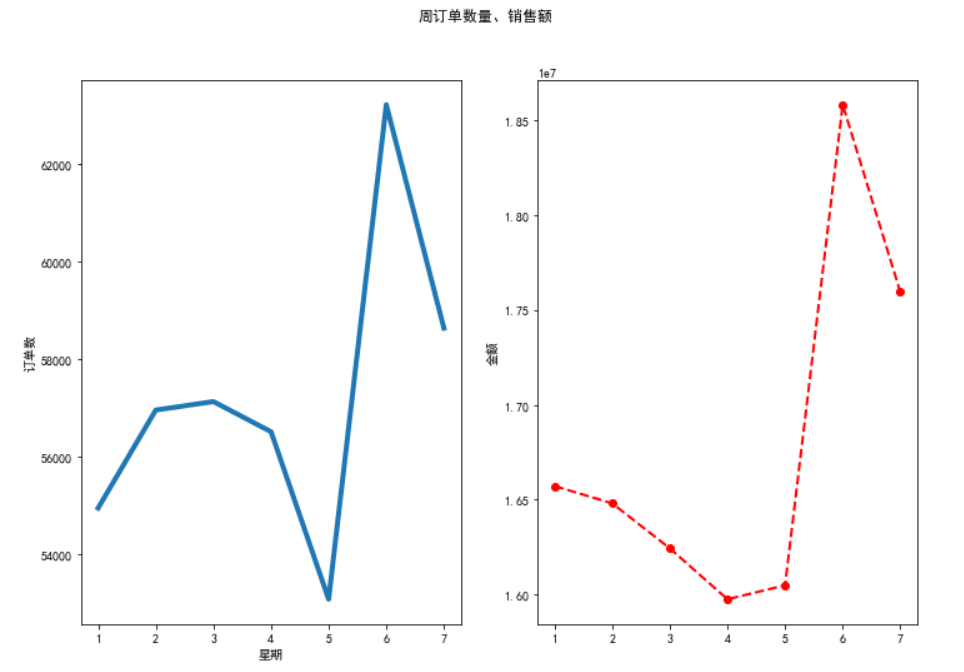
对周订单数量及销售金额分析
#下单时间分布 #星期 x = [1,2,3,4,5,6,7] plt.figure(figsize=(12,8)) plt.suptitle('周订单数量、销售额') axes1 = plt.subplot(1,2,1) y1=df[df['价格']>0].groupby('Dayofweek')['订单号'].nunique() plt.plot(x,y1,label='y',linewidth = 4) plt.xlabel('星期') plt.ylabel('订单数') axes1 = plt.subplot(1,2,2) y2=df[df['价格']>0].groupby('Dayofweek')['价格'].sum() plt.plot(x,y2,label='y1',linewidth = 2, linestyle='--',marker='o',color='r') plt.ylabel('金额')
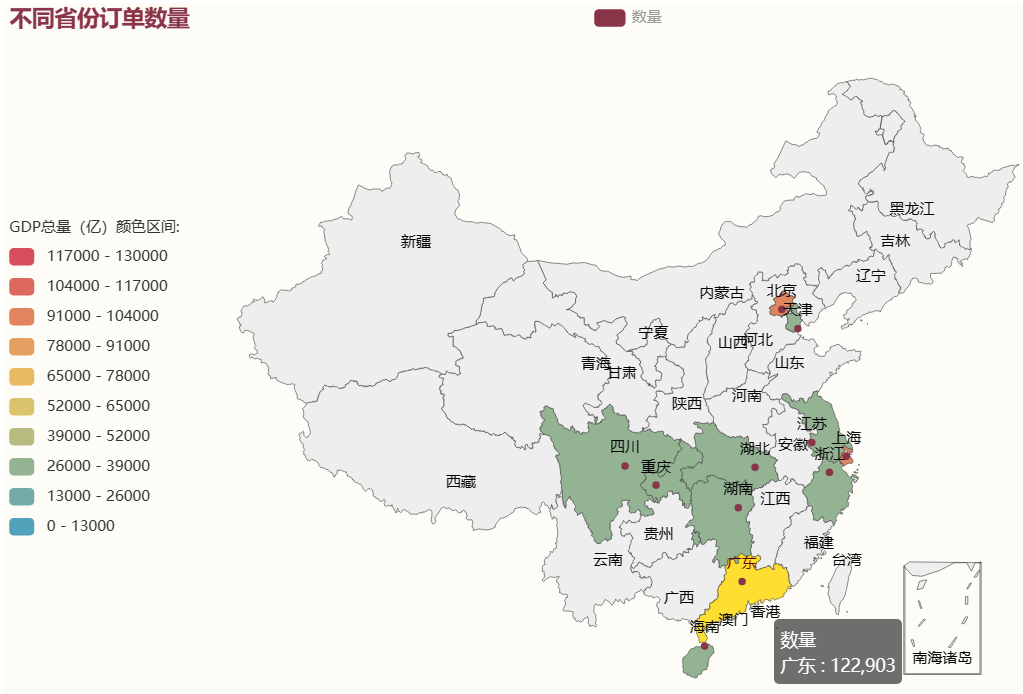
查看不同省份订单数量
from pyecharts.charts import Map from pyecharts import options as opts from pyecharts.globals import ChartType from pyecharts.commons.utils import JsCode from pyecharts.globals import ThemeType #统计省份数量并转化为字典格式 province =dict(df['省份'].value_counts()) list = [[k,v] for k,v in province.items()] #a=print(list) b=[['广东', 122903],['上海', 95347],['北京', 92684], ['湖南', 35178], ['海南', 34478], ['四川', 33847], ['重庆', 32128], ['浙江', 30942], ['江苏', 30214], ['天津', 29558], ['湖北', 26851]] c = ( Map(init_opts=opts.InitOpts(width="1000px", height="600px",theme = ThemeType.ESSOS)) #添加主题ThemeType.DARK .set_global_opts( title_opts=opts.TitleOpts(title="不同省份订单数量"), visualmap_opts=opts.VisualMapOpts( min_=0, max_=130000, range_text = ['GDP总量(亿)颜色区间:', ''], #分区间 is_piecewise=True, #定义图例为分段型,默认为连续的图例 pos_top= "middle", #分段位置 pos_left="left", orient="vertical", split_number=10 #分成10个区间 ) ) .add("数量",data_pair=b,maptype="china") .render("Map.html") )
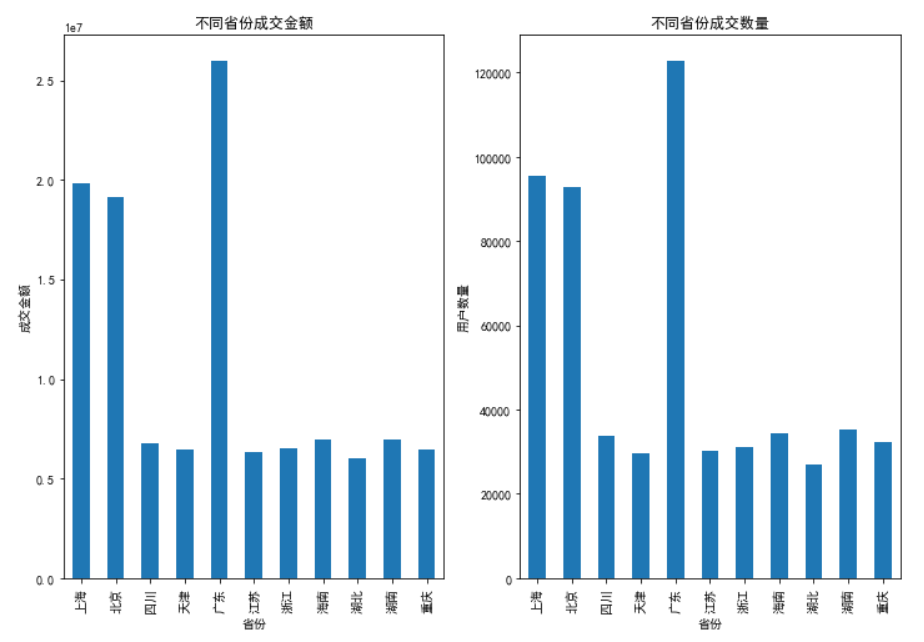
plt.figure(figsize=(12,8)) axes1 = plt.subplot(1,2,1) s=df[df['价格']>0].groupby('省份')['价格'].sum() plt.xlabel('省份') plt.ylabel('成交金额') plt.title('不同省份成交金额') s.plot(kind='bar') axes1 = plt.subplot(1,2,2) s=df[df['价格']>0].groupby('省份')['用户编号'].count() plt.xlabel('省份') plt.ylabel('用户数量') plt.title('不同省份成交数量') s.plot(kind='bar') #1、北上广的用户数量、订单数量、成交金额都稳居前三。 #2、湖南的客户数量最好,但是订单数,客单价仅次于北上广,湖南客户的潜力巨大,需要加大宣传,增加客户数量。
