

Hadoop伪分布式安装
大数据技术与应用实验作业
实验名称:Hadoop伪分布式安装
一、实验目的
1、了解Hadoop的3种运行模式
2、熟练掌握Hadoop伪分布模式安装流程
3、培养独立完成Hadoop伪分布安装的能力
二、实验过程
1. 创建一个用户,名为zhangyu,并为此用户创建home目录,此时会默认创建一个与zhangyu同名的用户组。
sudo useradd -d /home/zhangyu -m zhangyu
为zhangyu用户设置密码,执行下面的语句
sudo passwd zhangyu
将zhangyu用户的权限,提升到sudo超级用户级别
sudo usermod -G sudo zhangyu
后续操作,我们需要切换到zhangyu用户下来进行操作。
su - zhangyu
图1
2.首先来配置SSH免密码登陆
SSH免密码登陆需要在服务器执行以下命令,生成公钥和私钥对
ssh-keygen -t rsa
此时会有多处提醒输入在冒号后输入文本,这里主要是要求输入ssh密码以及密码的放置位置。在这里,只需要使用默认值,按回车即可。
图2
此时ssh公钥和私钥已经生成完毕,且放置在~/.ssh目录下。切换到~/.ssh目录下
cd ~/.ssh
可以看到~/.ssh目录下的文件
zhangyu@b6b1577cfbc8:~/.ssh$ ll
下面在~/.ssh目录下,创建一个空文本,名为authorized_keys
touch ~/.ssh/authorized_keys
将存储公钥文件的id_rsa.pub里的内容,追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
图3
下面执行ssh localhost测试ssh配置是否正确
ssh localhost
第一次使用ssh访问,会提醒是否继续连接,输入“yes"继续进行,执行完以后退出,后续再执行ssh localhost时,就不用输入密码了
图4
3.下面首先来创建两个目录,用于存放安装程序及数据。
sudo mkdir /apps
sudo mkdir /data
并为/apps和/data目录切换所属的用户为zhangyu及用户组为zhangyu
sudo chown -R zhangyu:zhangyu /apps
sudo chown -R zhangyu:zhangyu /data
两个目录的作用分别为:/apps目录用来存放安装的框架,/data目录用来存放临时数据、HDFS数据、程序代码或脚本。
切换到根目录下,执行 ls -l 命令
cd /
ls -l
可以看到根目录下/apps和/data目录所属用户及用户组已切换为zhangyu:zhangyu
图5
图6
4.配置HDFS。
创建/data/hadoop1目录,用来存放相关安装工具,如jdk安装包jdk-7u75-linux-x64.tar.gz及hadoop安装包hadoop-2.6.0-cdh5.4.5.tar.gz。
mkdir -p /data/hadoop1
切换目录到/data/hadoop1目录,使用wget命令,下载所需的hadoop安装包jdk-7u75-linux-x64.tar.gz及hadoop-2.6.0-cdh5.4.5.tar.gz。
