
常见的激活函数
1,Sigmoid
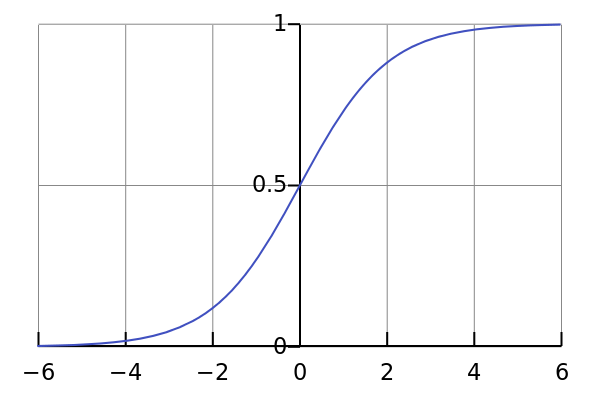
sigmoid 函数映射之后取值范围为(0,1)
tanh函数映射之后取值范围(-1,1)
Relu函数映射之后取值范围(0,..)大宇等于0
Sigmoid函数的特点是会把输出限定在0~1之间,如果是非常大的负数,输出就是0,如果是非常大的正数,输出就是1,这样使得数据在传递过程中不容易发散。
Sigmod有两个主要缺点,一是Sigmoid容易过饱和,丢失梯度。从Sigmoid的示意图上可以看到,神经元的活跃度在0和1处饱和,梯度接近于0,这样在反向传播时,很容易出现梯度消失的情况,导致训练无法完整;二是Sigmoid的输出均值不是0,基于这两个缺点,SIgmoid使用越来越少了。
2. tanh
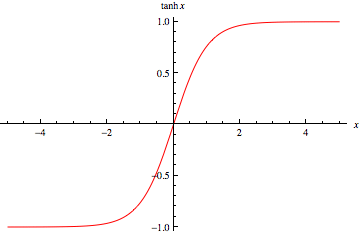
tanh是Sigmoid函数的变形,tanh的均值是0,在实际应用中有比Sigmoid更好的效果。
3. ReLU
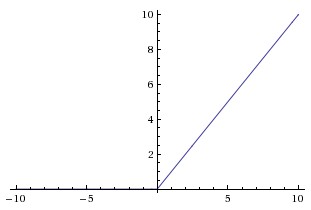
ReLU是近来比较流行的激活函数,当输入信号小于0时,输出为0;当输入信号大于0时,输出等于输入。
ReLU的优点:
1. ReLU是部分线性的,并且不会出现过饱和的现象,使用ReLU得到的随机梯度下降法(SGD)的收敛速度比Sigmodi和tanh都快。
2. ReLU只需要一个阈值就可以得到激活值,不需要像Sigmoid一样需要复杂的指数运算。
ReLU的缺点:
在训练的过程中,ReLU神经元比价脆弱容易失去作用。例如当ReLU神经元接收到一个非常大的的梯度数据流之后,这个神经元有可能再也不会对任何输入的数据有反映了,所以在训练的时候要设置一个较小的合适的学习率参数。
4. Leaky-ReLU
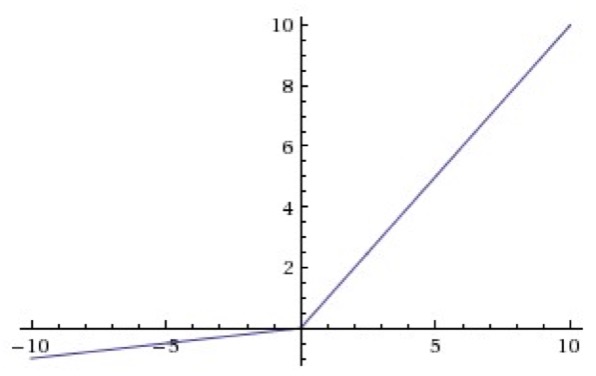
相比ReLU,Leaky-ReLU在输入为负数时引入了一个很小的常数,如0.01,这个小的常数修正了数据分布,保留了一些负轴的值,在Leaky-ReLU中,这个常数通常需要通过先验知识手动赋值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号