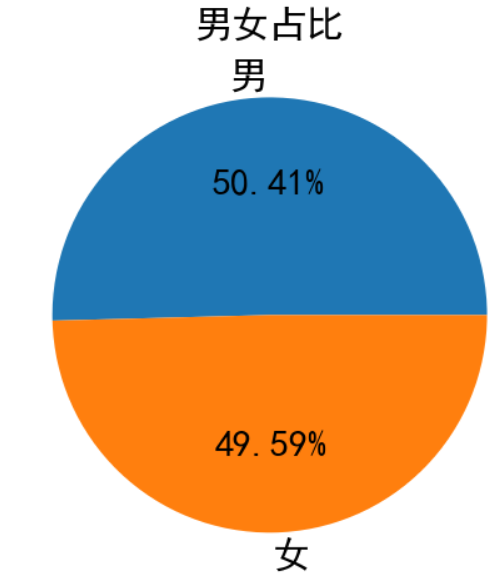
男女购买比例
df_sex = df['性别'].value_counts() df = df[df['价格']>0] plt.figure(figsize=(8,8)) plt.pie(df_sex.values,labels=df_sex.index,autopct='%.2f%%', textprops={'size':30, 'weight':'bold'}, ) plt.title('男女占比',size=30) plt.show() #购买人群男女占比几乎是1:1的情况
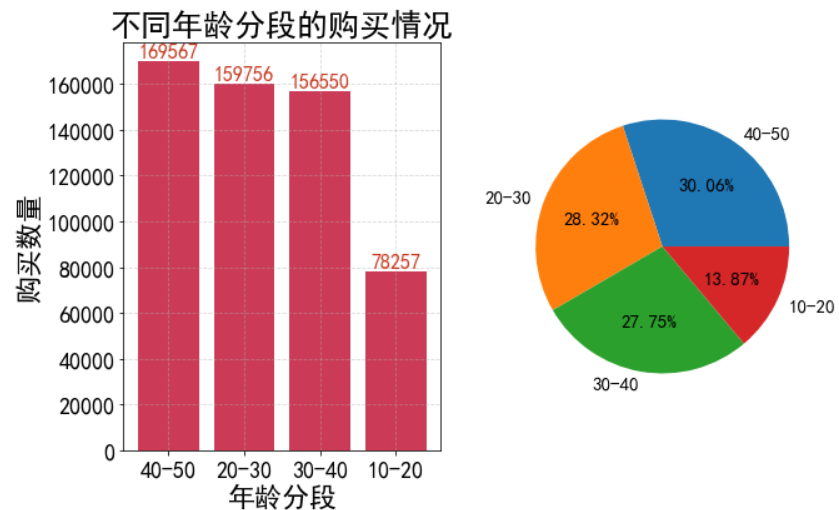
不同年龄段中购买情况
df['年龄'].describe() bins=[10,20,30,40,50] df['age_box'] = pd.cut(df['年龄'],bins,labels=['10-20','20-30','30-40','40-50']) age_box = df['age_box'].value_counts() plt.figure(figsize=(10,6)) axes1 = plt.subplot(1,2,1) plt.title('不同年龄分段的购买情况',size=25) plt.bar(age_box.index,age_box.values ,color='#cb3a56') plt.grid(True, linestyle='--', alpha=0.5) plt.ylabel('购买数量',size=22) plt.xlabel('年龄分段',size=22) plt.xticks(size=18) plt.yticks(size=18) for x,y in zip(age_box.index,age_box.values): plt.text(x,y+500,"%d"%y,ha='center',va='bottom',size=16,color='#c83c23') axes1 = plt.subplot(1,2,2) plt.pie(age_box.values,labels=age_box.index,autopct='%.2f%%', textprops={'size':15, 'weight':'bold'}, ) plt.title('',size=30) plt.show()
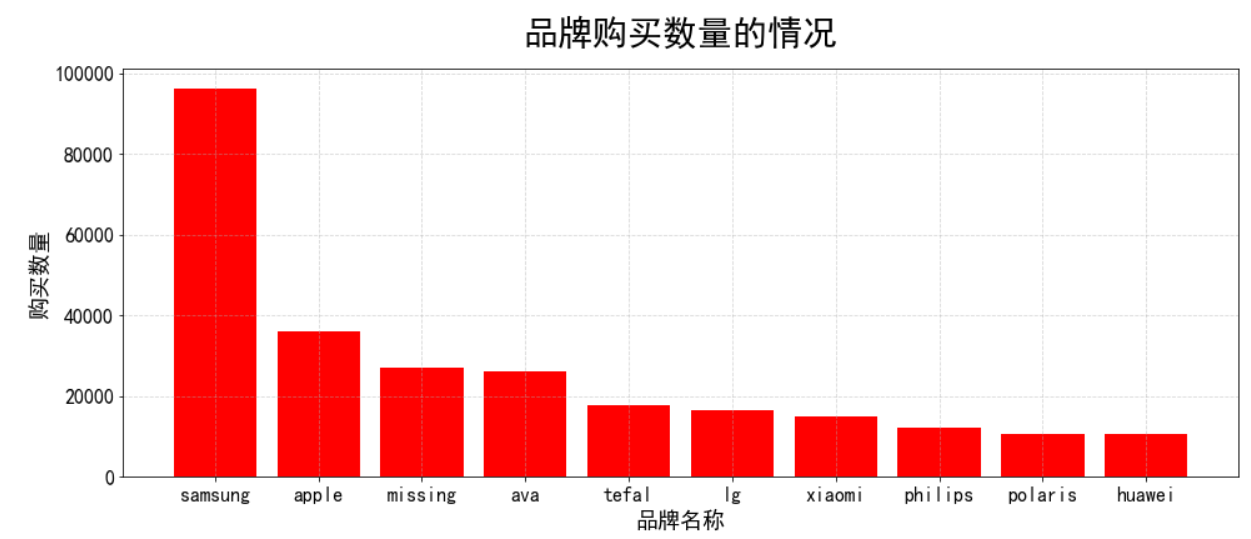
不同品牌购买情况
df_brand = df['品牌'].value_counts().head(10) plt.figure(figsize=(16,6)) plt.bar(df_brand.index,df_brand.values,color='red') plt.grid(True, linestyle='--', alpha=0.5) plt.xticks(size=16) plt.yticks(size=16) plt.xlabel("品牌名称",size=18) plt.ylabel("购买数量",size=18) plt.title('品牌购买数量的情况',size=28,pad=20) plt.show() #可以看到missing占比是相当大,是因为当初在填充缺失值的值,或许可能当初的缺失值填充是有些许问题的, #但是不影响,如果抛开缺失值,也就不看samsung,那比较受欢迎的电子产品是samsung与apple
消费次数与消费金额的关系
plt.figure(figsize=(12,8)) plt.scatter(x=df[df['价格']>0].groupby('用户编号')['订单号'].nunique(), y=df[df['价格']>0].groupby('用户编号')['价格'].sum()) plt.xlabel('消费次数') plt.ylabel('消费金额') plt.title('消费次数与消费金额关系') plt.show() #消费次数和消费金额存在较强的相关性,用户消费次数越大,消费金额越大,可以引导用户多次消费。