cd /data/hadoop1
wget http://192.168.1.150:60000/allfiles/hadoop1/jdk-7u75-linux-x64.tar.gz
wget http://192.168.1.150:60000/allfiles/hadoop1/hadoop-2.6.0-cdh5.4.5.tar.gz
图7
图8
5.安装jdk。将/data/hadoop1目录下jdk-7u75-linux-x64.tar.gz 解压缩到/apps目录下。
tar -xzvf /data/hadoop1/jdk-7u75-linux-x64.tar.gz -C /apps
图9
其中,tar -xzvf 对文件进行解压缩,-C 指定解压后,将文件放到/apps目录下。
切换到/apps目录下,我们可以看到目录下内容如下:
cd /apps/
ls -l
下面将jdk1.7.0_75目录重命名为java,执行:
mv /apps/jdk1.7.0_75/ /apps/java
图10
6.下面来修改环境变量:系统环境变量或用户环境变量。我们在这里修改用户环境变量。
sudo vim ~/.bashrc
图11
输入上面的命令,打开存储环境变量的文件。空几行,将java的环境变量,追加进用户环境变量中。
#javaexport JAVA_HOME=/apps/javaexport PATH=$JAVA_HOME/bin:$PATH
图12
输入Esc, 进入vim命令模式,输入 :wq !进行保存。
图13
让环境变量生效。
图14
source ~/.bashrc
图15
执行source命令,让java环境变量生效。执行完毕后,可以输入java,来测试环境变量是否配置正确。如果出现下面界面,则正常运行。
java
图16
图17
7.下面安装hadoop,切换到/data/hadoop1目录下,将hadoop-2.6.0-cdh5.4.5.tar.gz解压缩到/apps目录下。
cd /data/hadoop1
tar -xzvf /data/hadoop1/hadoop-2.6.0-cdh5.4.5.tar.gz -C /apps/
图18
为了便于操作,我们也将hadoop-2.6.0-cdh5.4.5重命名为hadoop。
mv /apps/hadoop-2.6.0-cdh5.4.5/ /apps/hadoop
图19
8.修改用户环境变量,将hadoop的路径添加到path中。先打开用户环境变量文件。
sudo vim ~/.bashrc
将以下内容追加到环境变量~/.bashrc文件中。
#hadoopexport HADOOP_HOME=/apps/hadoopexport PATH=$HADOOP_HOME/bin:$PATH
图20
让环境变量生效。
source ~/.bashrc
图21
验证hadoop环境变量配置是否正常
hadoop version
图22
9.下面来修改hadoop本身相关的配置。首先切换到hadoop配置目录下。
cd /apps/hadoop/etc/hadoop
图23
10.输入vim /apps/hadoop/etc/hadoop/hadoop-env.sh,打开hadoop-env.sh配置文件。
vim /apps/hadoop/etc/hadoop/hadoop-env.sh
图24
将下面JAVA_HOME追加到hadoop-env.sh文件中。
export JAVA_HOME=/apps/java
图25
11.输入vim /apps/hadoop/etc/hadoop/core-site.xml,打开core-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/core-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
图26
这里有两项配置:
一项是hadoop.tmp.dir,配置hadoop处理过程中,临时文件的存储位置。这里的目录/data/tmp/hadoop/tmp需要提前创建。
mkdir -p /data/tmp/hadoop/tmp
图27
另一项是fs.defaultFS,配置hadoop HDFS文件系统的地址。
12.输入vim /apps/hadoop/etc/hadoop/hdfs-site.xml,打开hdfs-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/hdfs-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/tmp/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/tmp/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
图28
配置项说明:
dfs.namenode.name.dir,配置元数据信息存储位置;
dfs.datanode.data.dir,配置具体数据存储位置;
dfs.replication,配置每个数据库备份数,由于目前我们使用1台节点,所以,设置为1,如果设置为2的话,运行会报错。
dfs.permissions.enabled,配置hdfs是否启用权限认证
另外/data/tmp/hadoop/hdfs路径,需要提前创建,所以我们需要执行
mkdir -p /data/tmp/hadoop/hdfs
图29
13.输入vim /apps/hadoop/etc/hadoop/slaves,打开slaves配置文件。
vim /apps/hadoop/etc/hadoop/slaves
将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,所以slaves文件内容为:
localhost
图30
图31
14.下面格式化HDFS文件系统。执行:
hadoop namenode -format
图32
15.切换目录到/apps/hadoop/sbin目录下。
cd /apps/hadoop/sbin/
图33
16.启动hadoop的hdfs相关进程。
./start-dfs.sh
这里只会启动HDFS相关进程。
图34
17.输入jps查看HDFS相关进程是否已经启动。
jps
图35
我们可以看到相关进程,都已经启动。
18.下面可以再进一步验证HDFS运行状态。先在HDFS上创建一个目录。
hadoop fs -mkdir /myhadoop1
图36