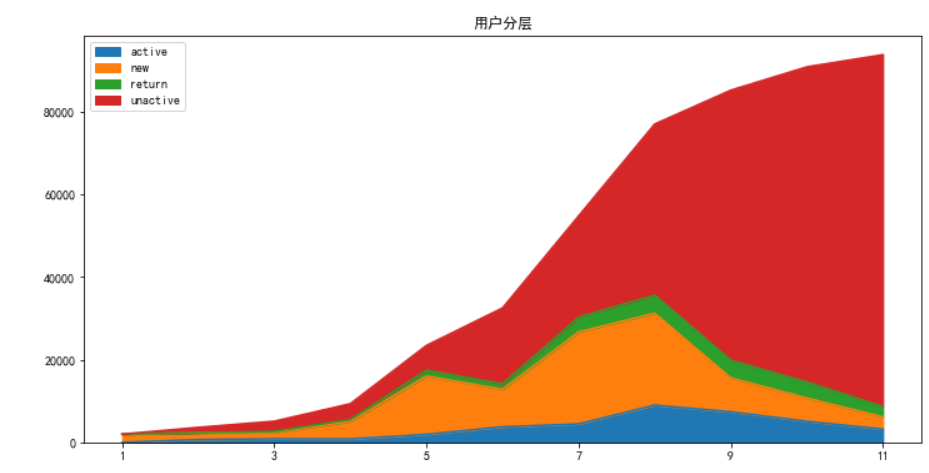
用户情况
pivoted_amount =df[df['价格']>0].pivot_table(index='用户编号', columns='Month', values='价格', aggfunc='mean').fillna(0) columns_month = df['Month'].sort_values().astype('str').unique() pivoted_amount.columns = columns_month pivoted_purchase = pivoted_amount.applymap(lambda x:1 if x>0 else 0) #用户分层 def active_status(data): status =[] for i in range(11): #若本月没有消费 if data[i] ==0: if len(status)>0: if status[i-1]=='unreg': status.append('unreg') else: status.append('unactive') else: status.append('unreg') #若本月消费 else: if len(status)==0: status.append('new') else: if status[i-1]=='unactive': status.append('return') elif status[i-1]=='unreg': status.append('new') else: status.append('active') return pd.Series(status,index=columns_month) pivoted_purchase_status = pivoted_purchase.apply(lambda x:active_status(x),axis=1) purchase_status_counts= pivoted_purchase_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x)) purchase_status_counts.fillna(0).T.plot.area(figsize=(12,6)) plt.title('用户分层') #1、从3月开始,新用户数量逐渐增加,8月份增加最多,8月份以后新用户数量又逐渐减少。 #2、从6月份开始,不活跃用户数逐渐增加,而且增速越来越快。 #3、回流用户数从5月开始增速较快,到7月份开始报纸稳定。 #4、活跃用户数从5月开始大幅增加,7-11月份活跃数量较多,其中8月最多,估计和开学季相关。
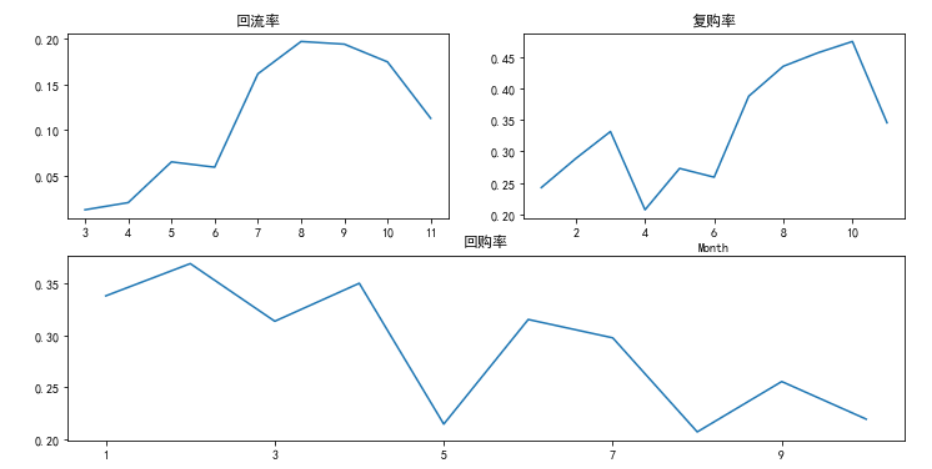
plt.figure() axes1 = plt.subplot(2,2,1) #回流率 return_rate = purchase_status_counts.apply(lambda x:x/x.sum(),axis=1) return_rate.loc['return'].plot(figsize=(14,6)) plt.title('回流率') #回流用户从2月到7月呈增加趋势,四月有所回落,五月开始保持快速增长, #7月初到达顶峰,7月开始回落但依然保持较高的回流率。 #复购率 axes1 = plt.subplot(2,2,2) pivoted_counts = df[df['价格']>0].pivot_table(index='用户编号', columns='Month', values='订单号', aggfunc='nunique').fillna(0) columns_month = df['Month'].sort_values().astype('str').unique() pivoted_counts_transf = pivoted_counts.applymap(lambda x: 1 if x>1 else np.NaN if x==0 else 0) (pivoted_counts_transf.sum()/pivoted_counts_transf.count()).plot(figsize=(12,6)) plt.title('复购率') #复购率3月、5月、10月有三个小高峰,其中10月份复购率最高,从6月开始到10月复购率一直保持增长。 #一直保持较高的复购率。其中三个小高峰估计和清明小长假、五一小长假、十一小长假有关。 #回购率 axes1 = plt.subplot(2,1,2) def purchase_return(data): status = [] for i in range(10): if data[i]==1: if data[i+1]==1: status.append(1) else: status.append(0) else : status.append(np.NaN) status.append(np.NaN) return pd.Series(status,index=columns_month) pivoted_purchase_return = pivoted_purchase.apply(purchase_return,axis=1) (pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize=(12,6)) plt.title('回购率') #回购率从1月到11月总体呈现下降趋势。 #其中3月、5月、10月下降最厉害,估计和清明小长假、五一小长假、十一小长假有关。
完整程序源代码
#导入模块 import pandas as pd import numpy as np #读取数据 f=open('./电子产品销售分析.csv',encoding='utf8') df=pd.read_csv(f) df.head() #将属性名重命名 #去除无用属性 colNameDict ={ "Unnamed: 0":"行号", "event_time":"下单时间", "order_id":"订单号", "product_id":"产品号", "category_id":"类别编号", "category_code":"类别", "brand":"品牌", "price":"价格", "user_id":"用户编号", "age":"年龄", "sex":"性别", "local":"省份" } df.rename(columns=colNameDict,inplace=True) df.drop(columns=["行号"],inplace=True) df.head() df.info() df.describe() #数据类型转化 df['下单时间'] = pd.to_datetime(df['下单时间'].str[:19],format="%Y-%m-%d %H:%M:%S") df['下单时间'] = pd.to_datetime(df['下单时间']) #计算时间变量 df['Month']=df['下单时间'].dt.month df['Day'] = df['下单时间'].dt.day df['Dayofweek']=df['下单时间'].dt.dayofweek df['hour']=df['下单时间'].dt.hour df.head() #数据缺失与补充 np.sum(df.isnull()) df.fillna('missing').head() df['类别'].fillna('missing',inplace=True) df['品牌'].fillna('missing',inplace=True) np.sum(df.isnull()) #去除重复行 df.duplicated() df.drop_duplicates() import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib #每月成交金额 