19.执行下面命令,查看目录是否创建成功。
hadoop fs -ls -R /
图37
以上,便是HDFS安装过程。
20.下面来配置MapReduce相关配置。再次切换到hadoop配置文件目录
cd /apps/hadoop/etc/hadoop
图38
21.下面将mapreduce的配置文件mapred-site.xml.template,重命名为mapred-site.xml。
mv /apps/hadoop/etc/hadoop/mapred-site.xml.template /apps/hadoop/etc/hadoop/mapred-site.xml
图39
22.输入vim /apps/hadoop/etc/hadoop/mapred-site.xml,打开mapred-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/mapred-site.xml
将mapreduce相关配置,添加到<configuration>标签之间。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
图40
这里指定mapreduce任务处理所使用的框架。
23.输入vim /apps/hadoop/etc/hadoop/yarn-site.xml,打开yarn-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/yarn-site.xml
将yarn相关配置,添加到<configuration>标签之间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
图41
这里的配置是指定所用服务,默认为空。
24.下面来启动计算层面相关进程,切换到hadoop启动目录。
cd /apps/hadoop/sbin/
图42
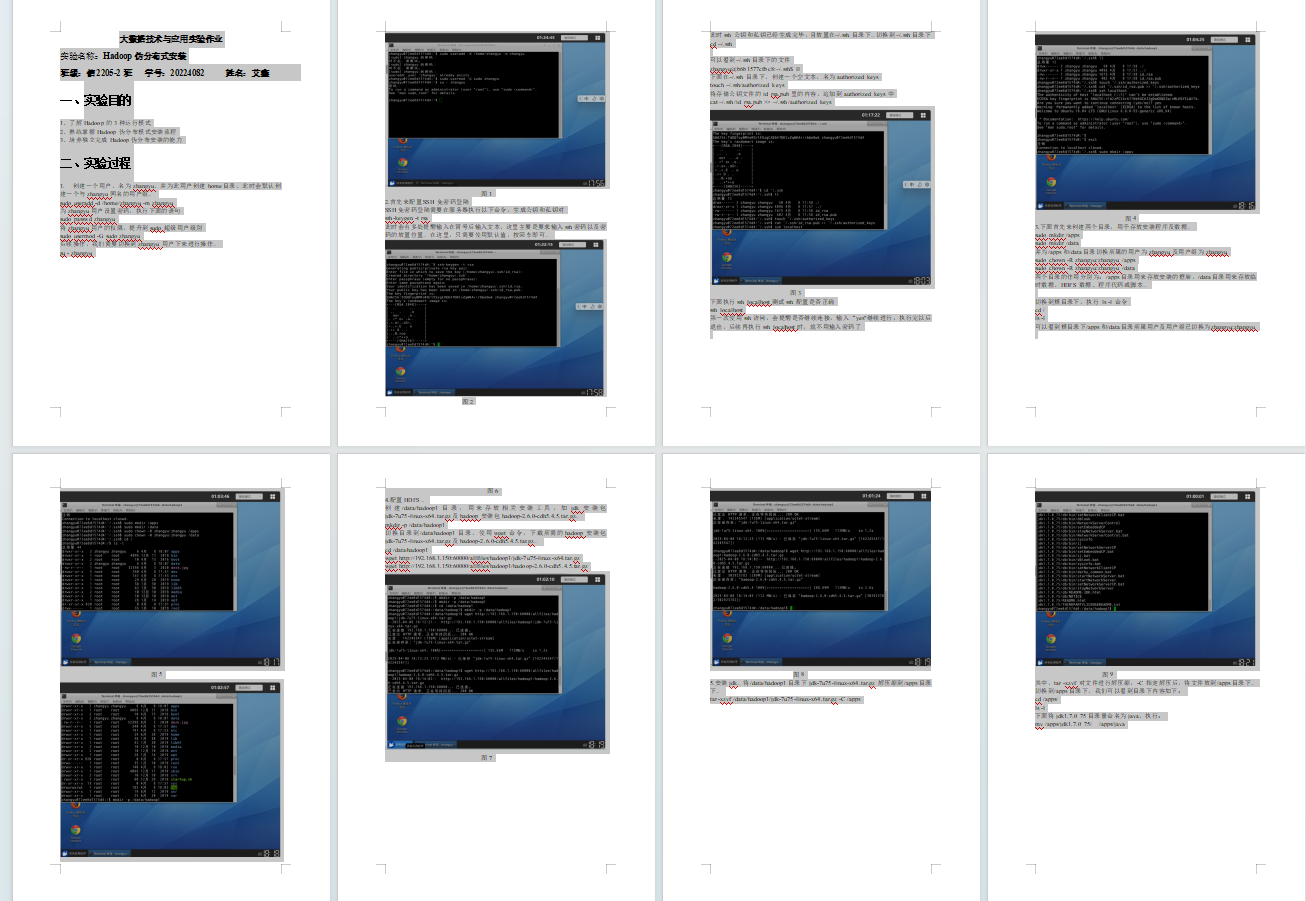
25.执行命令,启动yarn。
./start-yarn.sh
图43
26.输入jps,查看当前运行的进程。
图44
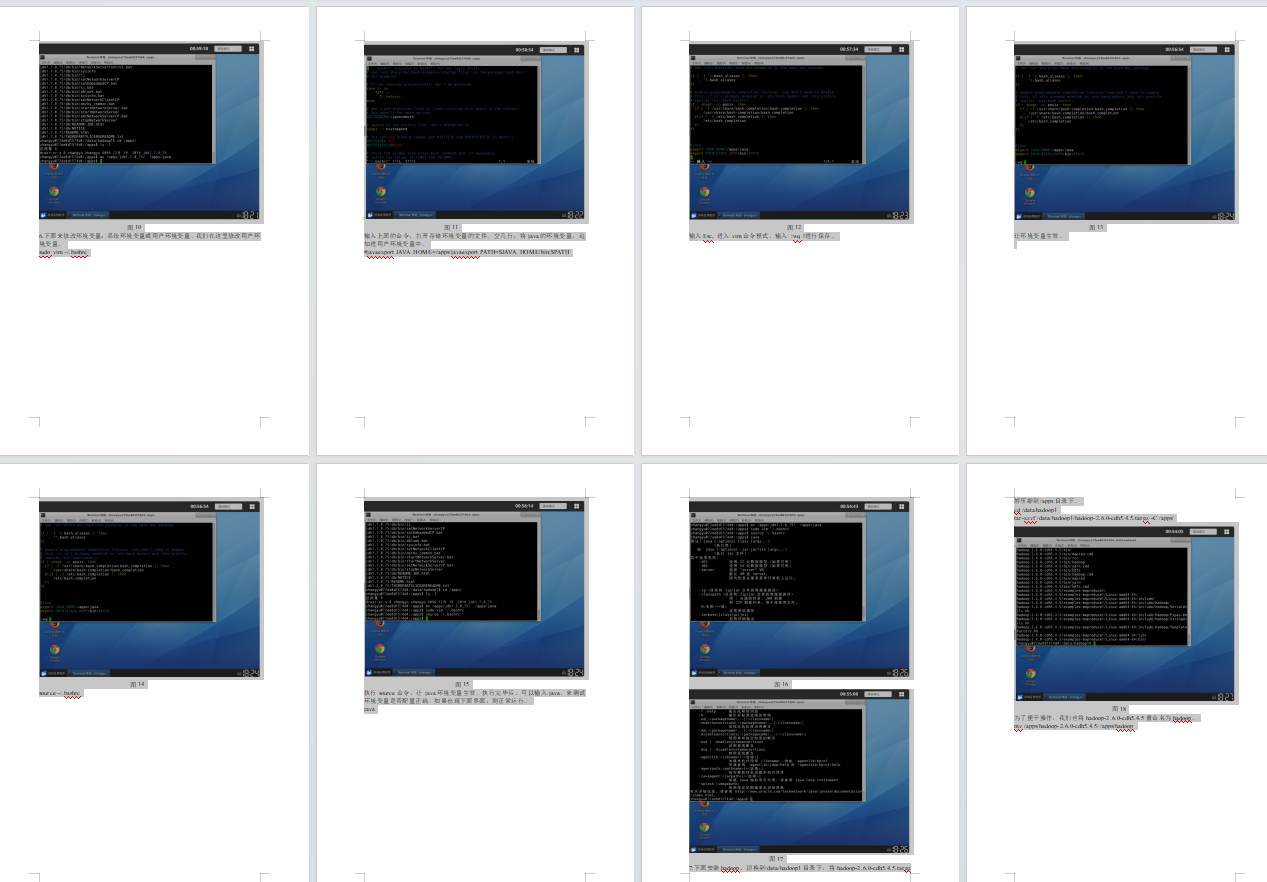
27.执行测试。
切换到/apps/hadoop/share/hadoop/mapreduce目录下。
cd /apps/hadoop/share/hadoop/mapreduce
图45
然后,在该目录下跑一个mapreduce程序,来检测一下hadoop是否能正常运行。
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.4.5.jar pi 3 3
这个程序是计算数学中的pi值。当然暂时先不用考虑数据的准确性。当你看到下面流程的时候,表示程序已正常运行,hadoop环境也是没问题的。(这里我已经跑完了但是要在截图的时候一下子卡顿了我尝试了好多次都是没有网络,重启后数据就没有了,所以这里我只放了相应平台的截图,但是我验证的结果和这个是相符的,每个步骤也都是正确的没有问题)
图46
至此,Hadoop 伪分布模式已经安装完成!
三、实验心得

存放位置:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号