plt.rcParams['figure.figsize'] = (10.0, 6.0) # 设置figure_size尺寸 #设置中文字体 plt.rcParams['font.family'] = ['SimHei'] #每月成交金额,包含未成单金额 plt.figure() #绘图函数 def store_plot(data,xlab,ylab,title): plt.plot(data) plt.xlabel(xlab) plt.ylabel(ylab) plt.title(title) axes1 = plt.subplot(2,2,1) store_plot(data=df[df['价格']>0].groupby('Month')['价格'].sum(), xlab='月份', ylab='成交金额', title='每月成交金额') axes1 = plt.subplot(2,2,2) store_plot(data=df[df['价格']>0].groupby('Month')['用户编号'].nunique(), xlab='月份', ylab='消费人数', title='每月消费人数') axes1 = plt.subplot(2,1,2) store_plot(data=df[df['价格']>0].groupby('Month')['订单号'].nunique(), xlab='月份', ylab='订单数量', title='每月订单数量') #销售情况最好的月份集中在7-9月份,店铺可以在1-4月份减少营业人员,5-11月增加营业人员,应对销售高峰期。 fig = plt.figure() ax1 = fig.add_subplot(111) df[df['价格']>0].groupby('hour')['订单号'].nunique().plot(kind='line',linestyle='-.') plt.ylabel('订单数') plt.xlabel('小时') plt.title('时订单数量、销售额') ax2 = ax1.twinx() df[df['价格']>0].groupby('hour')['价格'].sum().plot(kind='bar') plt.ylabel('金额') #订单集中在早晨,6点到12点是消费高峰期,这段时间要注意维持好网站的稳定性。 #下单时间分布 #星期 x = [1,2,3,4,5,6,7] plt.figure(figsize=(12,8)) plt.suptitle('周订单数量、销售额') axes1 = plt.subplot(1,2,1) y1=df[df['价格']>0].groupby('Dayofweek')['订单号'].nunique() plt.plot(x,y1,label='y',linewidth = 4) plt.xlabel('星期') plt.ylabel('订单数') axes1 = plt.subplot(1,2,2) y2=df[df['价格']>0].groupby('Dayofweek')['价格'].sum() plt.plot(x,y2,label='y1',linewidth = 2, linestyle='--',marker='o',color='r') plt.ylabel('金额') from pyecharts.charts import Map from pyecharts import options as opts from pyecharts.globals import ChartType from pyecharts.commons.utils import JsCode from pyecharts.globals import ThemeType #统计省份数量并转化为字典格式 province =dict(df['省份'].value_counts()) list = [[k,v] for k,v in province.items()] #a=print(list) b=[['广东', 122903],['上海', 95347],['北京', 92684], ['湖南', 35178], ['海南', 34478], ['四川', 33847], ['重庆', 32128], ['浙江', 30942], ['江苏', 30214], ['天津', 29558], ['湖北', 26851]] c = ( Map(init_opts=opts.InitOpts(width="1000px", height="600px",theme = ThemeType.ESSOS)) #添加主题ThemeType.DARK .set_global_opts( title_opts=opts.TitleOpts(title="不同省份订单数量"), visualmap_opts=opts.VisualMapOpts( min_=0, max_=130000, range_text = ['GDP总量(亿)颜色区间:', ''], #分区间 is_piecewise=True, #定义图例为分段型,默认为连续的图例 pos_top= "middle", #分段位置 pos_left="left", orient="vertical", split_number=10 #分成10个区间 ) ) .add("数量",data_pair=b,maptype="china") .render("Map.html") ) plt.figure(figsize=(12,8)) axes1 = plt.subplot(1,2,1) s=df[df['价格']>0].groupby('省份')['价格'].sum() plt.xlabel('省份') plt.ylabel('成交金额') plt.title('不同省份成交金额') s.plot(kind='bar') axes1 = plt.subplot(1,2,2) s=df[df['价格']>0].groupby('省份')['用户编号'].count() plt.xlabel('省份') plt.ylabel('用户数量') plt.title('不同省份成交数量') s.plot(kind='bar') #1、北上广的用户数量、订单数量、成交金额都稳居前三。 #2、湖南的客户数量最好,但是订单数,客单价仅次于北上广,湖南客户的潜力巨大,需要加大宣传,增加客户数量。 df_sex = df['性别'].value_counts() df = df[df['价格']>0] plt.figure(figsize=(8,8)) plt.pie(df_sex.values,labels=df_sex.index,autopct='%.2f%%', textprops={'size':30, 'weight':'bold'}, ) plt.title('男女占比',size=30) plt.show() #购买人群男女占比几乎是1:1的情况 df['年龄'].describe() bins=[10,20,30,40,50] df['age_box'] = pd.cut(df['年龄'],bins,labels=['10-20','20-30','30-40','40-50']) age_box = df['age_box'].value_counts() plt.figure(figsize=(10,6)) axes1 = plt.subplot(1,2,1) plt.title('不同年龄分段的购买情况',size=25) plt.bar(age_box.index,age_box.values ,color='#cb3a56') plt.grid(True, linestyle='--', alpha=0.5) plt.ylabel('购买数量',size=22) plt.xlabel('年龄分段',size=22) plt.xticks(size=18) plt.yticks(size=18) for x,y in zip(age_box.index,age_box.values): plt.text(x,y+500,"%d"%y,ha='center',va='bottom',size=16,color='#c83c23') axes1 = plt.subplot(1,2,2) plt.pie(age_box.values,labels=age_box.index,autopct='%.2f%%', textprops={'size':15, 'weight':'bold'}, ) plt.title('',size=30) plt.show() df_brand = df['品牌'].value_counts().head(10) plt.figure(figsize=(16,6)) plt.bar(df_brand.index,df_brand.values,color='red') plt.grid(True, linestyle='--', alpha=0.5) plt.xticks(size=16) plt.yticks(size=16) plt.xlabel("品牌名称",size=18) plt.ylabel("购买数量",size=18) plt.title('品牌购买数量的情况',size=28,pad=20) plt.show() #可以看到missing占比是相当大,是因为当初在填充缺失值的值,或许可能当初的缺失值填充是有些许问题的, #但是不影响,如果抛开缺失值,也就不看samsung,那比较受欢迎的电子产品是samsung与apple #消费次数与消费金额的关系 plt.figure(figsize=(12,8)) plt.scatter(x=df[df['价格']>0].groupby('用户编号')['订单号'].nunique(), y=df[df['价格']>0].groupby('用户编号')['价格'].sum()) plt.xlabel('消费次数') plt.ylabel('消费金额') plt.title('消费次数与消费金额关系') plt.show() #消费次数和消费金额存在较强的相关性,用户消费次数越大,消费金额越大,可以引导用户多次消费。 pivoted_amount =df[df['价格']>0].pivot_table(index='用户编号', columns='Month', values='价格', aggfunc='mean').fillna(0) columns_month = df['Month'].sort_values().astype('str').unique() pivoted_amount.columns = columns_month pivoted_purchase = pivoted_amount.applymap(lambda x:1 if x>0 else 0) #用户分层 def active_status(data): status =[] for i in range(11): #若本月没有消费 if data[i] ==0: if len(status)>0: if status[i-1]=='unreg': status.append('unreg') else: status.append('unactive') else: status.append('unreg') #若本月消费 else: if len(status)==0: status.append('new') else: if status[i-1]=='unactive': status.append('return') elif status[i-1]=='unreg': status.append('new') else: status.append('active') return pd.Series(status,index=columns_month) pivoted_purchase_status = pivoted_purchase.apply(lambda x:active_status(x),axis=1) purchase_status_counts= pivoted_purchase_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x)) purchase_status_counts.fillna(0).T.plot.area(figsize=(12,6)) plt.title('用户分层') #1、从3月开始,新用户数量逐渐增加,8月份增加最多,8月份以后新用户数量又逐渐减少。 #2、从6月份开始,不活跃用户数逐渐增加,而且增速越来越快。 #3、回流用户数从5月开始增速较快,到7月份开始报纸稳定。 #4、活跃用户数从5月开始大幅增加,7-11月份活跃数量较多,其中8月最多,估计和开学季相关。 plt.figure() axes1 = plt.subplot(2,2,1) #回流率 return_rate = purchase_status_counts.apply(lambda x:x/x.sum(),axis=1) return_rate.loc['return'].plot(figsize=(14,6)) plt.title('回流率') #回流用户从2月到7月呈增加趋势,四月有所回落,五月开始保持快速增长, #7月初到达顶峰,7月开始回落但依然保持较高的回流率。 #复购率 axes1 = plt.subplot(2,2,2) pivoted_counts = df[df['价格']>0].pivot_table(index='用户编号', columns='Month', values='订单号', aggfunc='nunique').fillna(0) columns_month = df['Month'].sort_values().astype('str').unique() pivoted_counts_transf = pivoted_counts.applymap(lambda x: 1 if x>1 else np.NaN if x==0 else 0) (pivoted_counts_transf.sum()/pivoted_counts_transf.count()).plot(figsize=(12,6)) plt.title('复购率') #复购率3月、5月、10月有三个小高峰,其中10月份复购率最高,从6月开始到10月复购率一直保持增长。 #一直保持较高的复购率。其中三个小高峰估计和清明小长假、五一小长假、十一小长假有关。 #回购率 axes1 = plt.subplot(2,1,2) def purchase_return(data): status = [] for i in range(10): if data[i]==1: if data[i+1]==1: status.append(1) else: status.append(0) else : status.append(np.NaN) status.append(np.NaN) return pd.Series(status,index=columns_month) pivoted_purchase_return = pivoted_purchase.apply(purchase_return,axis=1) (pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize=(12,6)) plt.title('回购率') #回购率从1月到11月总体呈现下降趋势。 #其中3月、5月、10月下降最厉害,估计和清明小长假、五一小长假、十一小长假有关。
四、总结
销售情况最好的月份集中在7-9月份,店铺可以在1-4月份减少营业人员,5-11月增加营业人员,应对销售高峰期。在早晨,6点到12点是消费高峰期,这段时间要注意维持好网站的稳定性。湖南的客户数量最好,但是订单数,客单价仅次于北上广,湖南客户的潜力巨大,需要加大宣传,增加客户数量。比较受欢迎的电子产品是samsung与apple,可以多加引进该类产品。消费次数和消费金额存在较强的相关性,用户消费次数越大,消费金额越大,可以引导用户多次消费。复购率3月、5月、10月有三个小高峰,其中10月份复购率最高需要备好商品。
做完本次大作业不仅是对往期学习的巩固和加深,更是一次“温故知新”的过程,对现有知识又获得了新的认识,并深刻感受到Python简洁却强大、简单却专业的强大魅力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号